Resource Hub
.png)



AI training checkpoint writes to cloud object storage incur 30–40 ms of latency per operation and trigger S3 throttling at scale. This guide explains the root causes, surveys every major architectural approach, and describes the write-back caching architecture that eliminates the problem.

Unlock the full performance of your AI/ML infrastructure on Oracle Cloud Infrastructure (OCI).
Join Oracle's Master Principal Cloud Architect Xinghong He and Alluxio's VP of Technology Bin Fan for an in-depth technical session exploring how modern tiered caching, optimized storage integration, and smart deployment choices can deliver sub-millisecond latency and up to 5× faster data access on OCI — at scale.

Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading

In this talk, Eric Wang, Senior Staff Software Engineer introduces Uber’s open-source generative end-to-end ML lifecycle management platform: Michelangelo.


In this talk, Bin Fan, VP of Technology at Alluxio, explores how to enable efficient data access across distributed GPU infrastructure, achieving low-latency performance for feature stores and RAG workloads.

Hear from Zongheng Yang, Co-Creator of SkyPilot, as he explores how to simplify AI deployment across clouds and on-premises infrastructure with automated resource provisioning and cost optimization.

Cloud object storage like S3 is the backbone of modern data platforms — cost-efficient, durable, and massively scalable. But many AI workloads demand more: sub-millisecond response times, append and update support, and the ability to seamlessly support AI workloads as they scale across clouds and on-premises datacenters.
Alluxio turbo-charges your existing object storage, giving you the speed and efficiency required for next-generation AI workloads — without giving up the scale, durability, and economics of S3.

This white paper presents the Alluxio architecture, a cloud-native Data Acceleration Layer built to bridge the gap between high-performance GPU computing and distributed cloud storage. Alluxio addresses the critical I/O and data-mobility challenges faced by modern AI infrastructure, where compute performance has far surpassed data access capabilities.
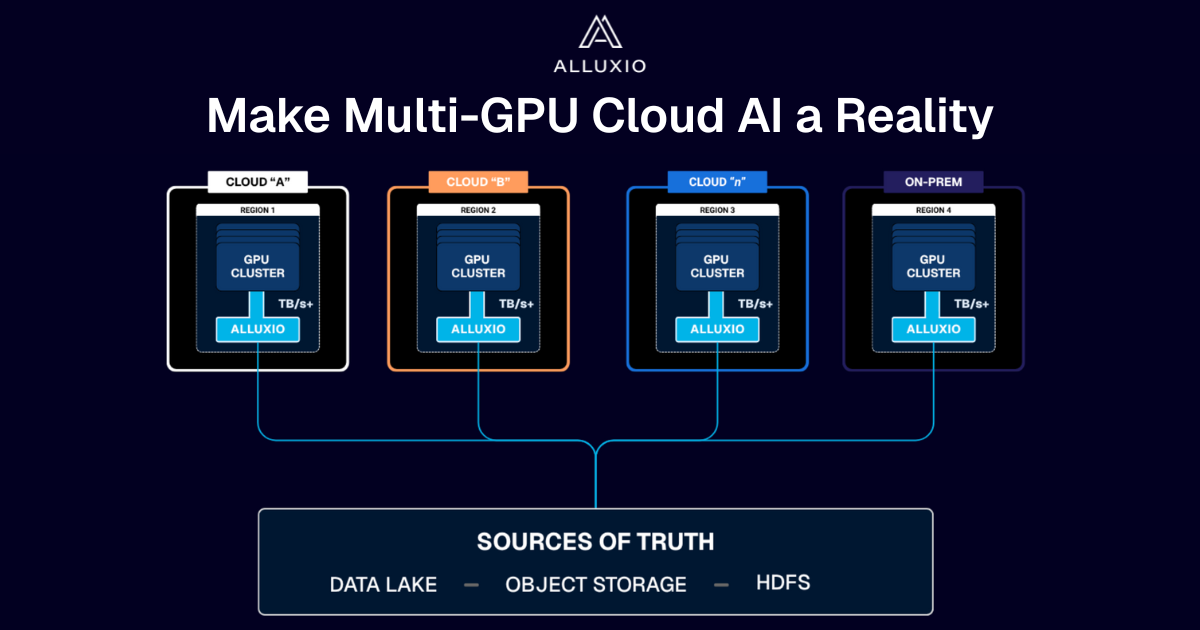
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver.
What slows you down isn’t GPUs, it’s data.

In this on-demand video, Jingwen Ouyang, senior product manager of Alluxio explores how to augment — rather than replace — S3 with a tiered architecture that restores sub-millisecond performance, richer semantics, and high throughput.

In this session, Pratik Mishra delivers insights on architecting scalable, deployable, and resilient AI infrastructure at scale. His discussion on fault tolerance, checkpoint optimization, and the democratization of AI compute through AMD's open ecosystem resonated strongly with the challenges teams face in production ML deployments.

In this talk, Bin Fan, VP of Technology at Alluxio, presents on building tiered architectures that bring sub-millisecond latency to S3-based workloads. The comparison showing Alluxio's 45x performance improvement over S3 Standard and 5x over S3 Express One Zone demonstrated the critical role the performance & caching layer plays in modern AI infrastructure.

In this talk, Greg Lindstrom shared how Blackout Power Trading achieved double-digit millisecond offline feature store performance using Alluxio, a game-changer for real-time power trading where every millisecond counts. The 60x latency reduction for inference queries was particularly impressive.



Blackout Power Trading, a private capital commodity trading fund specializing in North American power markets, leverages Alluxio's low-latency distributed caching platform to achieve multi-join double-digit millisecond latency offline feature store performance while maintaining the cost and durability benefits of Amazon S3 for persistent data storage.

Alluxio's strong Q2 featured Enterprise AI 3.7 launch with sub-millisecond latency (45× faster than S3 Standard), 50%+ customer growth including Salesforce and Geely, and MLPerf Storage v2.0 results showing 99%+ GPU utilization, positioning the company as a leader in maximizing AI infrastructure ROI.

Amazon S3 has become the de facto cloud hard drive—scalable, durable, and cost-effective for ETL, OLAP, and archival workloads.
However, as workloads shift toward training, inference, and agentic AI, S3's original assumptions begin to show limits.
Alluxio takes a different approach. It acts as a transparent, distributed caching and augment on top of S3, combining the mountable experience of FSx, the ultra low latency of S3 Express, and the cost efficiency of standard S3 buckets, all without requiring data migration. You can keep your s3:// paths (or mount a POSIX path), point clients at the Alluxio endpoint, and run.

In this talk, Ojus Save walks you through a demo of how to build AI applications on Zoom. This demo shows you an AI agent that receives transcript data from RTMS and then decides if it has to create action items based on the transcripts that are received.
In this talk, Sandeep Joshi, , Senior Manager at NVIDIA, shares how to accelerate the data access between GPU and storage for AI. Sandeep will dive into two options: CPU- initiated GPUDirect Storage and GPU-initiated SCADA.
Bin Fan, VP of Technology at Alluxio, introduces how Alluxio, a software layer transparently sits between application and S3 (or other object stores), provides sub-ms time to first byte (TTFB) solution, with up to 45x lower latency.

Watch this on-demand video to learn about the latest release of Alluxio Enterprise AI. In this webinar, discover how Alluxio AI 3.7 eliminates cloud storage latency bottlenecks with breakthrough sub-millisecond performance, delivering up to 45× faster data access than S3 Standard without changing your code.
