Abstract
Amazon S3 has become the de facto cloud hard drive—scalable, durable, and cost-effective for ETL, OLAP, and archival workloads.
However, as workloads shift toward training, inference, and agentic AI, S3's original assumptions begin to show limits. These use cases may require:
- Sub-millisecond or low-single-digit millisecond latency (e.g., for agentic memory, feature stores, RAGs)
- Bursty and highly concurrent writes (e.g., for data preprocessing)
- Advanced semantics like append writes (e.g., for write-ahead logs for OLTP)
AWS offers high-performance managed filesystems like FSx for Lustre for like FSx for POSIX-compatibility and premium object stores like S3 Express One Zone (also known as S3 directory bucket) for ultra-low latency. But both come with trade-offs: higher cost, provisioning complexity, and possible data migration..
Alluxio takes a different approach. It acts as a transparent, distributed caching and augment on top of S3, combining the mountable experience of FSx, the ultra low latency of S3 Express, and the cost efficiency of standard S3 buckets, all without requiring data migration. You can keep your s3:// paths (or mount a POSIX path), point clients at the Alluxio endpoint, and run.
Not strictly, but effectively: Alluxio ≈ FSx + S3 Express One Zone — without the cost or migration overhead.
Why This Matters — and Where S3 Bends
Amazon S3 is the undisputed backbone of cloud storage today, offering 11 9s durability across Availability Zones, auto-partitioning, and ~$23/TB/month pricing (S3 Standard, us-east-1). It stores over 400 trillion objects and handles up to 150 million requests per second (link). Scale is solved.
But as workloads evolve—toward training, inference, agentic memory, OLTP, and real-time analytics—S3’s original design begins to show strain. Technical teams now demand:
- Sub-millisecond SLAs for feature stores, agentic memory, and RAG pipelines
- Efficient support for write-ahead logs and checkpointing large objects
- High-performance metadata operations across millions of objects
And this all ideally happens without giving up S3’s pricing, scalability and operational simplicity.
The friction points in S3's current design include:
- Latency: Read TTFB (e.g., GetObject) in S3 standard buckets commonly lands in the 30–200 ms range—Okay for batch, but painful for inference and transactional access
- Limited Semantics: Rename = copy + delete; append = not supported
- “Bottleneck” in metadata operations: S3 “directories” are prefixes, and listing large ones is expensive
Simply put: S3 is brilliant at being a capacity store, but not a system for real-time and latency-critical workloads, and it doesn’t pretend to be.
So the key question from architects becomes:
“Can I meet modern latency and semantics expectations without replacing or migrating off of S3?”
We believe the answer lies in augmenting, not replacing, S3—and that's where Alluxio comes in.
Alluxio: A Shim Layer Bringing Performance and Semantics on S3
Alluxio is a software layer that transparently sits between applications and S3 (or any object store). It offers both POSIX and S3-compatible APIs. Users can simply mount existing S3 buckets (or any other cloud object store) without any data migration or import. Unlike single-node API-translation tools such as s3fs (link), Alluxio is fully distributed and cloud-native, implementing decentralized metadata and data management.
| Capability | |
|---|---|
| Zero-migration |
Mount existing S3 buckets as-is; no data move required
|
| Low-latency accelerator |
Achieves sub-ms latency for S3 objects
|
| Semantic bridge | Enable append, async writes, and cache-only updates |
| Minimal-hardware requirement |
Manage local SSDs for a unified, cost-efficient caching
|
| Kubernetes-native |
Deploy via Operator; integrated metrics, tracing, and observability
|
Think of it this way:
- FSx for Lustre gives you high-speed POSIX, but requires provisioning and no S3 access.
- S3 Express One Zone offers low-latency object access—but only within a single AZ, and at roughly 5x the cost of S3 Standard.
Alluxio gives you both: FSx-like experience, flexibility, and S3 Express-style performance, without migration, and without changing your storage backend.
Key Metrics
- Throughput: 43 GB/s, or 200K QPS for a single worker on 400 GbE
- Scale-out: Linearly scales with number of workers; no single point bottlenecks
- Latency: Cache hits return in sub-millisecond
- GPU utilization: >90% sustained in MLPerf training benchmark
And yes—no data migration required.
Alluxio's Ultra Low Latency Caching for Cloud Storage was introduced in Alluxio AI 3.7. Read this blog for feature details: https://www.alluxio.io/blog/alluxio-ai-3-7-now-with-sub-millisecond-latency.
Real-World Patterns & Results
Use Case 1: Low-latency Feature Store on S3 (link)
Problem: Training 100K+ ML models on 10M Parquet files in S3, High S3 latency (30–100 ms) caused stalls and In-memory caching hit limits
Solution: Alluxio added as low-latency cache on NVMe for Parquet files on S3
Result:
- 🚀 Model capacity: 10x the capacity 10K → 100K+
- ⚡ TTFB : 100ms -> ~1 ms for remote region, ~30ms -> ~1 ms for same region
- 📉 Training time: 35% reduction
- 💸 S3 requests: $1M+ eliminated per day
Use Case 2: Agentic Memory on S3 (link)
Problem:
- Lookups into Agentic Memory (Parquet files on S3) breach P99 SLAs (1ms)
- Updating Agentic memory translated to WAL Writes, but S3 does not support append
Solution: Distributed SSD caching from S3 in Alluxio, WAL buffered in Alluxio, flushed async
Result:
- P99 lookup latency < 1 ms
- Append latency < latency 5ms with durability guarantees with three replication
Alternatives: Side-by-Side Comparison
Quoted for US-East-1
| Feature |
S3 Standard
|
S3 Express One Zone
|
FSx Lustre + S3
|
Alluxio + S3
|
|---|---|---|---|---|
|
Latency (TTFB)
|
100+ ms
|
1–10 ms
|
1 ms
|
1 ms
|
|
Multi-cloud
|
❌
|
❌ | ❌ | ✅ |
|
POSIX API
|
❌ | ❌ |
✅
|
✅ |
|
S3 API
|
✅
|
✅ | ❌ | ✅ |
|
Support Append
|
❌
|
✅ | ✅ | ✅ |
|
Data Migration Required
|
No |
High (Creation time choice)
|
No | No |
|
Cost ($/TB/mo)
Assuming 20% hot data
|
~$231 | ~$1102 | ~$1433 | ~$234 to ~$425 |
1 Assumes S3 standard ($0.023 per GB-month) is the source of truth, hoping full data
2Assumes S3 Express One Zone ($0.110 per GB-month) holding full data, as it needs to be decided at bucket creation time
3 Assumes for 1,000 MB/s/TiB class, FSx Lustre ($0.600 per GB-month) holding 20% hot data, while S3 standard ($0.023 per GB-month) keeps full data
4 Assumes Alluxio deployed on GPU spare disks holding 20% hot data, no additional hardware cost, while S3 standard ($0.023 per GB-month) keeps full data
5 Assumes a separate Alluxio cluster holding 20% hot data using i3en.6xlarge instances ($2.023 per hr, 1 yr reserved, with 15TB NVMe attached), while S3 standard ($0.023 per GB-month) keeps full data
- i3en.6xlarge instances ($2.023 per hr / 15TB ) * 20% + S3 Standard ($23) = $42.4 per TB-month
Final Takeaways
You don’t need to choose between the scale of S3 and the speed / semantics of FSx or S3 Express.
With Alluxio, you get a "high-low mix":
- ✅ Durable, low-cost capacity (S3)
- ✅ High-performance, semantic-aware layer (Alluxio)
You avoid re-architecting apps, migrating or duplicating data, locking into single-AZ constraints.
You also avoid hand-rolling fragile cache layers per team or workload.
Rule of thumb:
If your workload needs P95 latency < 50 ms, or requires append, it’s time to add a performance layer.
Alluxio gives you that—without giving up S3.
Appendix
Benchmark Results
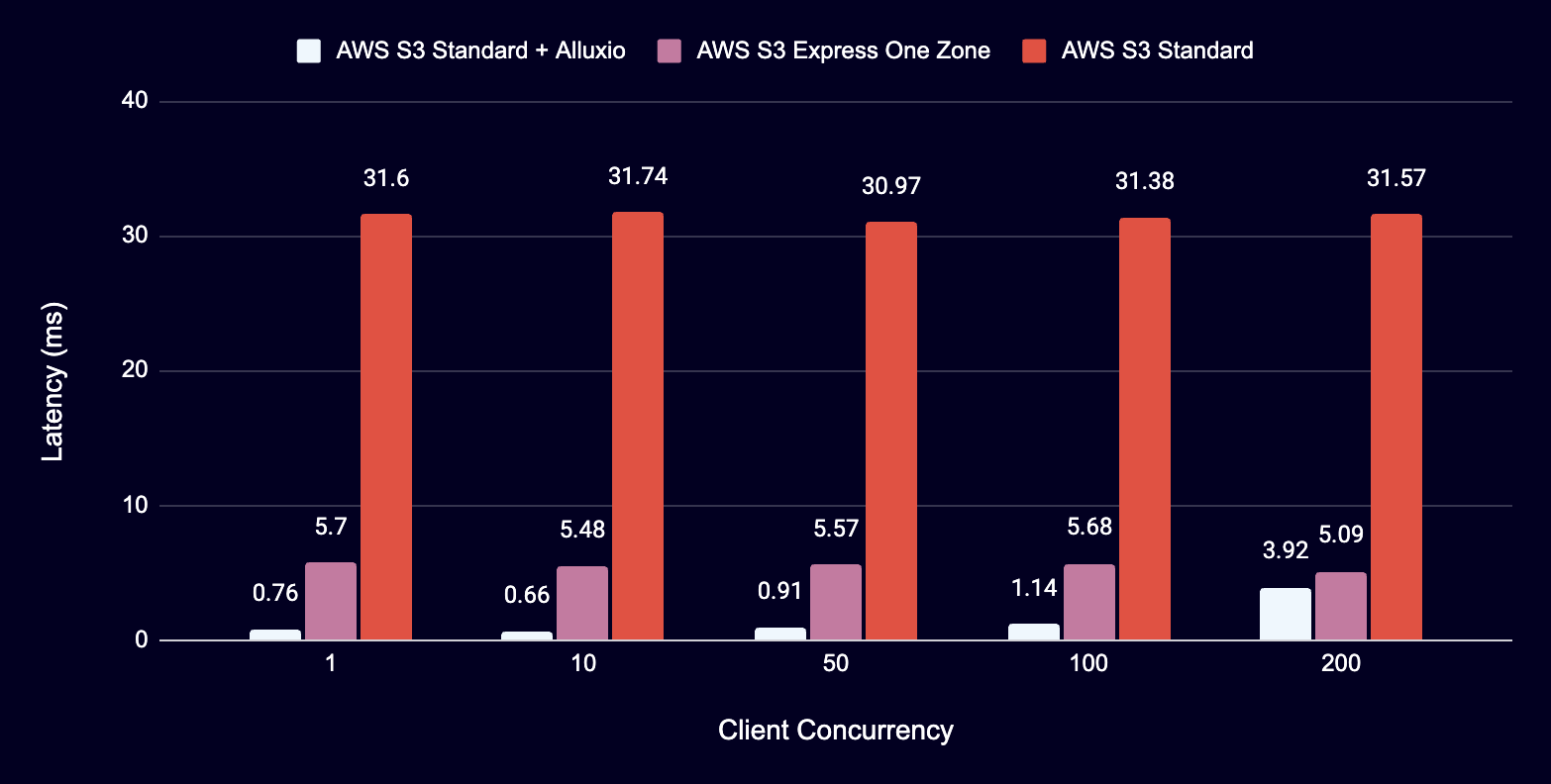
Latency Comparison - 10KB RangeRead
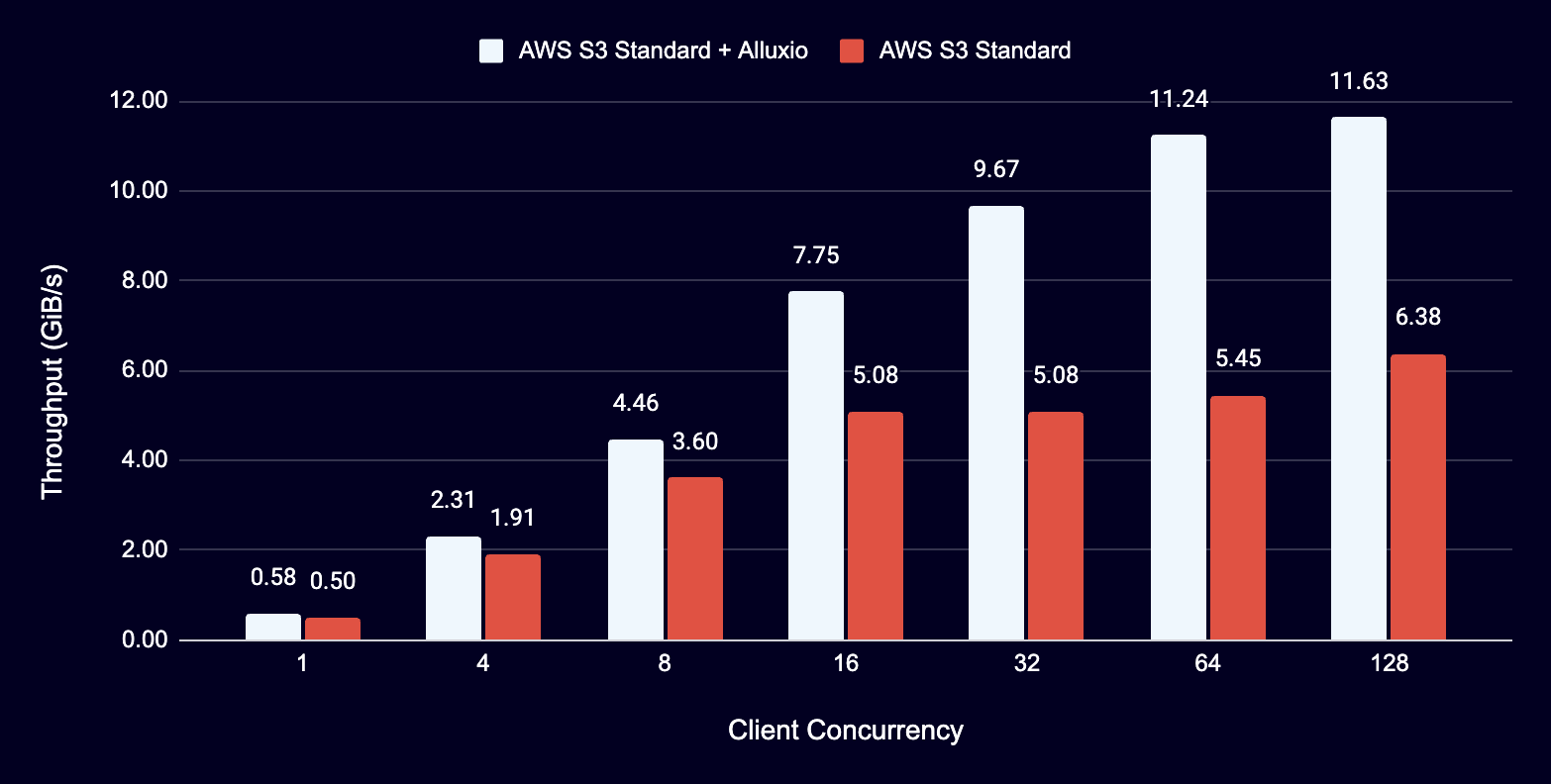
Read Throughput Comparison - Single Client
Test environment references
Alluxio
- Version/Spec: Alluxio Enterprise AI 3.6 (50TB cache)
- Test env: 1 FUSE (C5n.metal, 100Gbps network) and 1 Worker (i3en.metal)
AWS S3
- Version/Spec: AWS S3 bucket (Standard Class)
- Test env: 1 FUSE (C5n.metal, 100Gbps network)
AWS S3 Express One Zone
- Version/Spec: AWS bucket (S3 Express One Zone Class)
- Test env: 1 FUSE (C5n.metal, 100Gbps network)
Read this blog for benchmark details.
.png)


