If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver.
What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. Teams copy entire datasets, often terabytes or more of data, from source of truth data lakes or centralized cloud storage to GPU clusters around the globe. AI workloads, whether data prep, training, or inference, can’t even start until all data has been copied to their cluster. AI data access delays add days to weeks for training, erodes user experience for inference, spikes egress costs, and multiplies operational failure modes across clouds. There’s a simpler way.
Alluxio is the data acceleration layer that makes multi-GPU Cloud clusters work with simplicity, speed, and scale - simple for users, strategic for infrastructure partners.
Hurry Up and Wait - The Problem with “Copy Everything First”
- Patience and productivity lost. Modelers, data scientists, and engineers waste countless hours searching and waiting for the data needed to do their jobs.
- Time-to-first-epoch suffers. Training jobs sit idle waiting for full copies to complete, even though the data loader only needs a working set to begin.
- Inference cold starts lag. Slow, unstable model deployments negatively impact user experience with slow response times, inconsistent results, and application errors.
- Egress charges explode. Copying data out of a cloud provider quickly becomes one of the largest line items in the AI budget.
- Operational complexity compounds. Duplicate datasets create drift, consistency issues, and fragmented pipelines across clouds and regions.
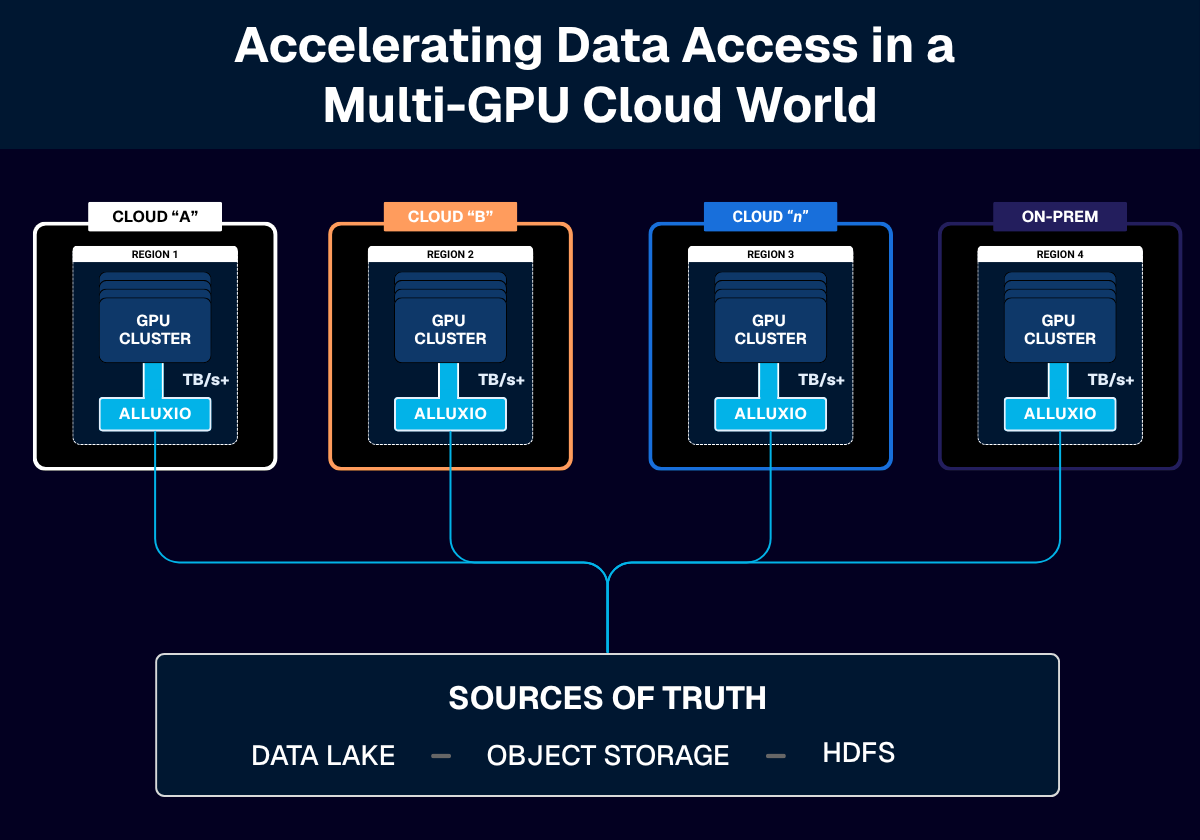
A Unified Data Acceleration Layer for the Multi-GPU Cloud
Alluxio provides a single namespace, accessible through POSIX and S3 APIs, that any server or compute cluster, on any cloud or on-prem data center, can mount. Think “open a folder and train” with no code changes.
Simplicity
- Transparent to users and applications. Files, directories, and buckets stay the same wherever your application runs.
- Interfaces unchanged. No new protocols, APIs, or complex integrations - whether your application relies on filesystem access or S3 API operations, it’s good to go with Alluxio.
- Instant data access on any GPU cloud. Immediately access AI data for training, deployment, and inference wherever your AI workloads run - simply mount and go.
- On-demand caching. Data is fetched and cached as it’s accessed, so AI workloads start immediately instead of waiting for full replication.
Speed
- Sub-Millisecond latency for ultra-fast AI inference, agents, and feature stores.
- Terabytes per second of throughput per cluster power large-scale AI training and model deployment workloads.
- Optimized for distributed, data-hungry AI training and inference workloads.
Scale
- I/O performance scales linearly with additional Alluxio Worker nodes.
- Only cache what is needed, when it’s needed without overprovisioning additional storage.
- Lower egress, fewer copies. Cache hot data close to compute while keeping authoritative data in place.
Proven in Customer Environments
Multi-Region Model Training Across Hybrid GPU Clusters
Coupang, A Fortune 200 Technology Company
Challenges
- Slow job starts due to required data copy and validation before training
- Underutilized GPU resources caused by I/O bottlenecks
- Rising cost and complexity managing data silos across regions
Solution
- Alluxio distributed cache deployed across AWS multi-region and on-prem GPU clusters to provide a unified data layer with on-demand caching and high I/O throughput.
- Developers access data through the same namespace across regions, enabling seamless job portability and immediate training starts without code changes.
Results
- Instant data availability — training jobs start immediately without pre-copying
- ~40% higher I/O throughput compared to cloud-native file systems
- Simplified operations and unified data access across all clusters
Additional details available in the full blog and the on-demand webinar presented by Coupang.
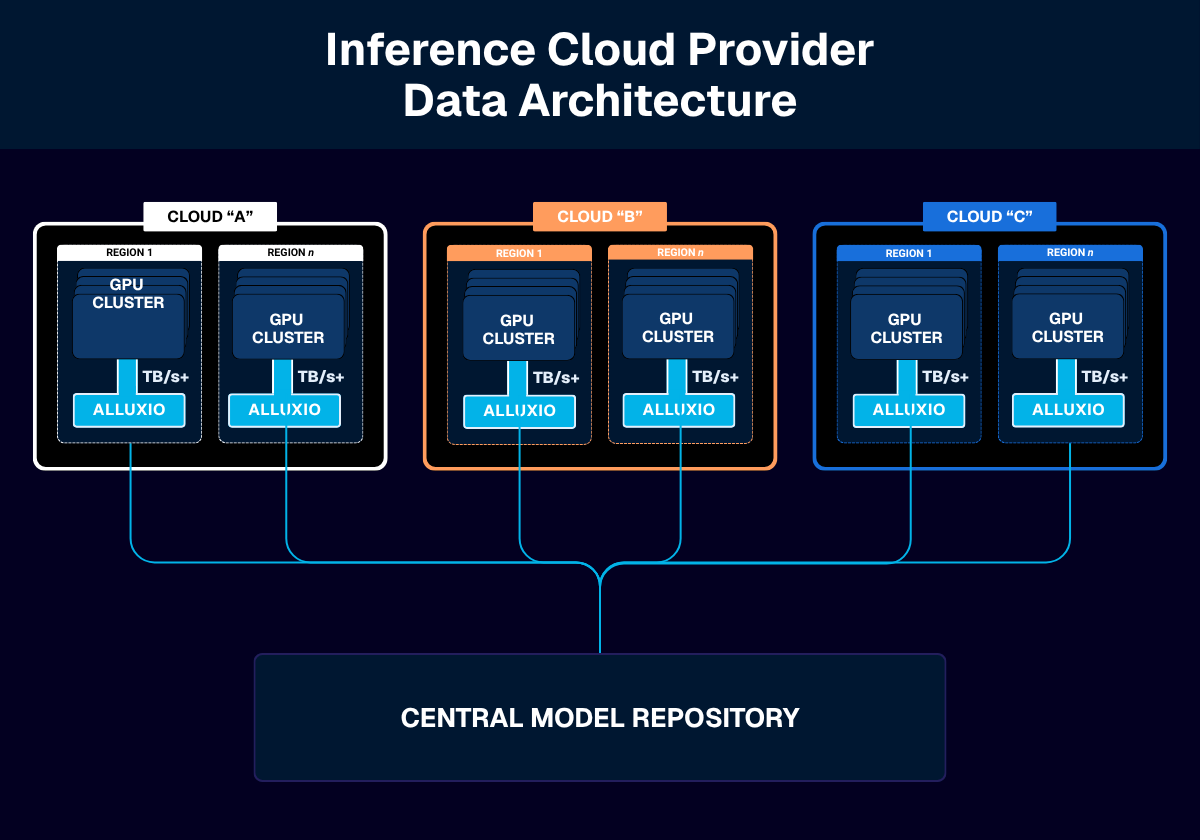
Model Deployment to Geo-Distributed, Multi-Cloud GPU Clusters
Leading Inference Cloud Provider
Challenges
- Slow and unstable cold starts impacting end user experience, customer retention, and brand reputation
- High operating costs, including egress costs and engineering resources, associated with model deployments to 200+ GPU servers distributed across 10+ GPU Clouds
Solution
- Alluxio distributed cache deployed in each cloud and/or region caches, on local NVMe drives, model files from a centralized model repository. GPU servers load model files from the local Alluxio distributed cache versus each GPU server pulling model files from the central model repository.
Result
- 1 terabyte per second of sustained I/O throughput during peak utilization per cluster
Why It Matters
- Enable Multi-GPU Cloud anywhere instantly with ease.
- Start training easier, sooner, and faster. Stream and cache instead of waiting on full-dataset replication.
- Inference cold starts fully optimized. GPU servers load model files directly from cache, no scp necessary.
- Improve efficiency. Raise GPU utilization and shorten iteration cycles.
- Simplify operations. Lower egress costs, reduce data copies, and unify pipelines across clouds.
- Future-proof flexibility. Move workloads wherever GPUs are available—no re-architecting or code changes required.
What “Good” Looks Like
- Mount once, train anywhere. Expose a consistent path to datasets across clouds and regions.
- Train now instead of waiting for data to be copied. Training jobs cache the working-set data on demand, while background data loader jobs warm the rest of the cache.
- Measure what matters. Track GPU utilization and time-to-first-epoch—both improve as bulk replication disappears.
- Cache once for cluster-wide cold starts. Inference cold starts that just work. And work really fast.
- Keep authoritative data in place. Minimize duplication and rely on Alluxio for locality and performance.
The Takeaway
Multi-cloud isn’t a trend, it’s the new reality of AI infrastructure. The challenge isn’t access to GPUs; it’s enabling data access that’s seamless, simple, and speedy at scale. The answer isn’t to copy more, it’s to cache intelligently, keeping AI workloads simple while starting sooner and finishing faster
A seamless, intelligent data acceleration layer makes the multi-GPU, multi-cloud world operate like one unified cluster.
That layer is Alluxio. Mount. Train. Deploy. Serve. Repeat.
.png)


