Accelerate Spark workloads with Alluxio
Unparalleled performance in any environment
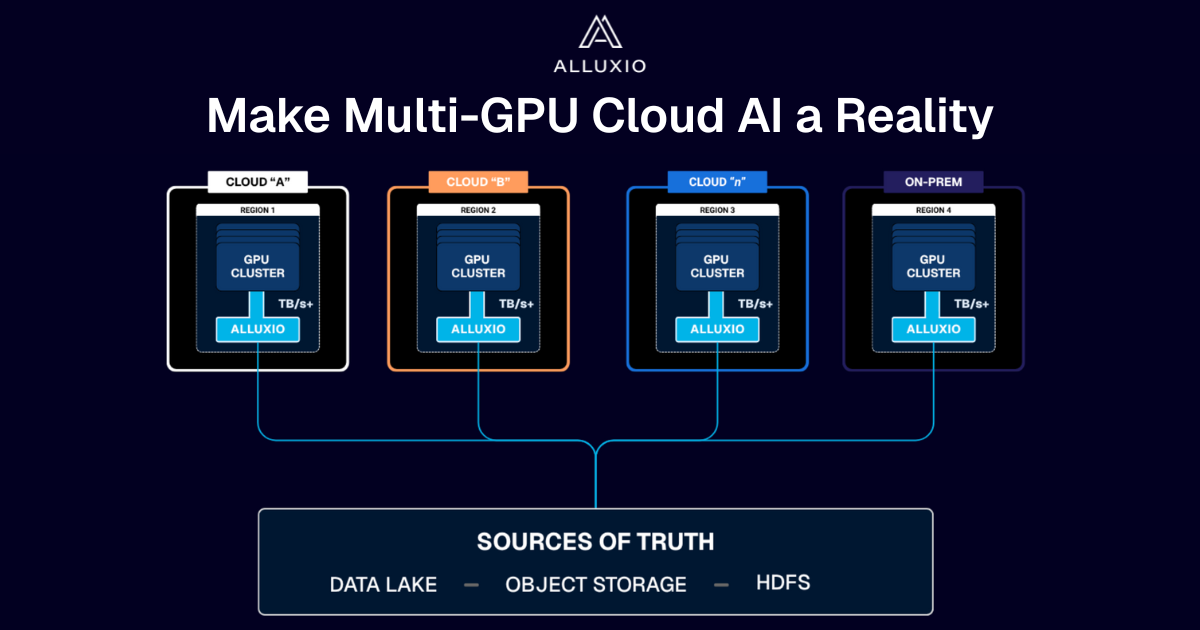
By bringing together Alluxio and Apache Spark, you can modernize your data platform with seamless data access, application portability, and up to 70% TCO savings. Alluxio brings back data locality to Spark’s distributed analytics engine in disaggregated environments and provides an intelligent and highly available data tier for Spark. Alluxio’s unified namespace feature also enables hybrid cloud environments for Spark jobs running in the cloud and data on-prem.
.png)
Data engineering problems for spark workloads
Spark provides executor level caching, but it is limited by garbage collection. For larger datasets, using the Spark cache approach doesn’t work. Other problems may include:

Network latency to query remote data is very high, making interactive Spark on remote datasets unattainable

Many copies of data need to be created across environments, making it hard to manage and track

Metadata operations like list and rename can be slow and expensive when running on object storage

No good approach for sharing large datasets across multiple jobs in a data pipeline
Alluxio + Spark use cases
Spark with Alluxio gives you data locality in disaggregated environments and a highly available data tier for Spark with no data copies. Connecting to a variety of storage systems and cloud, you can deploy Alluxio with Spark anywhere, on prem, single cloud, multi-cloud, or in a hybrid environment

Deploying Alluxio with Spark

Reading cloud data into Spark and enabling data sharing is automated and transparent with Alluxio. Alluxio can be deployed colocated with Spark and be backed by a mounted remote storage.
Learn moreIntegrate on-prem data stores like HDFS with Alluxio and Spark and get high performance in your hybrid cloud environment. Burst Spark into the cloud on-demand, when you need it.
Learn more
Why Alluxio + Spark
Alluxio allows up to 70% data infrastructure TCO savings, including reducing network egress costs and S3 API costs, enabling elastic compute while saving platform operations costs.
Co-locating with Spark, Alluxio provides high availability and improved data locality, enhancing query performance with reduced I/O access latency. Alluxio also provides a multi-tiered layer caching for Spark, ensuring strong consistency for metadata operations and faster performance.
With Alluxio, your data applications are easily portable across all environments.Alluxio standardizes your data stack through a unified namespace, providing a single access model across all storage systems. Application developers no longer need to worry about where the data resides, and you can decouple compute and storage without worrying about application rewrites.