In the latest MLPerf Storage v2.0 benchmarks, Alluxio demonstrated how distributed caching accelerates I/O for AI training and checkpointing workloads, achieving up to 99.57% GPU utilization across multiple workloads that typically suffer from underutilized GPU resources caused by I/O bottlenecks.
Although GPUs are fast, their effectiveness in AI training hinges on overcoming two critical I/O bottlenecks: data loading and checkpointing. As we've previously discussed in the white paper on optimizing I/O for AI workloads, the true challenge in AI training infrastructure isn't raw computing power: it's ensuring your expensive GPUs aren't stalled by slow data loading during training epochs or lengthy checkpoint operations during model saves.
Accelerating I/O is crucial because modern AI training involves repeatedly reading massive datasets across multiple epochs while frequently saving model states that can exceed hundreds of gigabytes. When I/O can't keep pace with GPU processing speeds, GPUs sit idle, wasting thousands of dollars per hour in compute resources and delaying critical model development. This is why MLCommons created the MLPerf Storage benchmark: to measure the performance of storage systems for machine learning workloads in an architecture-neutral, representative, and reproducible manner, as announced in today's v2.0 results.
In this blog, we'll explore how Alluxio's distributed caching architecture addresses these I/O challenges, analyze its performance in the latest MLPerf Storage v2.0 benchmarks across various AI workloads, and explain what these results mean for optimizing your AI training infrastructure. You'll see how achieving over 99% GPU utilization translates directly to faster model training and better ROI on your GPU investments.
Two Key I/O Bottlenecks in AI Training: Data Loading and Checkpointing
Data loading in model training, as the name implies, is the process of loading training datasets from storage into the GPU server’s CPU memory. As PyTorch DataLoader, TensorFlow’s tf.data, and similar frameworks issue mixed sequential and random read requests, storage systems struggle to maintain consistent throughput. The challenge intensifies with multiple training epochs, where the same massive datasets must be repeatedly accessed from storage. Traditional storage architectures often buckle under this demand, creating unpredictable latency spikes that leave GPUs starved for data. When data loading can't match GPU processing speeds, expensive compute resources sit idle, dramatically extending training timelines and inflating infrastructure costs.
Model checkpointing is the process by which the training code periodically saves the model state to disk. In the event there is a failure during training, the saved model state can be reloaded and training can resume from that point in time. Training calculations are paused until the checkpoint process finishes writing the model state files to disk. Most training workloads checkpoint after each iteration, which is a full pass of the training code on a single batch of data. Throughout an epoch, the model state files grow larger with each iteration and can reach hundreds of gigabytes in size or more. Therefore, if checkpoint writes are bottlenecked by slow I/O, then the end-to-end training time will be delayed as well.
Understanding MLPerf Storage v2.0 Benchmarks
Today, MLCommons announced the new MLPerf Storage v2.0 benchmark results, highlighting the critical role of storage performance in AI training systems. The results can be found here: http://mlcommons.org/benchmarks/storage/.
Workloads simulated by MLPerf Storage Training v2.0 include the following, representing typical workloads and common types of model training across various industries.
This v2.0 benchmark, different from v1.0, adds a new checkpointing workload focused on addressing the backup and recovery speed for training, with a focus on LLMs on scale-out systems.
The benchmarks include the following metrics:
- Throughput: The throughput and latency while maintaining accelerator utilization > 90% (3D-Unet and ResNet50) and >70% (CosmoFlow):
- Training: Read B/W (GiB/s).
- Checkpoiniting: Write B/W (GiB/s), write duration (secs), read B/W (GiB/s), and read duration (secs).
- Number of Simulated Accelerators: The number of simulated accelerators active during this test.
Alluxio Demonstrates Strong Performance in MLPerf Storage v2.0 Benchmarks
In the MLPerf Storage v2.0 benchmark tests, Alluxio has demonstrated strong results for AI training and checkpointing workloads.
Highlights of Alluxio’s benchmark results:
- Model Training:
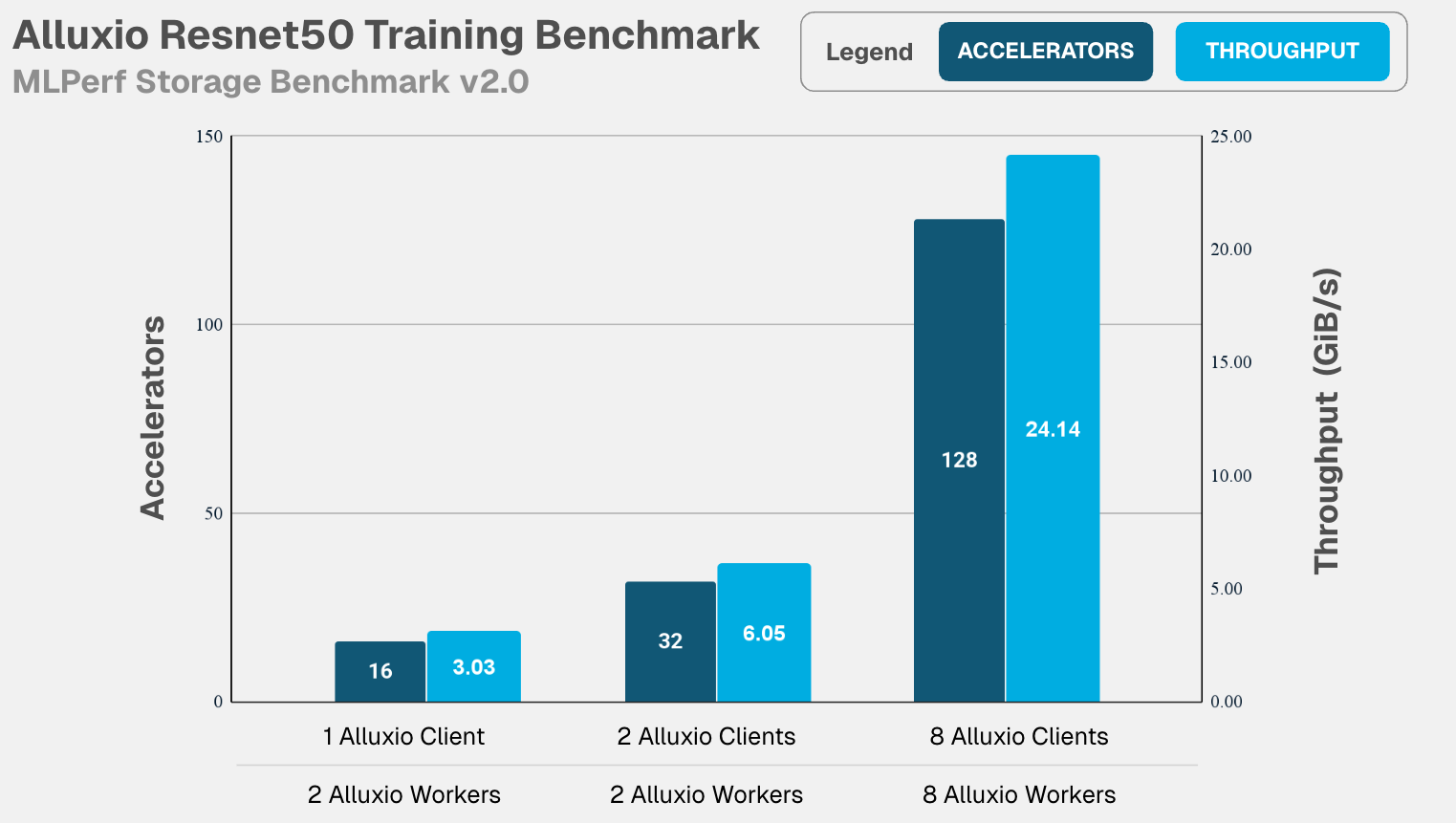
- ResNet50: 24.14 GiB/s supporting 128 accelerators with 99.57% GPU utilization.
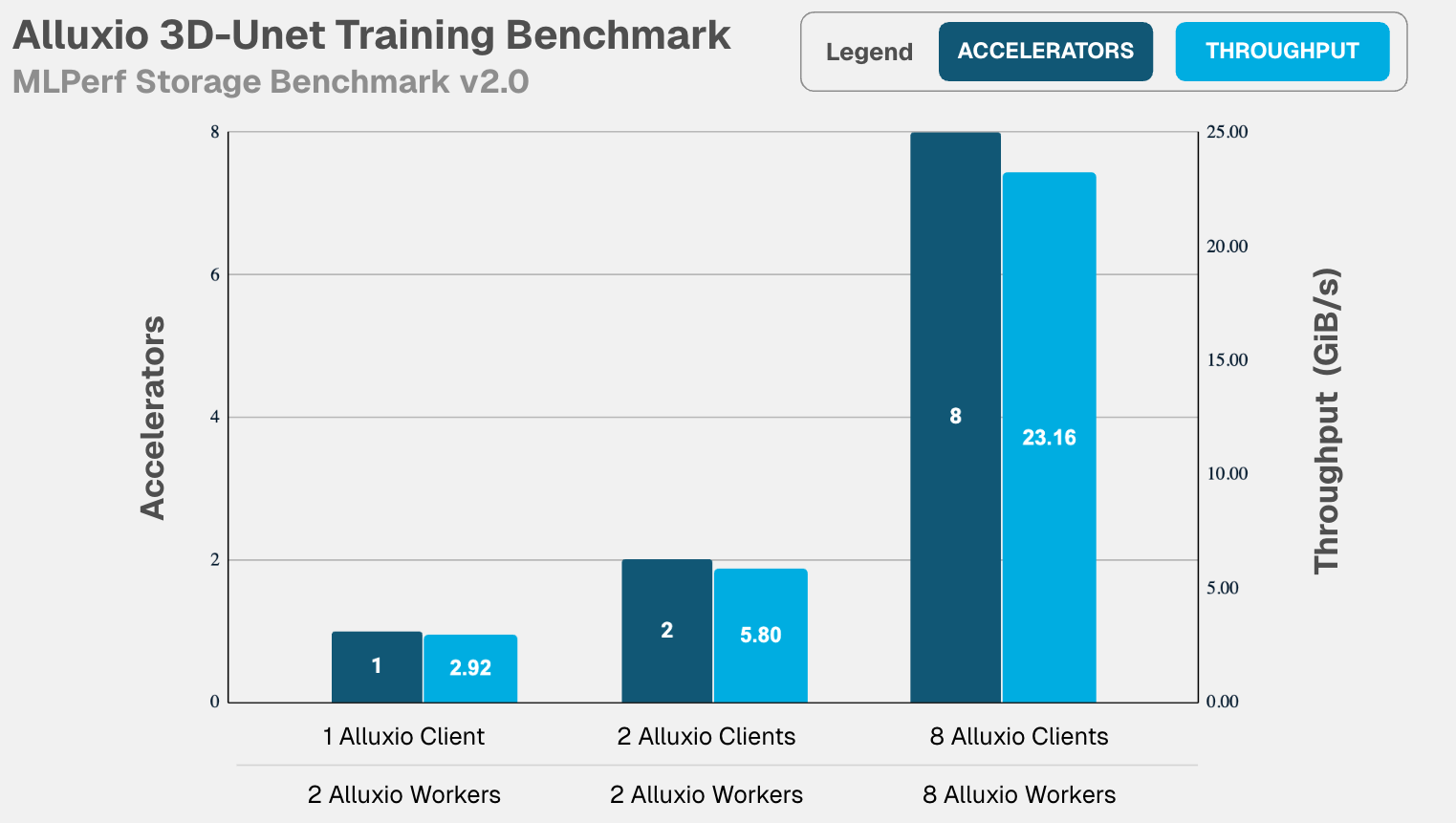
Alluxio scaled linearly from 1 to 8 clients and 2 to 8 workers, while keeping accelerators fully utilized as they scaled from 16 to 128, highlighting consistent performance as workload increases. - 3D-Unet: 23.16 GiB/s throughput with 8 accelerators, maintaining 99.02% GPU utilization. Alluxio scaled linearly from 1 to 8 clients and 2 to 8 workers, while keeping accelerators fully utilized as they scaled from 1 to 8, again highlighting consistent performance as workload increases.
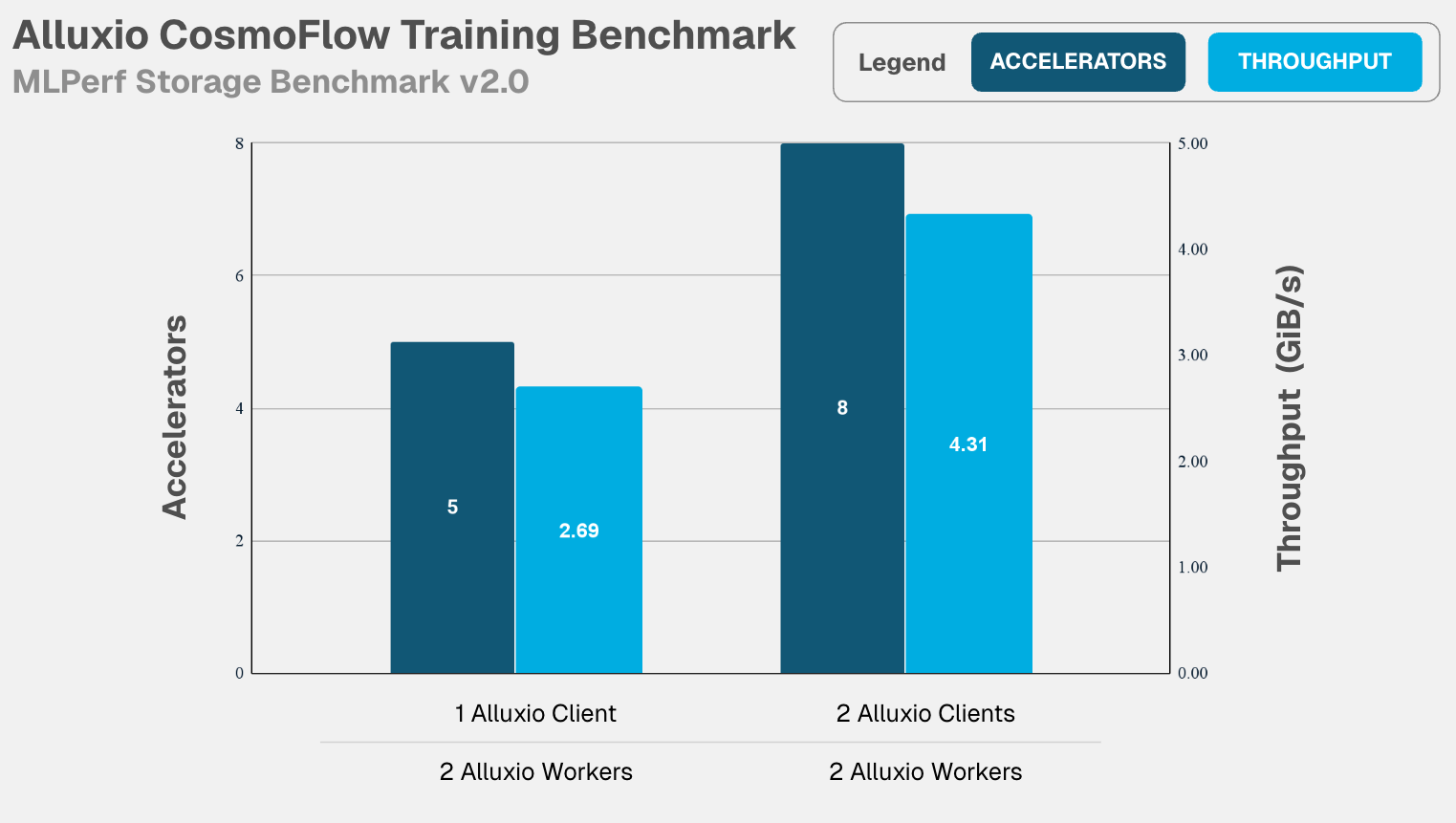
- CosmoFlow: 4.31 GiB/s supporting 8 accelerators with 74.97% utilization, nearly doubling the performance when scaling from 1 to 2 Alluxio clients as GPU accelerators increase from 5 to 8.
- ResNet50: 24.14 GiB/s supporting 128 accelerators with 99.57% GPU utilization.
- LLM Checkpointing:
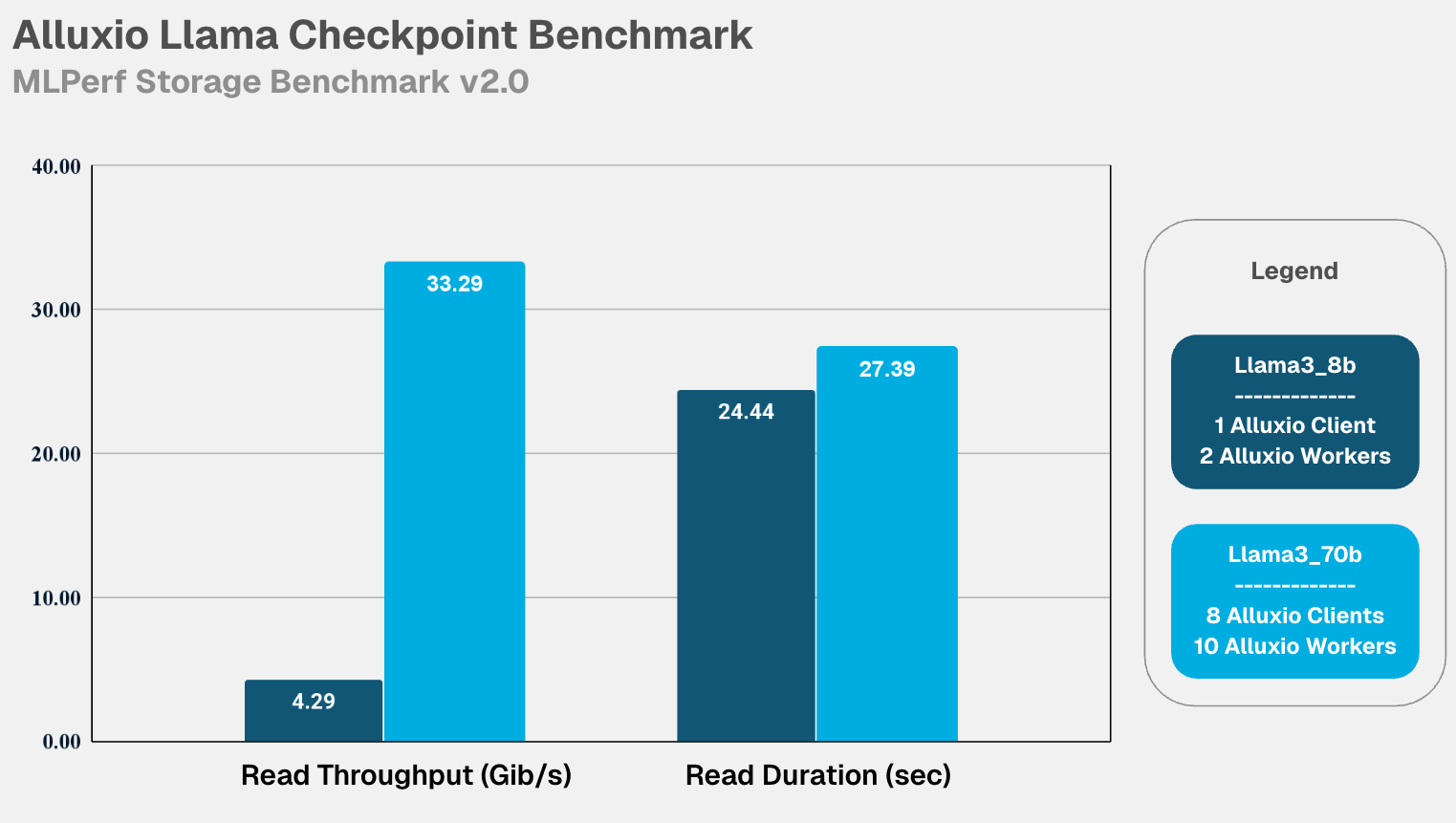
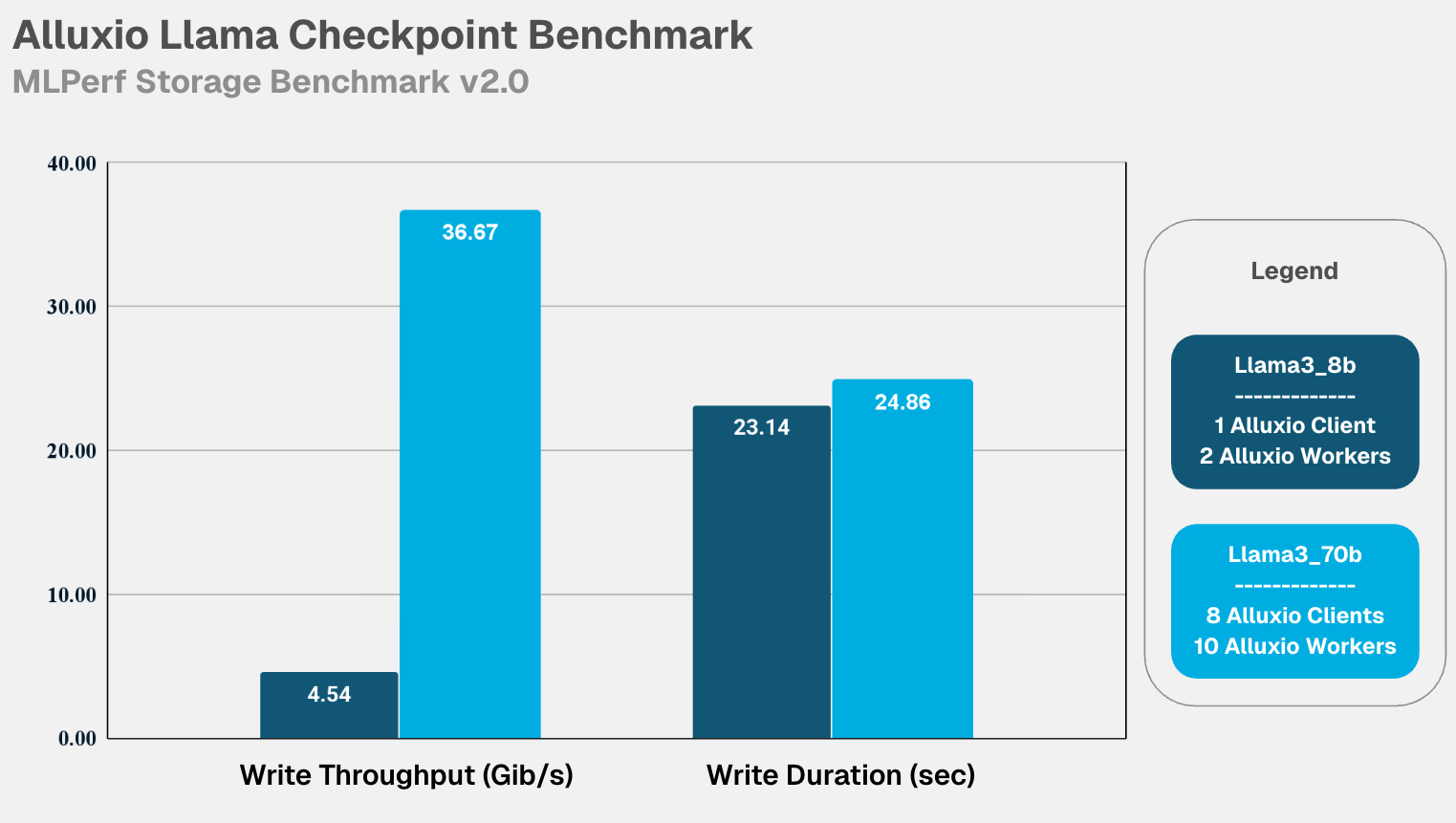
- Llama3_8b: 4.29 GiB/s read and 4.54 GiB/s write. 24.44 secs read and 23.14 secs write durations.
- Llama3_70b: 33.29 GiB/s read and 36.67 GiB/s write. 27.39 secs read and 24.86 secs write durations.
What These MLPerf Benchmark Numbers Mean for Your AI Infrastructure
The ability to deliver high-throughput I/O directly determines whether your AI training infrastructure operates efficiently or wastes expensive GPU cycles. Alluxio's MLPerf Storage v2.0 benchmark results reveal the profound impact eliminating I/O bottlenecks has on AI training performance:
- Maximized training throughput: When storage I/O keeps pace with GPU processing, as demonstrated by Alluxio's up to 99.57% GPU utilization, AI models train faster, iterations complete sooner, and experiments conclude in days rather than weeks.
- Accelerated checkpointing for resilient training: Fast checkpoint writes and reads mean training can resume quickly after interruptions, reducing the risk of losing hours or days of computation due to system failures.
- Linear scaling for distributed caching: The ability to scale out Alluxio while maintaining consistent per-GPU performance enables true scalability, where adding more Alluxio clients and workers translates directly to better performance.
- Optimized infrastructure ROI: Every percentage point of GPU utilization represents enormous costs in compute efficiency. The difference between 50% utilization (common with traditional storage) and up to 99.57% (achieved with Alluxio) means effectively doubling your AI training capacity without buying additional GPUs.
The Alluxio Advantage - Distributed Caching, Not Storage
Alluxio's exceptional MLPerf Storage v2.0 benchmark performance stems from a fundamental architectural difference: it operates as a distributed caching layer rather than traditional storage, strategically positioned between compute and storage to eliminate I/O bottlenecks. This approach leverages high-speed NVMe SSDs deployed close to GPU clusters, creating a performance multiplier effect that traditional network-attached storage simply cannot match.
How Alluxio removes the I/O bottlenecks of data loading and checkpointing:
- Data loading in model training (Read Optimization): Alluxio accelerates data loading by caching training data on NVMe SSDs close to or collocated with GPU clusters. This ensures high-throughput data access, keeping GPUs fully utilized during data loading.
- Checkpointing (Read & Write Optimization): Alluxio accelerates saving and restoring checkpoint files through caching, enabling faster writes and low-latency reads for checkpoints. By caching data locally on NVMe SSDs, Alluxio supports rapid writes and reduces delays from remote storage, ensuring efficient and reliable checkpointing.
Looking Ahead
As AI models continue to grow in complexity and scale, efficient data loading and checkpointing in AI training becomes increasingly important. Alluxio's MLPerf Storage v2.0 benchmark results demonstrate how Alluxio’s unique approach can effectively address these challenges.
Ready to learn more about optimizing your AI infrastructure?
- Book a meeting to discuss how Alluxio can help your organization improve GPU utilization and training performance.
- Dive deeper by reading the technical white paper, Optimizing I/O for AI Workloads in Geo-Distributed GPU Clusters, which covers common causes of slow AI workloads and low GPU utilization, how to diagnose the root cause, and provides solutions to the most common reasons for underutilized GPUs.
.png)
Blog



Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading