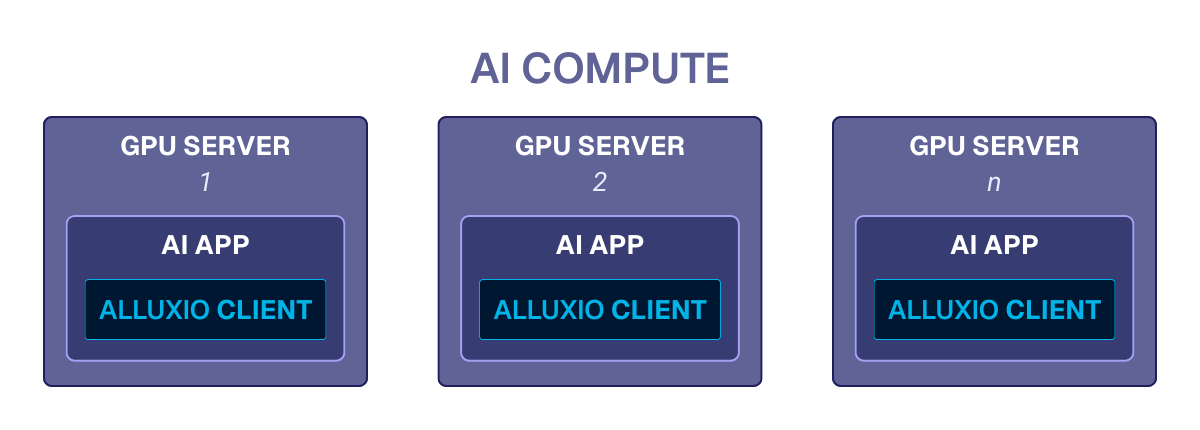
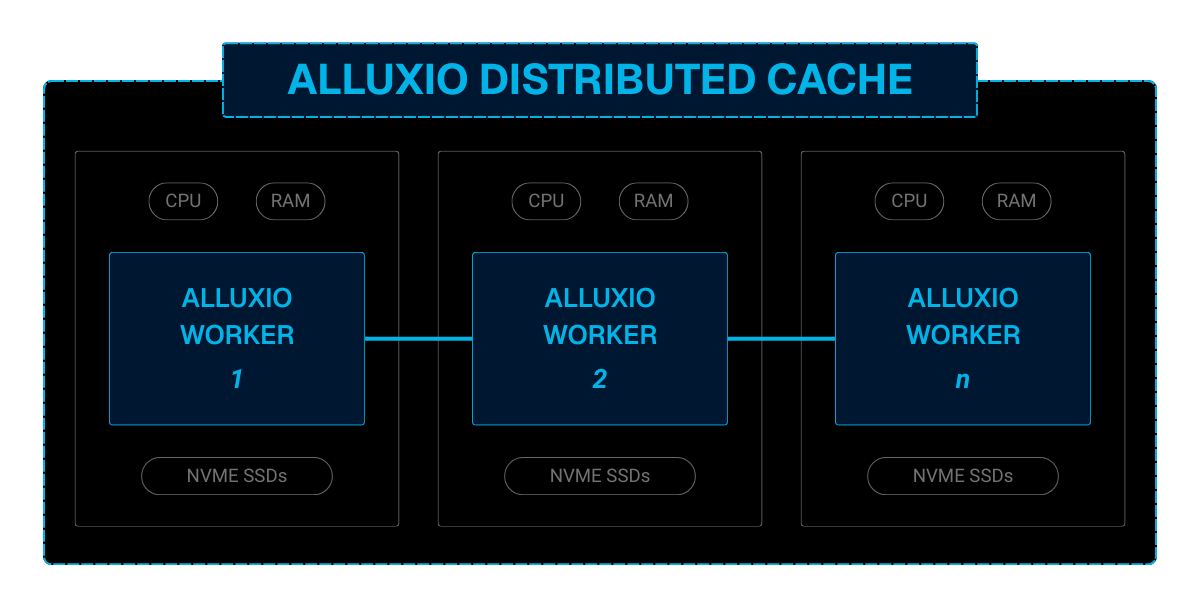
Alluxio implements distributed caching to cache data across distributed worker nodes equipped with NVMe SSDs. Unlike traditional systems that rely on a central master, Alluxio distributes data responsibilities using consistent hashing. This allows the cache to scale linearly with the cluster size to handle massive datasets and high-concurrency access patterns typical of deep learning workloads without creating I/O bottlenecks.
Alluxio decentralizes metadata management to overcome the metadata bottleneck inherent in object stores when handling billions of files. Each Alluxio worker node locally caches the metadata (file size, permissions, physical location) for the data segments it manages and stores them in high-speed RocksDB instances. This ensures that file operations like ls or stat, which are critical for training loops and data loaders, are served instantly from local memory rather than waiting on slow remote object store API calls.
Alluxio supports flexible cache modes to suit different data access patterns:
Alluxio’s distributed cache preloading enables the proactive loading of specific datasets from cloud storage into the high-performance NVMe cache tier before the workload begins. Warming up the cache ensures that GPUs receive data at maximum throughput from the very first epoch. This significantly reduces idle time and accelerates time-to-result for expensive training runs.
Achieve sub-millisecond TTFB latency, which is critical for latency-sensitive applications like feature stores, agentic AI memory, and real-time inference serving. By serving data directly from local NVMe caches close to compute, Alluxio eliminates the network round-trips associated with retrieving data from remote cloud object stores. This enables instant data availability for applications requiring rapid random access to varied datasets.
Alluxio is engineered to saturate network bandwidth and deliver terabytes per second of aggregate throughput, maximizing GPU utilization. By parallelizing I/O operations and utilizing efficient zero-copy data transfer mechanisms, Alluxio ensures that data delivery keeps pace with modern GPUs (H100/A100). This reduces costly idle cycles during bandwidth-intensive tasks like large-scale model training and massive model checkpointing.
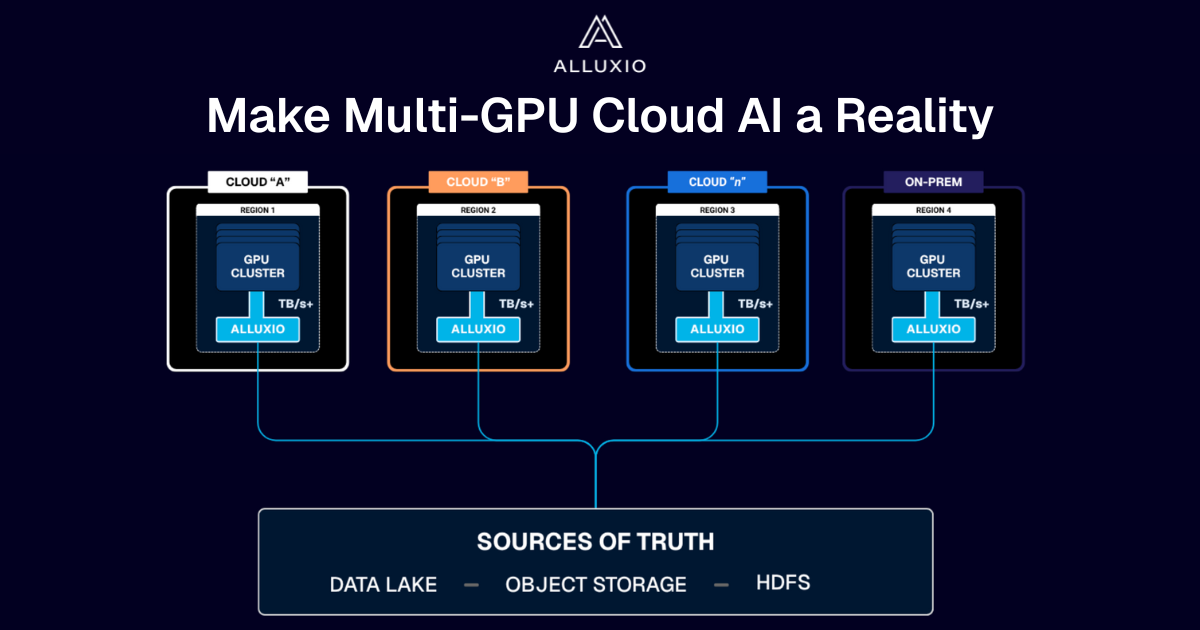
Alluxio acts as a universal abstraction layer that connects to virtually any storage backend. It integrates seamlessly with major cloud providers, including AWS S3, Google Cloud Storage (GCS), Oracle's OCI object storage, Azure Blob Storage, as well as on-premises systems like HDFS, NFS, Ceph, and MinIO. This pluggable architecture enables distinct, heterogeneous storage systems to all be mounted on a GPU server without physically copying data to solve data gravity challenges.
Alluxio aggregates multiple disparate storage backends, such as an S3 bucket in US-East and an on-prem HDFS cluster, into a single and logical file system hierarchy accessible via alluxio://. Users and applications interact with a unified directory structure to abstract away the complexities of different physical locations and storage protocols.
Enable "plug-and-play" data access for any AI framework without code refactoring. Alluxio provides:
Alluxio ensures end-to-end security with TLS encryption for data in transit. For access control, it integrates with Apache Ranger to provide centralized and granular policy management at the namespace level so administrators can define exactly who can read or write data. Additionally, comprehensive Audit Logs track all file access events to satisfy compliance and governance requirements.
Designed for zero downtime, Alluxio removes single points of failure through its decentralized architecture. If a worker node fails, the consistent hashing ring automatically rebalances and requests are routed to healthy nodes or the UFS without service interruption. Cluster coordination is managed by high-availability service registries, such as etcd, to ensure the control plane remains resilient even during network partitions or hardware outages.
Alluxio supports multi-availability zone deployments for those requiring maximum availability.
Alluxio Enterprise AI comes with dedicated support and account management to ensure operational success:
Alluxio is architected for modern and containerized environments. It deploys easily on Kubernetes via a dedicated Operator that manages the lifecycle of the data layer. It integrates natively with the cloud-native ecosystem and supports standard metrics (Prometheus), distributed tracing, and logging for full observability. Whether running on bare metal or orchestrated containers, Alluxio scales dynamically with compute clusters.
Alluxio exposes comprehensive metrics, including cache hit ratios, I/O throughput, latency histograms, and worker saturation, enabling operations teams to monitor system health in real time. These metrics integrate seamlessly with dashboards like Grafana to enable proactive identification of bottlenecks and capacity planning based on actual usage trends.
Simplify cluster administration with the Alluxio WebUI. This management console provides a centralized view of the entire cluster state, including connected storage systems, worker node status, and mounted namespaces. Administrators can browse the file system, verify configuration settings, view logs, and troubleshoot issues directly from a user-friendly browser interface to reduce the operational overhead of managing large-scale distributed systems.