AI loves cloud storage for scale and economics, but hates the latency. With Alluxio AI 3.7, we’re bridging that gap. Turn your high-latency cloud storage into a low-latency cloud storage with Alluxio Ultra Low Latency Caching for Cloud Storage. New in Alluxio AI 3.7, this new low-latency caching delivers sub-millisecond time to first byte (TTFB) latency through a transparent, distributed caching layer for AI data stored on cloud storage, boosting your feature store queries, model training, model deployment, agentic AI, and inference workloads.
Performance at a glance:
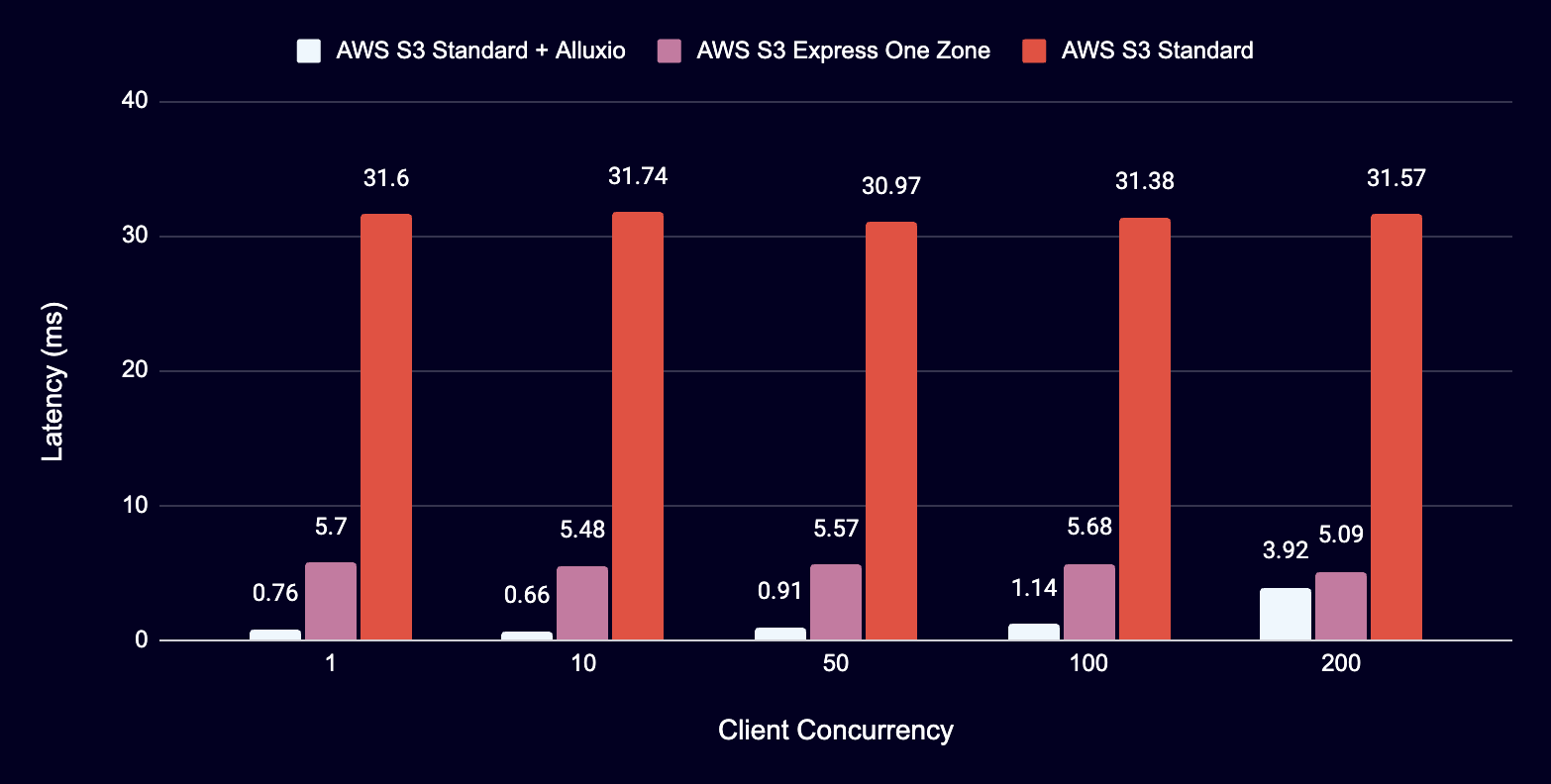
- Up to 45× lower latency than S3 Standard
- Up to 5× lower latency than S3 Express One Zone
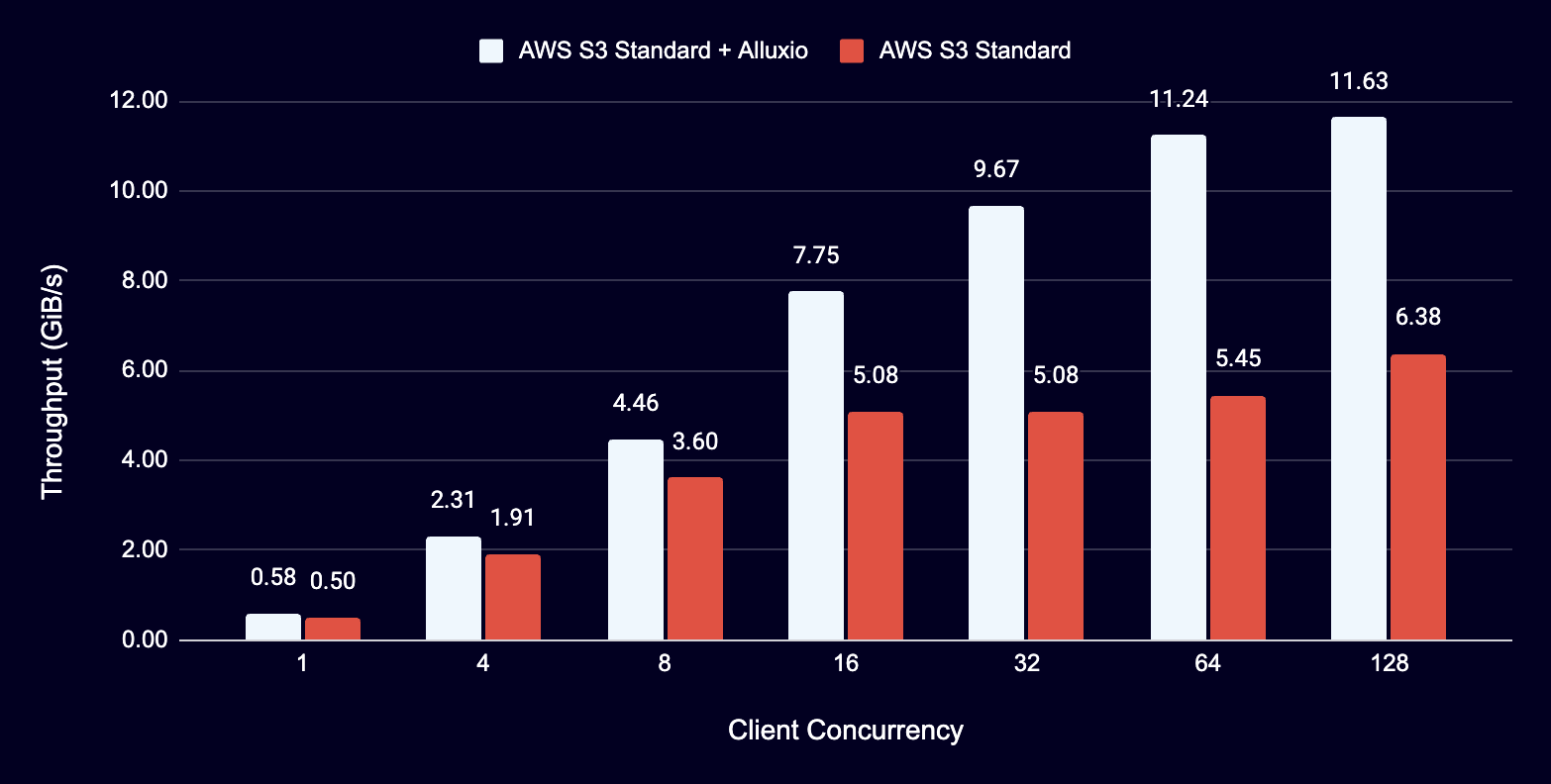
- Up to 11.5 GiB/s (98.7 Gbps) throughput per worker node with 100 Gbps NIC
- Linear scalability in throughput and capacity with additional worker nodes
That's not all. Alluxio AI 3.7 is packed with new features designed to supercharge your AI infrastructure while keeping your data secure. Let's dive into what's new.
Introducing Alluxio Ultra Low Latency Caching for Cloud Storage
Alluxio Ultra Low Latency Caching for Cloud Storage is a transparent caching layer that sits between your AI workloads and your cloud storage, delivering sub-millisecond TTFB latency while maintaining high throughput. With Alluxio’s S3-compatible interface (supporting clients like boto) and POSIX client, you’ll be up and running with Alluxio without changing a single line of your code.
AI teams today face a critical challenge: cloud storage, such as Amazon S3, provides excellent low-cost, scalable storage, but its latency can severely bottleneck AI training and inference workloads. Traditional solutions require complex data staging pipelines or costly infrastructure changes. With the transparent Alluxio Low-Latency Caching for Cloud Storage, you get the best of both worlds: S3's economics and reliability combined with local storage performance.
Alluxio ≈ FSx + S3 Express One Zone — without the cost or migration overhead. Read more about how Alluxio transforms Amazon S3 into a high-performance storage layer for AI workloads without requiring data migration: https://www.alluxio.io/blog/alluxio-s3-a-tiered-architecture-for-latency-critical-semantically-rich-workloads
Whether you’re looking to speed up feature store queries, model training, model deployment, or inference, Alluxio Low Latency Caching for Cloud Storage delivers the low latency you require without changing code or copying data. When your application requests data, Alluxio automatically caches frequently accessed objects across distributed worker nodes, delivering:
- Up to 45x lower latency than S3 Standard
- Up to 5x lower latency than AWS S3 Express One Zone
- Up to 11.5GiB/s (or 98.7 Gbps) throughput per worker node with 100 Gbps network
- Linear scalability in throughput and capacity with additional worker nodes
This new low-latency caching is a collaboration between Alluxio and Salesforce’s engineering team, which we recently demonstrated in the “1000x Performance Boost” white paper and webinar. Alluxio dramatically accelerates AI workloads like accessing agentic memory at PB-scale by overcoming cloud storage latency bottlenecks.
Latency Comparison - 10KB RangeRead
Read Throughput Comparison - Single Client
This transparent caching also reduces your S3 API calls and egress charges, lowering your overall infrastructure spend while accelerating your AI pipelines.
Learn more about Alluxio S3 API: boto3 client, PyTorch client, NVIDIA Triton inference server.
Role-Based Access Control (RBAC) for S3 Access
Alluxio now provides comprehensive Role-Based Access Control (RBAC) for S3 data accessed through the cache, enabling administrators to define granular permissions and integrate with existing authentication and authorization services.
As AI adoption grows, organizations need to ensure that cached data maintains the same security and compliance standards as the underlying storage. Without proper access controls at the caching layer, sensitive data could be exposed to unauthorized users or applications, creating security vulnerabilities and compliance risks.
Alluxio's RBAC system integrates seamlessly with popular authentication services, including:
- OIDC/OAuth 2.0-based providers (Okta, Cognito, Microsoft AD)
- Apache Ranger for policy management
Administrators can define fine-grained policies that control:
- User authentication before accessing S3 data through Alluxio
- Authorization to specific S3 buckets and objects
- Permitted operations (create, read, update, delete) on cached data
This ensures your AI data remains secure and compliant throughout its entire lifecycle, from persistent storage to cache to application.
5X Faster Cache Preloading with Alluxio Distributed Cache Preloader
The enhanced Alluxio Distributed Cache Preloader now includes a parallelism option that accelerates cache preloading by up to 5X for large files (> 1GB).
Whether you're starting a new training job or deploying models to inference servers, waiting for data to load into the compute nodes creates unnecessary delays. Teams working with large language models for model deployment or massive datasets for model training face particularly acute wait times.
When parallelism is enabled, Alluxio intelligently partitions large files into smaller chunks and loads each chunk simultaneously across multiple threads instead of preloading or warming up the cache in batches. This distributed approach dramatically reduces the time needed to warm up your cache, ensuring your:
- Training jobs start with hot data from the first epoch
- Model deployments achieve fast cold starts
- Feature stores are ready for immediate high-performance queries
FUSE Non-Disruptive Upgrade
Alluxio's innovative FUSE Online Upgrades feature allows you to upgrade FUSE services without interrupting active AI workloads, a first in the industry.
Traditional FUSE upgrades require complete service shutdown, terminating all active connections and unmounting filesystems. For 24/7 AI operations, whether training pipelines, inference services, or feature stores, this downtime is unacceptable. Every minute of downtime can mean missed SLAs, delayed model updates, or lost revenue.
Alluxio's FUSE Online Upgrade capability maintains data accessibility throughout the upgrade process by:
- Preserving active file handles and connections
- Queuing operations during the brief transition period
- Automatically resuming operations within tens of seconds
In this release, read operations (read, stat) are fully retained, while write operations will be supported in future updates. This ensures your critical AI workloads keep running even during necessary system maintenance.
Other New Features for Alluxio Admins
Streamline Alluxio Deployment and Configuration with Intuitive WebUI
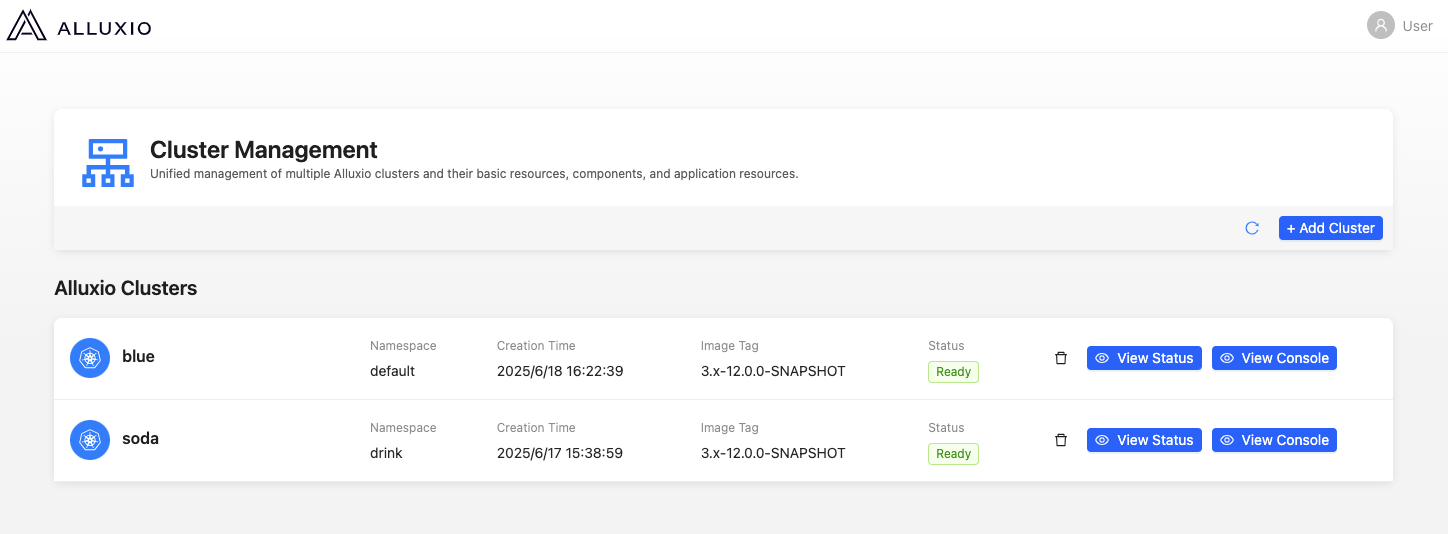
The Alluxio WebUI has been significantly enhanced with new deployment and configuration modules that streamline cluster management. After installing the Alluxio K8s Operator, administrators can use the intuitive WebUI to configure cluster parameters, allocate resources, and customize deployments for specific workload requirements, making Alluxio deployment faster, simpler, and more accurate than ever before.
Deploy new Alluxio clusters directly through the WebUI with guided workflows that ensure optimal configuration for your AI workloads. The interface walks you through each step, from initial setup to advanced tuning, reducing deployment time and configuration errors.
Audit and Analyze All User Data Access & Operations Using Audit Log
The new Comprehensive Audit Log feature provides complete visibility into all data access and operations performed through Alluxio. Every interaction is automatically recorded with:
- User identities and authentication details
- Operations performed (read, write, delete, etc.)
- Precise timestamps
- Accessed resources and paths
This detailed logging enables security teams to detect anomalies, investigate incidents, and demonstrate compliance with regulatory requirements, which are essential for enterprise AI deployments handling sensitive data.
Get Started with Alluxio Enterprise AI 3.7
Alluxio has always been known for delivering high throughput to AI workloads. In Alluxio Enterprise AI 3.7, we now support sub-millisecond TTFB latency on S3 through the new Alluxio Low-Latency Caching for Cloud Storage, along with cache preloading and new security features. Whether you're training foundation models, deploying inference services, or building feature stores, these new capabilities ensure your AI workloads run at peak efficiency.
Ready to accelerate your AI? Contact us to learn more about upgrading to Alluxio Enterprise AI 3.7.
.png)
Blog



Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading