Blog

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.
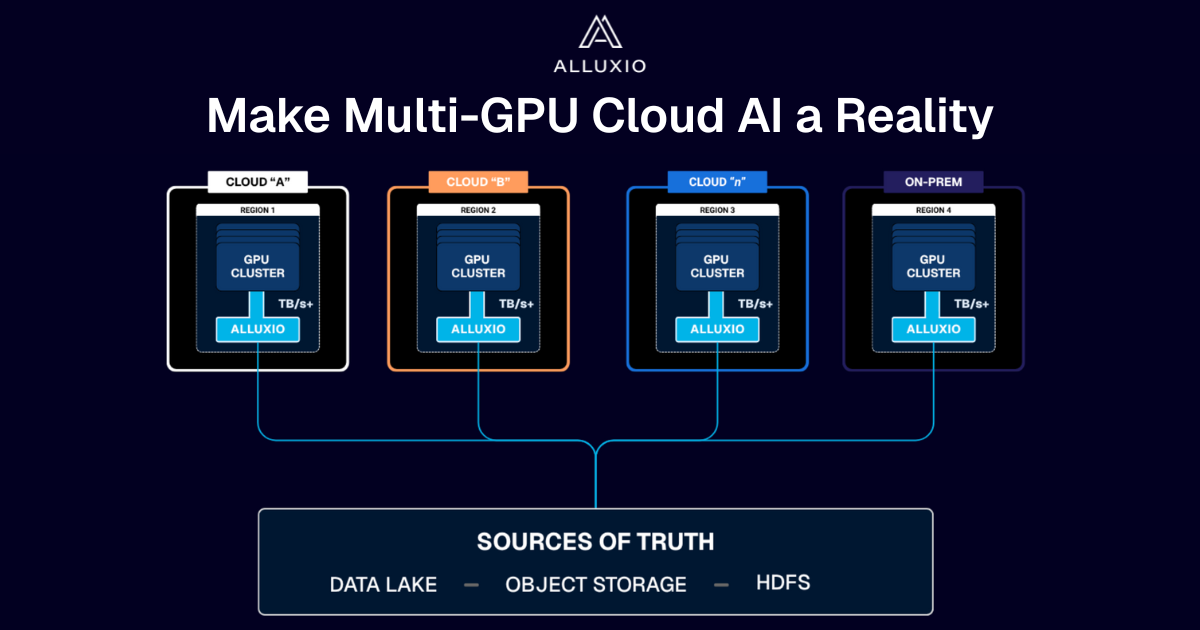
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver. What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. In this article, learn how Alluxio brings Simplicity, Speed, and Scale to Multi-GPU Cloud deployments.

.png)
.jpeg)
This article introduces Structured Data Management available in the latest Alluxio 2.2.0 release, a new effort to provide further benefits to SQL and structured data workloads using Alluxio.
.jpeg)
With this release comes the General Availability (GA) of Alluxio Structured Data Services (SDS), the subsystem of Alluxio responsible for managing and transforming structured data, such as databases, tables, and partitions.
TL;DR: First the news - Alluxio support for K8s Helm charts now available! K8s is a certified environment for Alluxio. Now the take away- Alluxio brings back data locality for the disaggregated analytics stack in K8s. How? Read on.
.jpeg)
We are delighted by the success of the inaugural Data Orchestration Summit on Nov. 7, 2019! Organized by Alluxio, this one-day event was sold out with nearly 400 attendees! Data engineers, cloud engineers, data scientists joined the talks of 24 industry leaders from all over the globe to share their experiences building cloud-native data and AI platforms. All session recordings and slides are now available.


This tutorial guides users to set up a stack of Presto, Alluxio and Hive Metastore on your local server, and it demonstrates how to use Alluxio as the caching layer for Presto queries.
For today’s blog post I interviewed Bin Fan, Founding Engineer and VP of Open Source at Alluxio. Bin is the PMC maintainer of the Alluxio open source project. Prior to Alluxio, he worked for Google on the next-generation storage infrastructure.
.jpeg)
This tutorial describes steps to set up an EMR cluster with Alluxio as a distributed caching layer for Hive, and run sample queries to access data in S3 through Alluxio.
This article describes my lessons from a previous project which moved a data pipeline originally running on a Hadoop cluster managed by my team, to AWS using EMR and S3. The goal was to leverage the elasticity of EMR to offload the operational work, as well as make S3 a data lake where different teams can easily share data across projects.
.jpeg)