We're thrilled to share that Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads. This collaboration between engineering teams showcases the power of combining Alluxio's data acceleration layer with OCI's high-performance bare-metal infrastructure, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.

The benchmark results speak for themselves: Alluxio on OCI achieved 0.3ms average latency for single-node deployments in the WARP benchmark and scaled to 61.6 GB/s throughput across six nodes while maintaining GPU utilization above 90% in MLPerf Storage 2.0 testing.
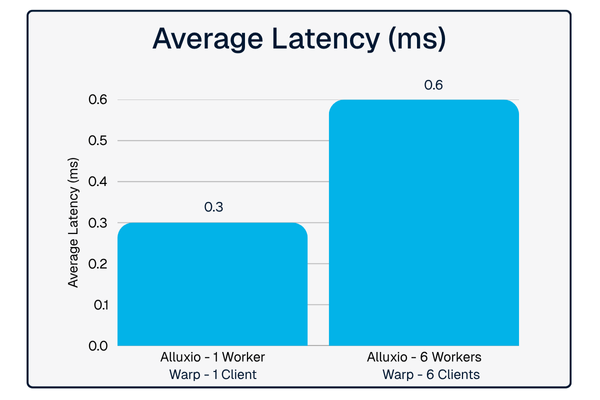
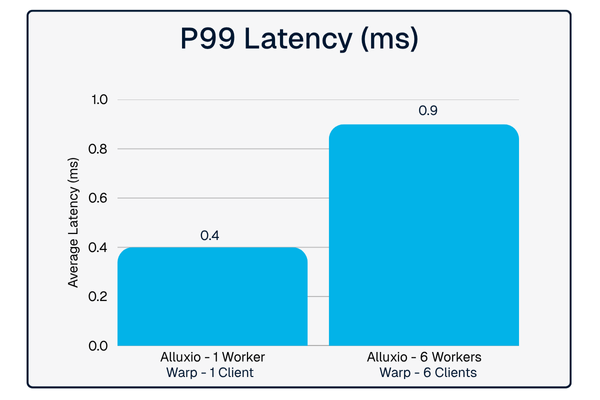

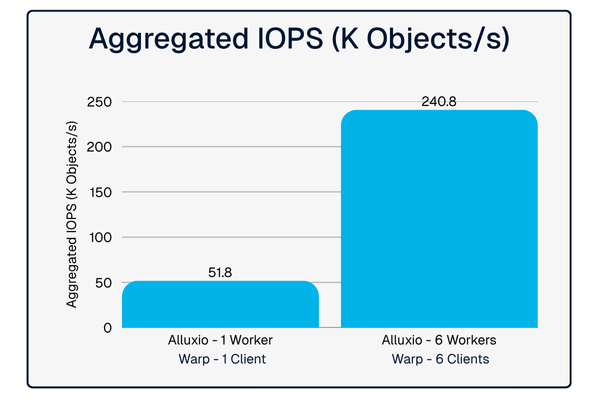
What makes this particularly exciting is the flexibility it offers customers. Whether deploying in dedicated mode for maximum performance or co-located mode for cost efficiency, OCI customers eliminate data access bottlenecks with Alluxio - all without migrating data or changing application code. This is exactly the kind of plug-and-play integration that accelerates time-to-value for AI infrastructure.
The combination of Alluxio and OCI addresses one of the most critical challenges in AI infrastructure today: keeping expensive GPU resources fully utilized. By creating a high-performance caching layer between compute and object storage, we're helping organizations maximize their cloud investments and accelerate model training cycles and inference workloads.
We're grateful to the Oracle team, including Xinghong He, Pinkesh Valdria, and the entire OCI GPU Storage team, for their collaboration on these benchmarks.
Read the full technical blog to explore the detailed results and learn how to deploy Alluxio on OCI for your AI workloads.
.png)


