TL;DR: In this blog, Greg Lindstrom, Vice President of ML Trading at Blackout Power Trading, an electricity trading firm in North American power markets, shares how they leverage Alluxio to power their offline feature store. This approach delivers multi-join query performance in the double-digit millisecond range, while maintaining the cost and durability benefits of Amazon S3 for persistent storage. As a result, they achieved a 22 to 37x reduction in large-join query latency for training and a 37 to 83x reduction in large-join query latency for inference.
Challenge: S3 Latency When Serving Model Artifacts and Inputs Limits ML Trading Scalability
At Blackout Power Trading, we execute day-ahead electricity trades across thousands of U.S. grid locations. Each morning, within a fixed 15-minute market window, we run thousands of ML models using the latest weather and renewable generation forecasts. Today, our ML pipeline processes 500+ GB of feature data stored as Parquet files and models on Amazon S3.
Performance Requirements
- Training: Our current capacity is training ~5,000 models at once, and our roadmap aims for 100,000+. The feature store must deliver 30+ training sets/sec to support large-scale training and hyperparameter sweeps.
- Inference: During the trading window, we must serve features to thousands of models while simultaneously loading serialized models from the registry. Scaling to 100,000 models in 15 minutes requires 111 models/sec, each performing joins across numerous Parquet files in S3.
- Baseline query complexity: A typical feature retrieval is a 20-table join, with four features per table, producing 81 output columns (80 features plus one primary key).
Scaling Bottlenecks
Direct feature retrieval from S3-hosted Parquet files introduced unacceptable latency, underutilized compute during training/inference, and capped our ability to scale. Pre-caching with Ray’s object store reduced some delays, but quickly hit two hard constraints:
- S3 bandwidth limitations when bulk-loading features into memory.
- Memory capacity ceilings on cost-effective spot instances, forcing complex workarounds and reducing flexibility.
In addition, concurrent S3 writes risked file corruption, requiring a custom Amazon SQS–based queuing system, a “makeshift feature store” that, while functional, lacked the durability and fault tolerance needed for mission-critical operations.
Operational Risks
Our trading workloads have zero tolerance for service degradation during the inference window. Any delays, data inconsistencies, or outages can directly translate into significant financial loss. Current approaches increase operational complexity, consume excess memory, and fail to guarantee consistent performance under node failures or cluster rebalancing events.
Key Challenges & Needs
From these limitations, our required capabilities are clear:
- High availability: Our platform must tolerate node failures during the inference window without service disruption.
- Low-latency access: Feature store queries and model artifact loads must meet predictable latency targets.
- Offline feature store only: We only want an offline feature store, not an online one, to reduce system complexity and memory costs.
- Elastic scaling: The cluster should scale up/down to match workload, ensuring we only pay for resources when in use.
- 10x+ growth capacity: Architecture must support scaling beyond 100,000 models without redesign.
- Strong consistency: Concurrent read/writes against plain Parquet files must remain consistent while sustaining high throughput.
- Platform integration: The solution must integrate cleanly across our existing tools and infrastructure.
Solution: A Low-Latency Distributed Feature Store Powered by Alluxio Low Latency Caching
We have built a dynamically scalable, distributed feature store designed for low-latency ML training and inference. By leveraging Alluxio’s distributed caching on NVMe SSDs, we removed S3 as a performance bottleneck, delivering double-digit millisecond feature view query speeds and meeting our aggressive latency and scaling targets.
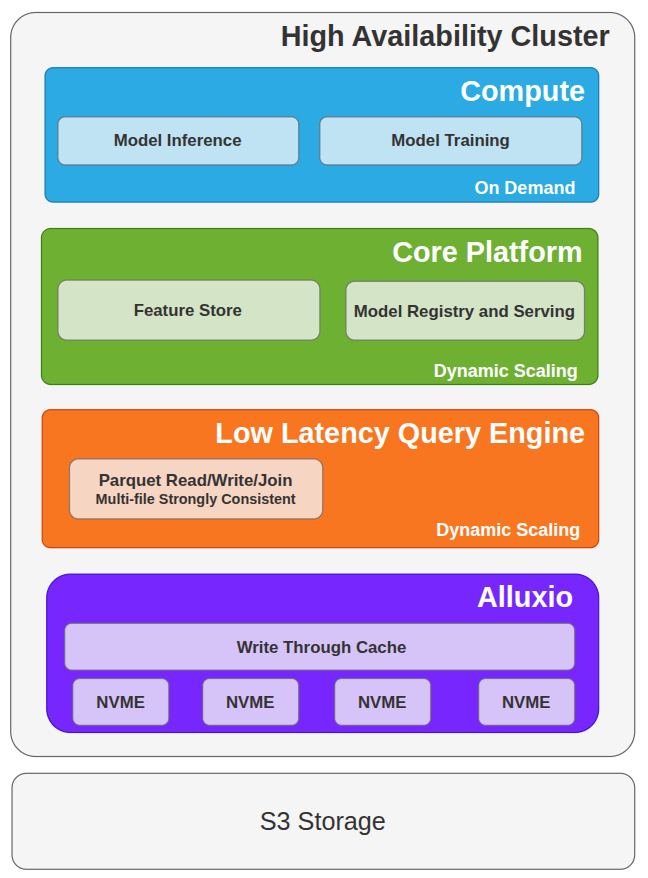
Our architecture follows a Python dataframe–first approach. A Rust-based query engine integrates with Alluxio via its POSIX (FUSE) interface, enabling our pipelines to read S3 data as if it were on a local file system. This provides the predictable, low-latency access needed for both model artifacts and feature inputs. Concurrency and consistency are maintained through a distributed multi-resource locking system, allowing us to use plain Parquet files for maximum performance and minimal latency.
Alluxio operates as a transparent caching layer between compute and object storage. It doesn’t replace S3—instead, it accelerates it, caching frequently accessed data on local NVMe drives in our compute cluster. This setup supports highly concurrent reads during the critical inference window while using write-through persistence to reliably store models and outputs back to S3.
Why Alluxio
- Low-latency reads: Double-digit millisecond access to Parquet data, even for multi-join training and inference queries.
- Unified access: API translation layer presents S3 objects with local file system semantics.
- Lightweight deployment: Local disk caching without heavy operational overhead.
- Seamless integration: Dropped into our existing ML platform with minimal refactoring.
Results: Millisecond Joins, 10× Model Capacity, and Smarter Compute Utilization
Deploying Alluxio delivered step-change improvements in both latency and scale across our ML pipeline.
Training
Large join operations across 20 tables (70,000 rows, 81 output columns) now complete in 171 ms with cold reads (data cached in Alluxio workers but not in FUSE clients), down from 3.84 seconds querying directly from S3. That's a 22× speedup. Performance improves further with hot reads (data cached in FUSE clients), dropping to just 104 ms for a 37× improvement over S3. This dramatic speedup unlocks far better utilization of our training clusters and reduces idle time between jobs.
Inference
In our critical 15-minute trading window, the impact is even greater. Complex joins across 20 tables for inference queries now finish in 99 ms with cold reads, versus 3.73 seconds from S3, a 37× improvement. With hot reads, latency drops to an impressive 45 ms, delivering an 83× speedup over direct S3 access. This enables us to run far more models and perform deeper risk analysis before market close.
Benchmark Summary
Notes:
*Tables are in Parquet format with 70,000 rows, one timestamp column, 200 feature columns (float64), compressed with zstd to ~30MB. Get Dataframe is the amount of time for the Python Client to query and load the Dataframe into the Python environment from the query engine.
** Files are cached in Alluxio workers' NVME storage but not cached in Alluxio FUSE clients.
*** After one cold-read, file blocks will also be cached in Alluxio FUSE clients.
Impact
- 22 to 37× reduction in large-join query latency for training.
- 37 to 83× reduction in large-join query latency for inference.
- 10× increase in model capacity, scaling from 10,000 to 100,000+ models in the same 15-minute window.
By cutting query times to double-digit milliseconds, we removed the data bottleneck between training and inference. This directly improves decision quality and revenue potential, while maintaining a lean, cost-efficient infrastructure.
Summary
Alluxio has been a key enabler in delivering the low-latency feature store required for our ML trading models. By providing double-digit millisecond latency for multi-join queries in our offline feature store, we can now scale beyond 100,000 models within our 15-minute trading window.
Its lightweight deployment aligns perfectly with our lean infrastructure strategy, and seamless integration with our existing platform and tooling made adoption straightforward. Most importantly, the time saved through Alluxio’s caching layer translates directly into more time for risk analysis, and ultimately, better trading decisions.
About Blackout Power Trading
Blackout Power Trading Inc. is a private capital commodity trading fund based in Calgary, Alberta, Canada, specializing in North American power markets. We participate in daily electricity auctions throughout the year, with traders operating independently using their own technology stacks. Focused on day-ahead virtual power and congestion markets, we leverage advanced machine learning strategies to inform trading decisions and create more efficient electricity markets through our speculative trading activities.
About the Author
Greg Lindstrom is Vice President of ML Trading at Blackout Power Trading, specializing in North American power markets with advanced machine learning strategies, focusing on day-ahead virtual power and congestion markets.
.png)
Blog



Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading