For many of our customers, Alluxio has been primarily used as a distributed, S3-compatible read cache on top of cloud object storage, with write-through semantics to preserve durability. We previously analyzed Alluxio’s performance characteristics and architectural trade-offs for read-heavy workloads in “Alluxio + S3: A Tiered Architecture for Latency-Critical, Semantically Rich Workloads.”
Modern AI and analytics pipelines are increasingly read–write mixed or write-heavy, making the performance characteristics of backend object storage—especially write latency and burst handling—a dominant factor in end-to-end runtime. For example, a pipeline that writes millions of files to S3 after preprocessing a large dataset typically sees 30–40 ms latency for 10 KB PUTs under moderate concurrency, even before tail latency is considered. Under higher concurrency, PUT requests may be throttled or fail due to rate limits. As a result, job runtime, write time, and recovery time are often bound by object storage behavior rather than available compute or local I/O capacity.
Alluxio S3 Write Cache introduces optional, user-configurable write-back modes alongside the existing write-through behavior. These new modes allow PUT requests to be handled locally on compute-side storage, while persistence to object storage is performed asynchronously or skipped when appropriate.
The impact is transformative. Small object PUT latency drops to approximately 4–6 ms with Alluxio S3 Write Cache, representing a ~5-8X improvement, while large object writes sustain over 6 GB/s per Alluxio worker at low and stable latency, scaling near-linearly as additional Alluxio workers are added.
This post explains why write-heavy workloads expose fundamental limits in the object storage write path, and how Alluxio S3 Write Cache changes the write and read-after-write latency model to address those limits in practice.
A Real-world Example: Handling Bursty PUTs at Scale
Consider a fast-growing, consumer-facing application where users continuously upload files—such as images—to a cloud-based object store. Under steady-state conditions, the system handles approximately 10,000 PUT requests per second in its bucket, with an average object size of 1 MB. During peak events—such as viral content, regional promotions, or time-zone overlaps—traffic can spike by 3–10X within minutes.
Using object storage directly in this scenario exposes several fundamental bottlenecks.
- Write latency dominates the request path. Each upload must synchronously traverse the network and wait for acknowledgment from the object storage service, making write latency a critical component of end-to-end request time.
- Backend rate limits become user-facing failures. Even if average throughput is within service limits, burst traffic can overwhelm the storage backend, resulting in throttling, retries, elevated tail latency, or transient errors.
- Overprovisioning becomes the only mitigation. To survive peak traffic, teams are forced to provision the storage backend for worst-case load, even though such spikes occur infrequently. This increases cost without improving steady-state efficiency.
In this customer’s architecture, object storage was accessed through a thin, S3-compatible gateway with no buffering or traffic shaping. Under burst conditions, the backend could not absorb the sudden influx of concurrent writes and user uploads would begin to fail.
As a result, the customer needed a distributed write cache in front of their rate-limited object store, one that could absorb bursty uploads during peak hours, persist data to object storage after the burst subsides, and support immediate read-after-write access, all while preserving S3-compatible semantics with little or no change to the existing pipeline.
PUT a Transparent Write Cache in front of Object Stores
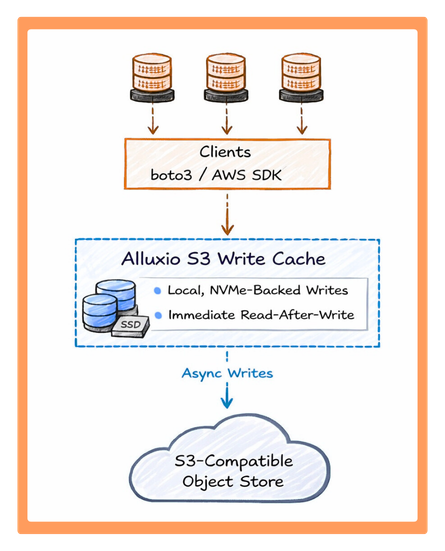
Alluxio S3 Write Cache lives compute-side (layered between applications and S3-compatible object storage) with the charter of reducing write and read-after-write latency without changing how applications interact with S3.
From the application’s point of view, the interface remains exactly the same:
- You continue to use boto3 or the AWS SDK
- You continue to interact with an S3-compatible endpoint
There is no new API, no client-side logic, and no application-level awareness of caching or persistence behavior. With Alluxio S3 Write Cache:
- PUT requests are handled by Alluxio workers and stored on local NVMe
- Data can be replicated across workers for durability (optional)
- Bursty and highly concurrent writes are absorbed at the Alluxio layer
- Data is persisted asynchronously to object storage at a controlled, sustainable rate
- Cache space is reclaimed after persistence to make room for new writes
This fundamentally decouples frontend write performance from backend object storage limits, while preserving full S3 compatibility.
What this enables:
- Low-Latency Writes at Cluster-Local Storage Speed Write requests are first stored on NVMe of Alluxio workers. Bursty and highly concurrent writes are absorbed without overwhelming the backend storage.
- Fast and Predictable Read-After-Write Data written to cache is immediately readable. Read-after-write behaves like local storage rather than remote object storage, which is critical for checkpoints and multi-stage pipelines.
- Asynchronous Persistence with S3 as the System of Record Object storage remains the durable backend. However, write performance and persistence are decoupled through asynchronous write-back, enabling fast writes with eventual consistency.
- Targeted Acceleration via Path-Based Configuration Write acceleration is applied only where it matters. Different data types—checkpoints, temporary data, and archival data—can follow different write and lifecycle semantics.
Benchmarks
To understand how Alluxio S3 Write Cache changes write and read-after-write behavior, we ran a set of microbenchmarks using Warp, comparing Alluxio S3 Write Cache against AWS S3.
Test Setup
- Workload: PUT / GET on small objects (10 KB)
- Baseline: AWS S3
- Alluxio configuration: write cache enabled, single replica
- Environment:
- 1 Alluxio Worker: i3en.metal
- 1 Warp Client: c5n.metal
All tests were run within the same AWS region to minimize cross-region effects.
Test-1:PUT Latency (10 KB)
Takeaway:Alluxio keeps PUT latency in the single-digit millisecond range across most concurrency levels, while S3 latency remains in the tens of milliseconds and degrades sharply under load.
Figure 2: Small Object PUT Latency Drops 7–8× Under Concurrency
This test measures PUT latency for 10 KB objects as concurrency increases from 1 to 256. Note that concurrency represents the number of outstanding PUT/GET requests issued by the Warp client.
- With Direct S3, PUT latency stays around 30–35 ms at low concurrency and rises sharply under load, exceeding 70 ms at 256 concurrent writers.
- With Alluxio S3 Write Cache, latency remains in the 4–6 ms range at low to moderate concurrency, increasing gradually only at very high concurrency.
Why this matters:
For workloads dominated by small object writes—metadata updates, checkpoints, or task outputs—this translates directly into shorter job runtime and faster recovery, not just higher peak throughput. The key difference is not just lower average latency, but significantly more predictable latency under concurrency.
Test-2:Read-After-Write Latency (10 KB)
Takeaway: Read-after-write shifts from an object-storage operation to a storage operation close to compute.
Figure 3: Read-After-Write Becomes 10X Faster under Concurrency
This test measures read latency (GET) immediately after a write (PUT) for the same 10 KB objects.
- With S3, read latency remains in the ~25–50 ms range, reflecting object storage access semantics. In this test, S3 read latency improves slightly at higher concurrency due to backend warm-up effects. The test repeatedly reads the same objects, allowing S3 to apply internal optimizations for hot data. This behavior is expected and does not affect the relative latency gap between S3 and Alluxio. (See AWS documentation on S3 performance optimizations for frequently accessed objects.)
- With Alluxio, read-after-write latency is 1–2 ms at low concurrency and remains well below 10 ms even as concurrency increases.
Why this matters:
For pipelines with immediate data dependencies—such as training checkpoints or multi-stage ETL—read-after-write latency often dominates end-to-end execution time. Alluxio removes this dependency on object storage.
Test-3: Scaling Write and Read-After-Write Throughput with Multiple Workers
Takeaway: Aggregate write and read-after-write throughput scales with the number of Alluxio workers, allowing capacity to be increased by scaling the compute layer rather than overloading object storage.
Beyond single-node behavior, we evaluated how throughput (IOPS of PUT and GET for 10 KB objects) changes when more Alluxio workers are deployed in the cluster. In this test, we compare a single-worker cluster with a three-worker cluster while increasing client concurrency.
This figure shows both write throughput (PUT 10 KB) and read-after-write throughput, measured in IOPS, as client concurrency increases.
- For both write and read-after-write workloads, three workers consistently deliver ~3× higher aggregate throughput than a single worker at the same concurrency.
- Throughput scales proportionally with the number of workers until bounded by client-side concurrency or background persistence capacity.
- Importantly, this scaling is achieved without pushing additional burst load directly to object storage, since writes are absorbed and staged at the Alluxio layer.
Why this matters:
For write-heavy and burst-prone workloads, scaling write capacity by adding Alluxio workers shifts the bottleneck from the storage backend to the compute layer. This allows systems to handle higher write rates and concurrent access patterns without triggering object-store throttling or tail-latency amplification.
Summary of Benchmark Results
- Small object PUT latency drops from ~30–40 ms (Standard S3 PUT) to ~4–6 ms with Alluxio
- Read-after-write latency shifts from object storage scale to local storage scale at single ms
- Latency degradation under concurrency is significantly smoother with Alluxio
- Throughput scales horizontally by adding workers, rather than overloading the storage backend
Together, these results show that Alluxio S3 Write Cache primarily improves the latency model and predictability of write-heavy workloads, rather than simply chasing peak bandwidth numbers.
Final Takeaway
Compare Alluxio Write Cache vs S3
When Alluxio Write Cache Is a Fit
Alluxio Write Cache shines when your workload is:
- Sensitive to write latency or write-then-read
- Highly concurrent and bursty writes
- Local NVMes are available but limited in size compared to entire datasets
- S3 or other objects store as the durable source of truth.
Ready to eliminate S3 write bottlenecks in your pipeline? For more information and how to use this feature, please Contact us for a Demo.
.png)
Blog



Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading