Checkpointing Is the Hidden Cost of Large-Scale Training
Modern distributed training jobs spend a surprising fraction of wall-clock time not training. They spend it writing checkpoints — and waiting on them.
Every checkpoint cycle forces a synchronous write of multi-hundred-gigabyte model state across hundreds of GPUs to backing storage. Frameworks like PyTorch Distributed Checkpoint, DeepSpeed, and Megatron-LM all checkpoint through a POSIX file system interface, which means the write path runs through whatever shared file system is mounted on the training nodes. When that file system is backed by object storage or a remote parallel file system, every checkpoint becomes a network-bound operation that stalls the entire training job until the slowest rank finishes writing.
The downstream effects compound. Read-after-write paths — restart recovery, fine-tuning resumption, evaluation jobs that consume checkpoints written moments earlier — all inherit the same latency profile, multiplying GPU idle time across the cluster.
With Alluxio AI 3.9, we're directly addressing this bottleneck.
What's New in Alluxio AI 3.9
Alluxio AI 3.9 introduces two new capabilities:
- POSIX Write Cache — extends Alluxio's write cache architecture, introduced in 3.8 for S3 workloads, to the POSIX file system interface used by virtually every distributed training framework.
- RDMA Support for Read I/O — adds RDMA transport for read paths, enabling near-line-rate throughput on RDMA-capable training clusters.
POSIX Write Cache: Bringing Write Acceleration to the Training Stack
In Alluxio AI 3.8, we introduced Alluxio S3 Write Cache, which decouples application write performance from object storage limits by absorbing PUTs on local NVMe at the Alluxio worker layer and persisting asynchronously to S3. That release dramatically reduced PUT latency and read-after-write latency for S3-based AI pipelines.
But distributed training doesn't write through S3. It writes through POSIX. PyTorch, DeepSpeed, Megatron, Ray Train, and the storage tooling around them all expect a mounted file system. Until now, training teams running on Alluxio could accelerate reads through Alluxio's POSIX FUSE interface but had no equivalent write-side acceleration — checkpoint writes still synchronously traversed the network to backing storage.
Alluxio AI 3.9 closes that gap. POSIX Write Cache brings the same write-back architecture from 3.8 to the POSIX path: training jobs write checkpoints to a POSIX-mounted Alluxio file system, those writes land on compute-side NVMe within the Alluxio worker pool, and persistence to the durable backend happens asynchronously in the background. From the training framework's point of view, nothing changes — the file system mount works exactly as before. What changes is how fast writes complete.
Why Checkpointing Stalls GPU Training
The economics of GPU training make checkpoint latency unusually expensive. A 70B-parameter model checkpoint can exceed 250 GB. When that checkpoint is written synchronously through a remote file system, the entire training step blocks on the slowest writer in the cluster. Hundreds of H100s sit idle waiting for I/O to complete.
This isn't a peak-capacity problem — it's a steady-state problem. Most large training jobs checkpoint every few hundred to few thousand steps, which means the storage write path is exercised continuously throughout the run. Slow checkpoints don't just delay recovery; they directly reduce effective training throughput.
POSIX Write Cache attacks this on two fronts: writes terminate at local NVMe speed rather than network speed, and read-after-write — restart, resumption, downstream consumption — runs at local NVMe speed as well.
Benchmark Results: 7.6 GiB/s on a Single Node, Scaling Linearly to 20 GiB/s
To validate POSIX Write Cache performance under realistic checkpoint-like workloads, we ran FIO benchmarks at 256KB block size against the Alluxio POSIX interface.
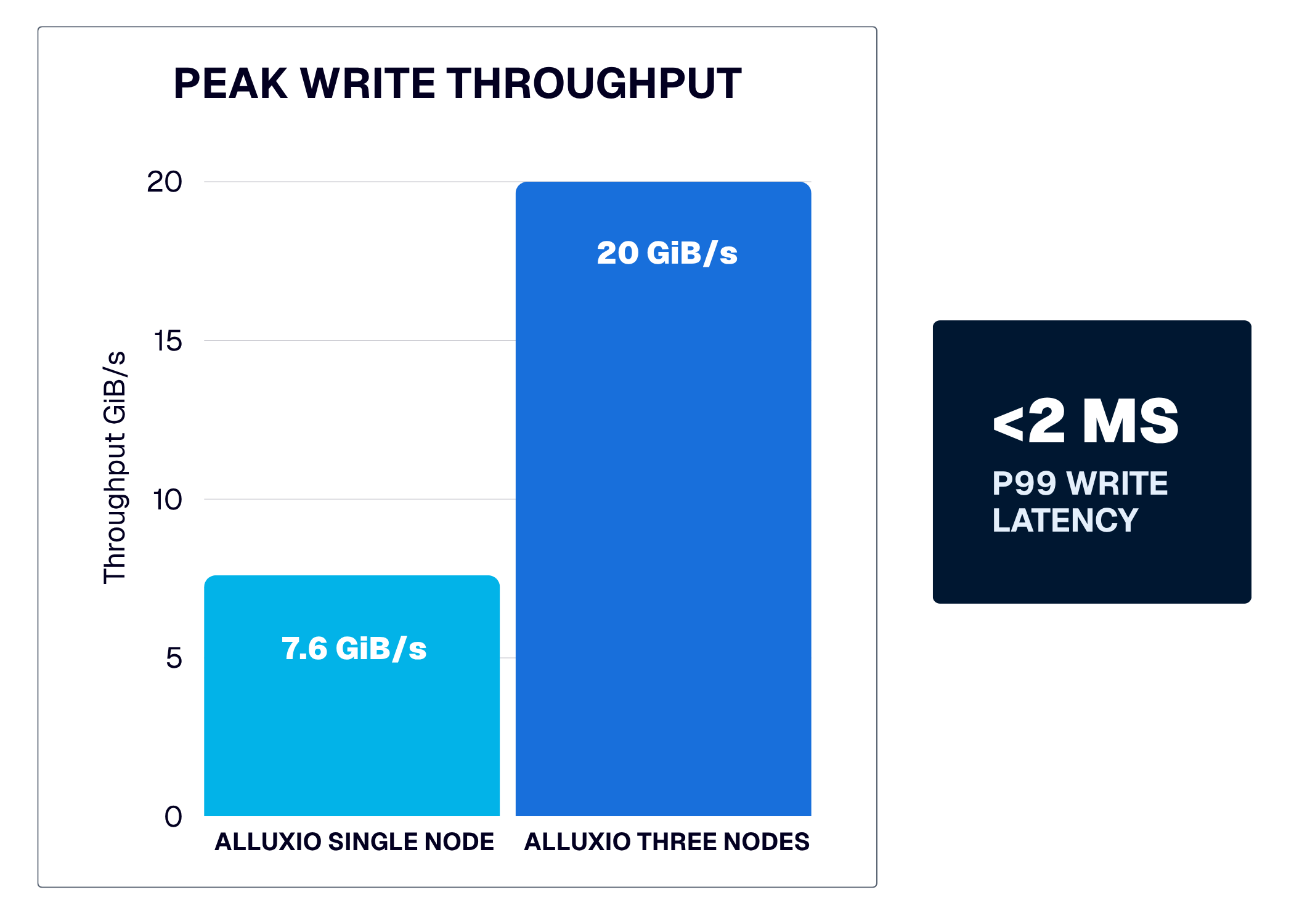
Alluxio cluster: i3en.24xlarge worker, c5n.18xlarge client
Two takeaways. First, throughput scales near-linearly with worker count — 3x the workers, ~2.6x the aggregate throughput — confirming that capacity grows with the compute layer rather than being bottlenecked at the storage backend. Second, P99 latency stays under 2 ms at both scales. This is the more important result for checkpoint workloads: tail latency, not average latency, determines how long a synchronous checkpoint step takes, because the slowest rank gates the entire job.
What This Enables for AI Teams
For distributed training operators, POSIX Write Cache translates into concrete operational outcomes:
- Faster checkpoint cycles, allowing more frequent checkpointing without sacrificing training throughput
- Faster job recovery and resumption after preemption, hardware failure, or planned restarts
- Higher effective GPU utilization by eliminating idle time during synchronous checkpoint writes
- Predictable performance under bursty I/O, since writes are absorbed at the Alluxio layer rather than queued against the backend
RDMA Support for Read Workloads
Alluxio AI 3.9 also introduces RDMA transport for read I/O, targeting GPU clusters with InfiniBand or RoCE v2 networking. By bypassing the kernel networking stack, RDMA eliminates CPU overhead and memory copies on the data path, keeping GPUs saturated during training and inference. This release applies RDMA acceleration to all FUSE client read I/O between clients and Alluxio workers, along with metadata operations like file status and directory listing.
The benchmark results are strong. On Azure VMs with Mellanox ConnectX-6 and ConnectX-7 NICs, RDMA reaches 23.2 GB/s on 200 Gbps InfiniBand — 92.8% of link capacity — and 49.5 GB/s on 400 Gbps NDR, 99.0% of link capacity. Tail latency stays tight: sub-100µs P99 on 4KB reads (64µs at 200G, 59µs at 400G), which matters for checkpoint metadata access and small-file training datasets where per-operation overhead dominates.
The RDMA-versus-TCP comparison is where the protocol benefit shows up most clearly. At peak bandwidth utilization, RDMA reaches 92.8% versus TCP's 76.8% — a 16 percentage point efficiency advantage that widens to 24–29 percentage points under production-scale concurrency, because TCP performance degrades past concurrency 16 while RDMA continues to scale.
RDMA transport is additive. It coexists with the standard TCP transport, falls back automatically if RDMA hardware is unavailable, and requires no migration or API changes — existing FUSE mounts and S3-compatible access paths continue to work. Write-side RDMA support is planned for a future release; in 3.9, write I/O — including POSIX Write Cache writes — continues to use TCP transport.
Summary
Alluxio AI 3.9 finishes what 3.8 started. S3 Write Cache eliminated the object storage write bottleneck for cloud-native pipelines. POSIX Write Cache eliminates the same bottleneck for the distributed training stack, where it shows up most painfully — in synchronous checkpoint writes that gate GPU training throughput. With 7.6 GiB/s per worker, near-linear scaling to 20 GiB/s across three workers, and sub-2ms P99 latency, checkpoint writes no longer need to be the slowest part of a training step.
Ready to remove the checkpoint bottleneck from your training infrastructure? Request a DEMO to see Alluxio AI 3.9 in action, or read the technical deep dive on the write cache architecture in Introducing Alluxio S3 Write Cache.
.png)
Blog



Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading