RedNote Accelerates Model Training & Distribution with Alluxio
Accelerate Search & Recommendation Model Training and Fine-Tuning
Serve the most accurate search and recommendation results by accelerating model training and fine-tuning.
Accelerated by Alluxio




Why Alluxio for Search & Recommendation
Accurate and up-to-date search and recommendation results requires training and fine-tuning your models with the latest data based on user interactions and preferences. Can your storage keep up?
Increase GPU Utilization with Faster Data Access
Boost GPU utilization by eliminating storage and network bottlenecks that prevent training code from fully leveraging your precious GPU resources.
Faster Model Training & Fine-Tuning Time
Alluxio customers achieve up to 4X faster training & fine-tuning time through Alluxio's distributed caching for model training data
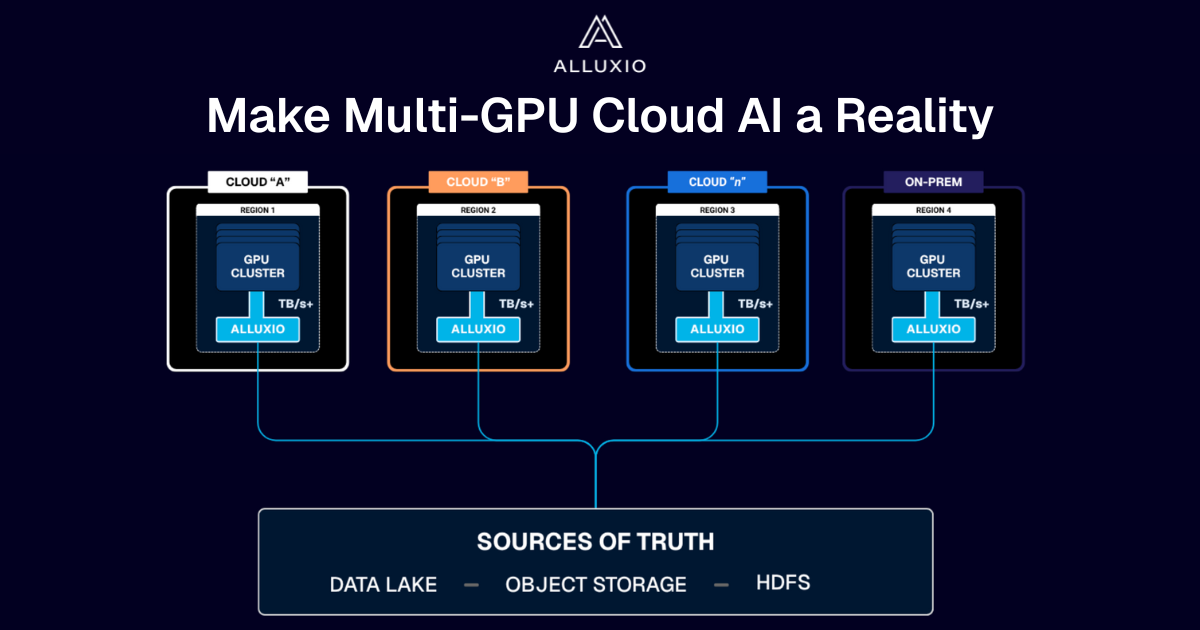
Get Seamless Data Locality in Hybrid and Multi-Cloud Infra
Eliminate complex replication and costly storage solutions with Alluxio's distributed cache automatically bringing the right data to the right place at the right time.
Alluxio accelerates search & recommendation model training & fine-tuning for leading enterprises across the globe


How Alluxio works
Alluxio Enterprise AI is an intelligent caching layer that can be seamlessly installed in your existing AI and data infrastructure with zero code changes to applications. Sitting between GPU compute and storage, Alluxio accelerates training data access across storage systems, bringing data closer to GPU compute.

Only retrieve data when necessary, greatly reducing the number of API calls directly on cloud object storage and the amount of data transferred across regions and clouds. Costs, including head object, get object, head bucket, and get bucket calls, are reduced by 80~90%

Alluxio provides a built-in dashboard with data acceleration insights.

Seamlessly integrate with AI frameworks (PyTorch/Ray/TensorFlow) and works with major public cloud providers like AWS, Google Cloud and Microsoft Azure

Talk with an Alluxio AI expert.
Schedule Call