

Global Top 10 E-Commerce Giant Accelerates Training of Search & Recommendation AI Model with Alluxio
Alluxio is the fastest, most efficient way to deliver AI data to GPUs to accelerate AI model training, model distribution, and inference.
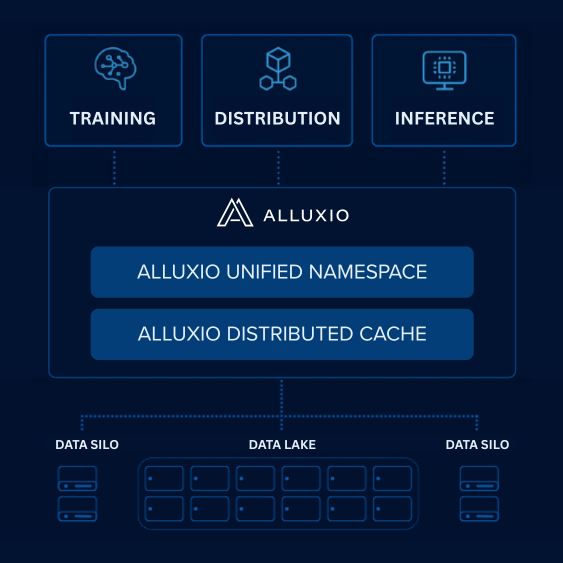




Alluxio Distributed Cache accelerates AI workloads and maximizes GPU utilization by delivering lightning-speed access to petabytes of data spread across billions of files regardless of the underlying storage type or proximity to GPU compute clusters.


Get to market faster, boost productivity, and reduce repetitive data engineering tasks by providing AI builders with a secure, unified POSIX interface to all your data sources regardless of storage type or protocol.
Move your AI workloads between regions, clouds, and on-premise infrastructure (or wherever you can find GPUs) while keeping your data where it is. Alluxio delivers accelerated access to the data your AI workloads need wherever it lives.


Alluxio Distributed Cache reduces costly data access and egress charges imposed by public cloud storage solutions, while accelerated data access eliminates the need for expensive, complex HPC storage.
Simple to deploy and easy to manage, the Alluxio AI Acceleration Platform leverages NVMe SSDs on or near existing GPU compute clusters to accelerate data access without replicating data or requiring additional persistent storage

Alluxio accelerates PyTorch, TensorFlow, Spark, and Ray workloads running on bare-metal, virtual machines, and Kubernetes. Alluxio supports single cloud, multi-cloud, hybrid-cloud, or completely on-premise environments.





While AI and big data analytics have different workload characteristics, both suffer from performance and scalability challenges accessing vast quantities of data. Alluxio Data Analytics Edition is optimized to bring the speed, flexibility, and cost-saving benefits of Alluxio to big data analytics workloads.


























.jpeg)









