Inferless, a fast-growing platform for serverless AI inference, leveraged Alluxio to dramatically reduce cold start latency for large language model (LLM) workloads—unlocking a faster, more efficient user experience while simplifying its hybrid-cloud architecture.
Challenge
Model loading delays and cloud I/O costs were slowing down LLM inference
Inferless provides developers with a serverless platform to run AI models at scale—automatically spinning up and down GPU resources to handle inference requests without the overhead of managing infrastructure. But as the platform scaled to support increasingly large LLMs, it faced a critical challenge: slow and costly cold starts.
Each time a new container was spun up to serve an LLM, model weights—often several gigabytes—had to be fetched from cloud object storage like Amazon S3 or Hugging Face. This created cold starts of 10 to 30 seconds, degrading the end-user experience. To address this, Inferless evaluated multiple solutions, including Amazon FSx for Lustre, a high-performance shared file system.
However, FSx required tight integration with AWS services, lacked multi-cloud portability, and did not offer a cache hierarchy optimized for inference latency at the node level—particularly in serverless or hybrid-cloud settings.
Key pain points:
- Slow cold starts from repeatedly loading LLMs
- High latency and egress costs from object storage
- FSx offered performance but limited flexibility in hybrid/multi-cloud setups
Solution
A high-performance, cloud-agnostic cache layer for LLM inference
Inferless chose Alluxio AI as a distributed caching layer between its inference platform and remote model repositories like S3 and Hugging Face. With Alluxio, models were cached automatically after first access, eliminating repeated downloads and drastically improving cold start times.
Unlike FSx, Alluxio allowed Inferless to cache data close to compute on each node, offering faster access while retaining flexibility across different clouds and edge locations. This made it an ideal solution for their hybrid-cloud architecture, where workloads can shift between AWS and other environments without rearchitecting data access.
Why Alluxio:
- 6-12x faster model loading compared to S3
- Flexible deployment across hybrid-cloud and multi-cloud environments
- Transparent integration with existing model serving pipelines
- Fine-grained caching on GPU nodes without reliance on shared filesystems
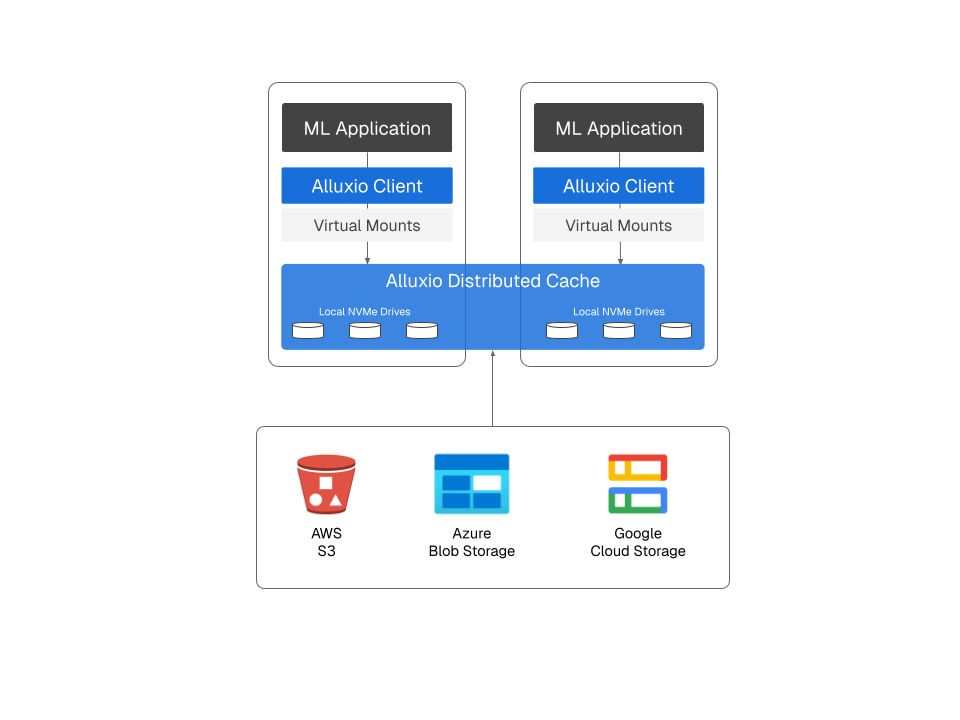
Inferless Three-Tier Serverless AI Inference Architecture
Results
6-12x improvement in LLM cold start performance—and freedom from cloud lock-in
With Alluxio deployed, Inferless reduced LLM model loading times from 10–30 seconds down to under 1 second. Compared to FSx, Alluxio provided equivalent or better performance while being simpler to manage, cloud-agnostic, and inference-optimized.
- 90%+ reduction in model load latency
- Significant reduction in cloud storage reads and egress charges
- Better support for hybrid-cloud and edge deployment scenarios
- Simpler scaling without shared filesystem complexity
Alluxio enabled Inferless to keep inference responsive and efficient—while building a platform that can grow across clouds, regions, and compute environments.
“Alluxio has been a game-changer, providing 6 to 12x faster model loading times and the critical multi-cloud agility we need for our serverless GPU compute service. By addressing the fundamental I/O challenges with Alluxio, the throughput of loading LLM weights can achieve a 10x improvement, approaching hardware limits (gigabytes per second throughput). With Alluxio, we can optimize our infrastructure to empower companies to deploy custom LLMs with unprecedented speed and efficiency."
— Nilesh Agarwal, Co-founder & CTO, Inferless
About Inferless
Inferless is a serverless AI inference platform that helps developers deploy machine learning models with zero infrastructure overhead. Designed for scale and speed, Inferless enables real-time inference for everything from image generation to large language models—running seamlessly across cloud and edge environments.
Learn more about Inferless’ architecture in this article written by Inferless Co-Founder and CTO Nilesh Agarwal.
.png)





