Watch the on-demand webinar presented by Fireworks AI engineer Akram Bawayah for a deep dive into their use case.
About Fireworks AI
Fireworks AI is a leading inference cloud provider for generative AI, delivering real-time inference, fine-tuning, and model optimization at massive scale across tens of GPU clouds globally. At peak, Fireworks processes 200,000 queries per second and 10+ trillion tokens per day, operating one of the most demanding inference infrastructures in production today. The platform is characterized by frequent large-model rollouts and highly bursty, synchronized deployment events across heterogeneous GPU clouds.
Challenges and Solution Highlights
Fireworks operates a massive, multi-cloud inference infrastructure in which model weights—ranging from 70 GB to over 1 TB—are decoupled from compute nodes. When more than 100 GPU replicas concurrently pull large artifacts (for example, a 1 TB Kimi model) from object storage, these synchronized bursts saturate inbound network bandwidth and trigger rate limits. As a result, model loading times can spike from minutes to hours, leaving costly GPU clusters idle.
To address this challenge, Fireworks deployed Alluxio as a distributed, co-located caching tier directly on GPU compute nodes, leveraging local NVMe SSDs. This deployment pattern is applied consistently, effectively positioning Alluxio as a common storage interface across all of their GPU clouds. Rather than replacing object storage, Alluxio acts as a transient, GPU-adjacent data acceleration layer specifically for large-scale fan-out access. As a result, beyond alleviating I/O bottlenecks through distributed caching, Alluxio shields the inference engine from provider-specific API quirks and performance variability. This abstraction allows Fireworks to integrate new cloud environments seamlessly and scale global GPU capacity without re-engineering data paths or model access patterns for each provider.
Solution Highlights
- Extreme Throughput: Achieved 1 TB/s+ aggregate throughput for model deployments across a heterogeneous multi-cloud fleet.
- Rapid Cold Starts: Reduced load times for a 750 GB model to approximately one minute; overall replica startup times dropped from hours to 1–3 minutes.
- “Download Once, Reuse Everywhere”: Alluxio orchestrates a single-fetch mechanism per cluster, pulling each model once from the repository and serving it at line rate to all concurrent GPUs.
- Transparent Kubernetes Integration: Deployed natively on Kubernetes, requiring no application-level code changes or workflow modifications.
- 50% Egress Cost Reduction: Achieved by decommissioning regional staging tiers and deduplicating cross-region data transfers.
- Proven Scalability: Sustains approximately 2 PB of data served per day, while maintaining 90–100% cache hit rates during peak production bursts.
Model Cold Starts at Extreme Scale
Fireworks operates a highly distributed inference platform built on a separation of compute and storage. Model weights are stored in Google Cloud Storage (GCS) and other S3-compatible object stores, while inference runs on GPU clusters spanning multiple clouds and regions.
As the platform scaled, model cold starts became a critical bottleneck.
Fireworks regularly deploys large models ranging from 70 GB to over 1 TB (Kimi), often across 10 to 100+ replicas per deployment. During scale events - such as new model rollouts, autoscaling, or cluster restarts - hundreds of GPU servers attempt to download the same model files simultaneously within a single cluster. At this scale, object storage bandwidth and rate limits become the dominant constraint, rather than GPU or in-cluster network capacity. This creates highly bursty, synchronized traffic patterns that place extreme pressure on object storage bandwidth.
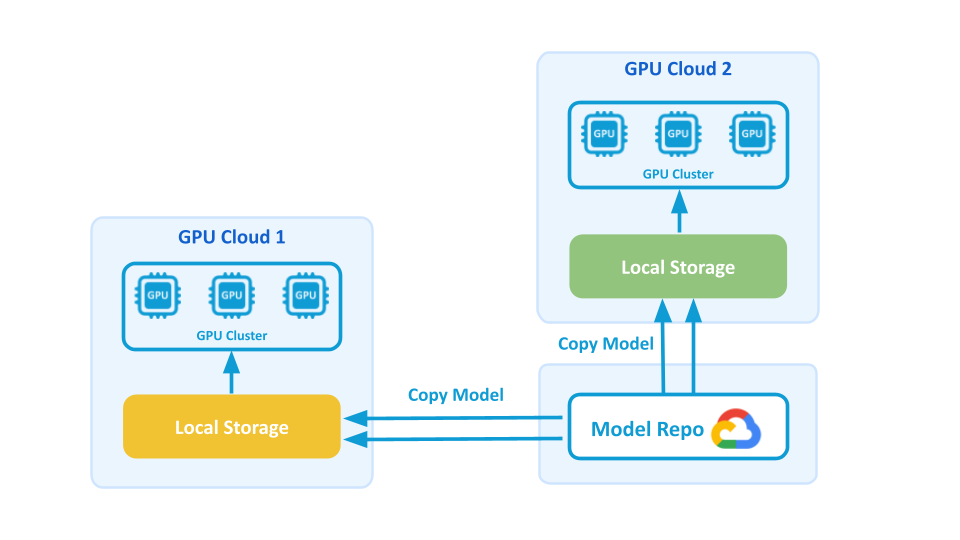
In Fireworks’ pre-Alluxio architecture, model distribution relied on a custom pipeline that:
- Downloaded models from primary object storage (GCS)
- Copied them into regional object storage closer to inference regions
- Used basic per-node caching on GPU servers
While functional at a smaller scale, this approach broke down under growth.
Technical Challenges
These challenges consistently emerged during synchronized scale events, rather than during steady-state inference workloads.
- Highly Concurrent Model Loading: Fireworks faces highly spiky and concurrent downloading of the same hot large files (models) across tens of GPU clouds. A single deployment can have anywhere from 10 to 100+ replicas, with each replica requiring a full copy of the model files. Hundreds of GPU servers download the same files (70 GB to 1 TB each) simultaneously within a single cluster, creating massive bandwidth demands and bottlenecks.
- Cold Start Problem: Slow download speeds result in high latency during initial model loading. Replica startup time was bound by inbound network bandwidth, which varies significantly across cloud providers and is typically much slower than internal cluster bandwidth. Downloading large models to 100+ GPU nodes could take 20+ minutes, and in some cases, over an hour due to GCS throttling.
- Manual Pipeline Management: Synchronizing many replicas that started at the same time, provisioning and managing regional object-storage caches, and manually coordinating full initialization created significant operational overhead and a lot of manual toil.
- Scalability Concerns: With hypergrowth, Fireworks realized they would need a dedicated engineer to observe the model distribution pipeline to ensure reliability.
Business Challenges
- Customer Experience Impact: Slow or unstable cold starts were critical business pain points for customers. Although the impact of faster model load speeds on revenue is difficult to quantify, an improved user experience positively impacts customer retention, renewal ARR, PoC conversions, and overall brand reputation.
- Egress Cost Burden: Fireworks spends tens of thousands of dollars on GCS egress fees annually, with significant costs from both regional object storage and primary GCS storage.
- Engineering Resource Waste: GCS rate limits result in wasted engineering time dedicated to babysitting model loads for several hours per week.
Why Alluxio: Co-located caching for Multi-Cloud GPU
Fireworks implemented Alluxio's distributed data caching solution with the following architecture:
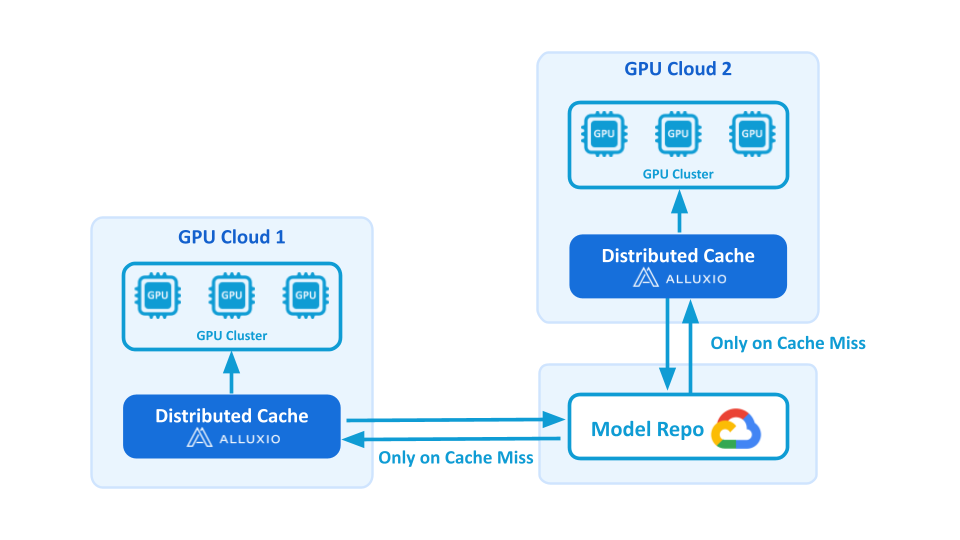
- Co-located Deployment: Alluxio cache is co-located within GPU nodes. Alluxio runs on the same physical hosts as the GPUs, managing their fast local SSDs for storage and caching, to fully exploit local NVMe and high in-cluster bandwidth during bursty deployments.
- Efficient Model Distribution: The same model loads into Alluxio only once, and then thousands of GPU cards read from Alluxio to download the model simultaneously. On a cache miss, Alluxio fetches from the model repository; subsequent reads are cache-only.
- Seamless Integration: Alluxio fits naturally into the architecture as a caching layer between object storage and GPU workloads without requiring major application rewrites. Everything runs on Kubernetes, with easy management for configuration updates and rollouts across clusters.
Alluxio Solution Results
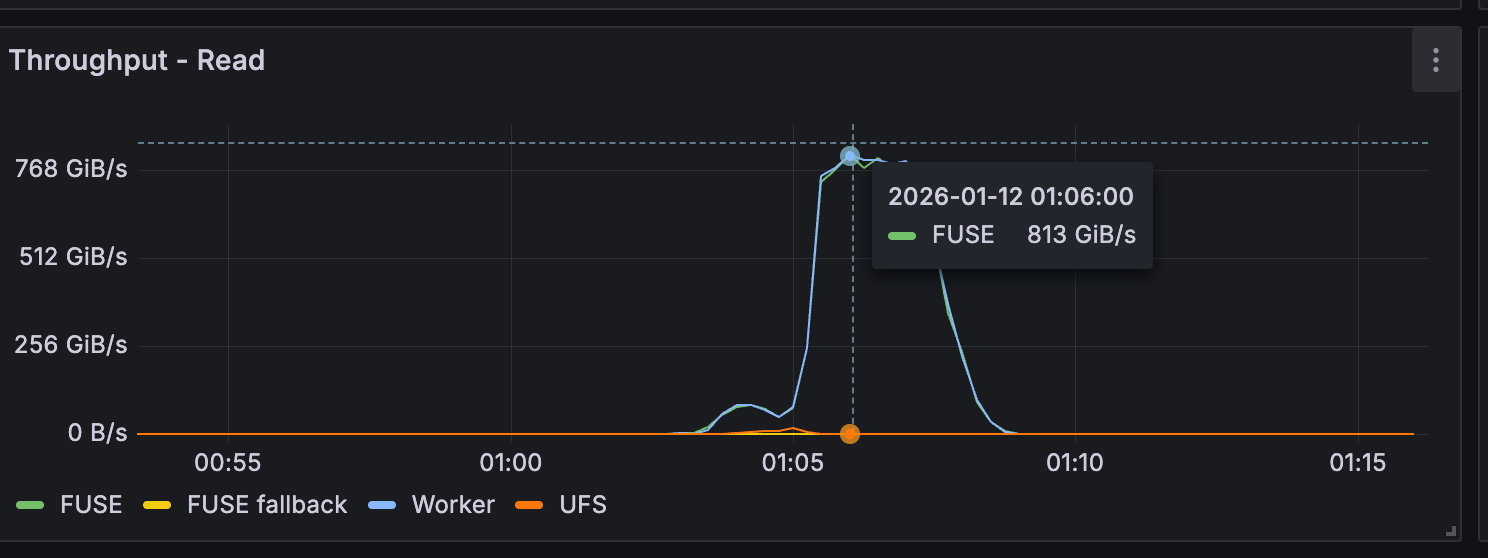
By introducing Alluxio as a distributed caching layer, Fireworks eliminated cold-start bottlenecks and unlocked consistent TB/s-scale throughput during model deployment. Large-model load times dropped from tens of minutes to just a few minutes per replica. The results below quantify these gains.
Key metrics before and after Alluxio:
The following performance results are provided by Fireworks:



Business Impact
- Reduced Engineering Overhead: Eliminated 4+ hours per week of manual pipeline management
- Cost Savings: Approximately 50% reduction in egress costs, translating to tens of thousands of dollars in annual savings from both GCS and eliminated regional object storage buckets
- Improved Customer Experience: Faster, more reliable model loading translates to better user experience
- Enhanced Scalability: Solution scales with Fireworks' hyper-growth trajectory without requiring dedicated engineering resources
Lessons Learned for Distributing Model Weights at Scale
Operating at Fireworks’ scale showed that achieving TB/s-class throughput in production is not simply adding a distributed cache. As sizes of model weights grow into the hundreds of GB or even TB today, and deployments fan out across dozens of GPU clusters, real-world performance is shaped by cache warmup behavior, cold-read paths, and highly synchronized burst traffic. Through close collaboration with Alluxio, Fireworks identified and addressed several production-specific bottlenecks that materially improved reliability and performance.
Efficient Cache Warmup for Large Models
Fireworks engineers often preloaded model weights into Alluxio before deployment to avoid cold cache reads. However, when individual model artifacts reached tens or hundreds of GBs, cache warmup became slower than expected despite sufficient raw bandwidth.
After investigation, we found the cache warmup process (submitting load jobs in Alluxio) was restructured to many small partitions (8MB) per file, which is an optimization for data lakes. By setting the warmup process to process much larger partitions (256MB), we are able to reduce the scheduling and coordination overhead in Alluxio’s distributed job execution, and speed up the warmup by ~20×, enabling large models to be staged and reused across GPU replicas efficiently during deployments.
Key insight: Beyond a certain file size, cache warmup performance can be dominated by chunking and prefetching strategy.
Aggressive Prefetching on Cache-Miss
With warmup, cold reads still remained unavoidable in production due to cache eviction, new model retrievals, and cluster churn. Default cold-read behavior for very large files introduced unnecessary startup latency. At Fireworks, we enabled aggressive asynchronous prefetching so that the first read of a large model file immediately triggered background fetching of the entire artifact. Cold-read performance improved by ~5×, significantly reducing tail latency during model startup and mitigating the impact of cache misses.
Key insight: For large, immutable model weights, treating the first read as a signal to prefetch the entire file dramatically improves startup latency and user experience.
Eliminating Hidden Concurrency Limits for Highly-Bursty, Synchronized Workloads
During events such as large rollouts or autoscaling, hundreds of GPU replicas attempted to load the same model simultaneously. Under extreme concurrency, some Alluxio workers began rejecting requests, causing cache-misses and subsequent fallbacks to remote model repo. While this does not block or cause errors for GPU applications, it slows them down while incurring egress costs.
We changed the Worker-side concurrency handling to better absorb the burst traffic, trading minimal queuing latency for significantly higher throughput and stability. Fallbacks to remote storage were largely eliminated, and Alluxio workers remained responsive even during extreme concurrency spikes.
Key insight: In AI infrastructure, the most dangerous workloads are not steady-state—they are synchronized, bursty events that stress coordination and concurrency limits.
Sustained Performance Is an Operational Discipline
As Fireworks scaled its multi-cloud GPU fleet, performance tuning could not remain a one-time exercise. Alluxio was treated as core production infrastructure and fully integrated into Fireworks’ Kubernetes-based CI/CD pipelines, enabling consistent configuration, rollout, and tuning across clusters. Performance improvements were applied reliably at global scale without requiring dedicated operational oversight.
Key insight: At this scale, high performance is an operational property of the system—not a one-time optimization.
Summary
By implementing Alluxio, Fireworks successfully transformed its model distribution architecture from a manual, error-prone process into an automated, high-performance system. Alluxio addresses Fireworks' technical challenges of cold start latency while delivering meaningful business value through improved customer experience, cost reduction, and engineering efficiency gains.
"Before Alluxio, we were spending hours every week manually managing model distribution pipelines, and our cold start times," said Akram Bawayah, Software Engineer at Fireworks AI. "With Alluxio's distributed caching, we've eliminated those cold start delays. What used to take hours now takes minutes. The solution scales seamlessly with our growth, and we've freed up our engineering team to focus on building features instead of overseeing infrastructure."
The implementation demonstrates how Alluxio's distributed caching technology can solve critical infrastructure challenges for AI platform providers operating at scale across multiple cloud environments. For Fireworks, this solution enables them to focus engineering resources on core product development rather than infrastructure maintenance, while delivering the high-performance, low-latency experience their customers demand.
.png)




