Make Amazon S3 Ready for AI
Accelerate AI/ML Training, Inference, and Agent Memory, RAG, & Feature Store Lookups without Migrating your Data from AWS S3.



.png)
When S3 Becomes the Bottleneck, AI Slows Down.
Amazon S3 is the undisputed backbone of cloud storage, offering unparalleled scalability, durability, and cost-effectiveness for various workloads.
However, as your workloads shift towards demanding AI/ML tasks like training, inference, and agentic AI, S3's original design begins to show its limits.
Are your AI teams facing these common challenges with S3?
S3 Standard delivers read latencies in the 30–200 ms range - unacceptable for real-time inference, feature store queries, RAG, agent memory, and transactional access.
S3 does not natively support core operations like appends, required for write-ahead logs and checkpointing, requiring inefficient and costly workarounds.
S3's flat object namespace makes high-performance metadata operations, such as directory listings, across millions of objects slow and expensive.
Migrating data to avoid S3 bottlenecks dramatically increases data transfer, egress, and S3 request expenses - plus the operational costs managing migration systems.
FSx Lustre and S3 Express One Zone
FSx and S3 Express can be prohibitively expensive at scale.
FSx provides POSIX access but requires dedicated clusters and increases operational overhead.
S3 Express provides S3 API access but is limited to a single AZ & lacks necessary sematics.
Alluxio supports both POSIX and S3 API access to your S3 data, additional semantics, full elasticity, and multi-cloud.
Alluxio AI = AWS FSx Lustre + S3 Express — without the cost or migration overhead
Alluxio takes a different approach to solving S3's limitations for AI workloads. Instead of forcing you to re-architect applications or migrate data to more expensive solutions such as FSx for Lustre or S3 Express One Zone, Alluxio acts as a transparent, distributed caching and augmentation layer on top of S3.
Feature
AWS FSx for Lustre
AWS S3 Express
Alluxio AI
Primary Model
High-performance file system for HPC & training
Low-latency object storage in one AZ
Distributed caching & semantics layer for AI
Latency
Ranges from millisecond to sub-millisecond
Sub-millisecond, optimized for object GET/PUT
Sub-millisecond on cache hits, plus high throughput across GPU fleets
Throughput
Parallel I/O at scale, sufficient for training
Designed for very high request rates (millions/sec)
Combines parallel throughput (FSx) + low latency (S3 Express) with elastic scaling
Semantics
POSIX-compliant
S3 APIs only, no append or rename
POSIX + S3 APIs, append, rename, write-ahead logs
Resource Utilization
Requires dedicated cluster, always-on cost
Elastic but restricted to one AZ
Leverages existing NVME resources on GPU nodes
Data Access
S3 integration, restricted to AWS ecosystem
S3-native, single AZ. Require data migration from data source to the S3 Express bucket
No data migration needed. Works with S3, S3 Express, FSx, GCP, HDFS, OCI, plus multi-cloud/on-prem
Best Fit
Training workloads needing parallel file system
Inference/real-time lookups, metadata-heavy workloads
Both training + inference + feature stores: accelerate full AI lifecycle
Limitations
High cost, migration overhead, training-only
No POSIX, no semantics, AZ-limited, higher cost/GB; defined at bucket creation time
Cache hit rate impacts latency (still requires deployment)
AWS FSx for Lustre
AWS S3 Express
Alluxio AI
Primary Model
High-performance file system for HPC & training
Low-latency object storage in one AZ
Distributed caching & semantics layer for AI
Latency
Ranges from millisecond to sub-millisecond
Sub-millisecond, optimized for object GET/PUT
Sub-millisecond on cache hits, plus high throughput across GPU fleets
Throughput
Parallel I/O at scale, sufficient for training
Designed for very high request rates (millions/sec)
Combines parallel throughput (FSx) + low latency (S3 Express) with elastic scaling
Semantics
POSIX-compliant
S3 APIs only, no append or rename
POSIX + S3 APIs, append, rename, write-ahead logs
Resource Utilization
Requires dedicated cluster, always-on cost
Elastic but restricted to one AZ
Leverages existing NVME resources on GPU nodes
Data Access
S3 integration, restricted to AWS ecosystem
S3-native, single AZ. Require data migration from data source to the S3 Express bucket
No data migration needed. Works with S3, S3 Express, FSx, GCP, HDFS, OCI, plus multi-cloud/on-prem
Best Fit
Training workloads needing parallel file system
Inference & real-time lookups, metadata-heavy workloads
Both training + inference + feature stores: accelerate full AI lifecycle
Limitations
High cost, migration overhead, training-only
No POSIX, no semantics, AZ-limited, higher cost/GB; defined at bucket creation time
Cache hit rate impacts latency (still requires deployment)
Performance Benchmarks
Model Distribution
Latency Comparison
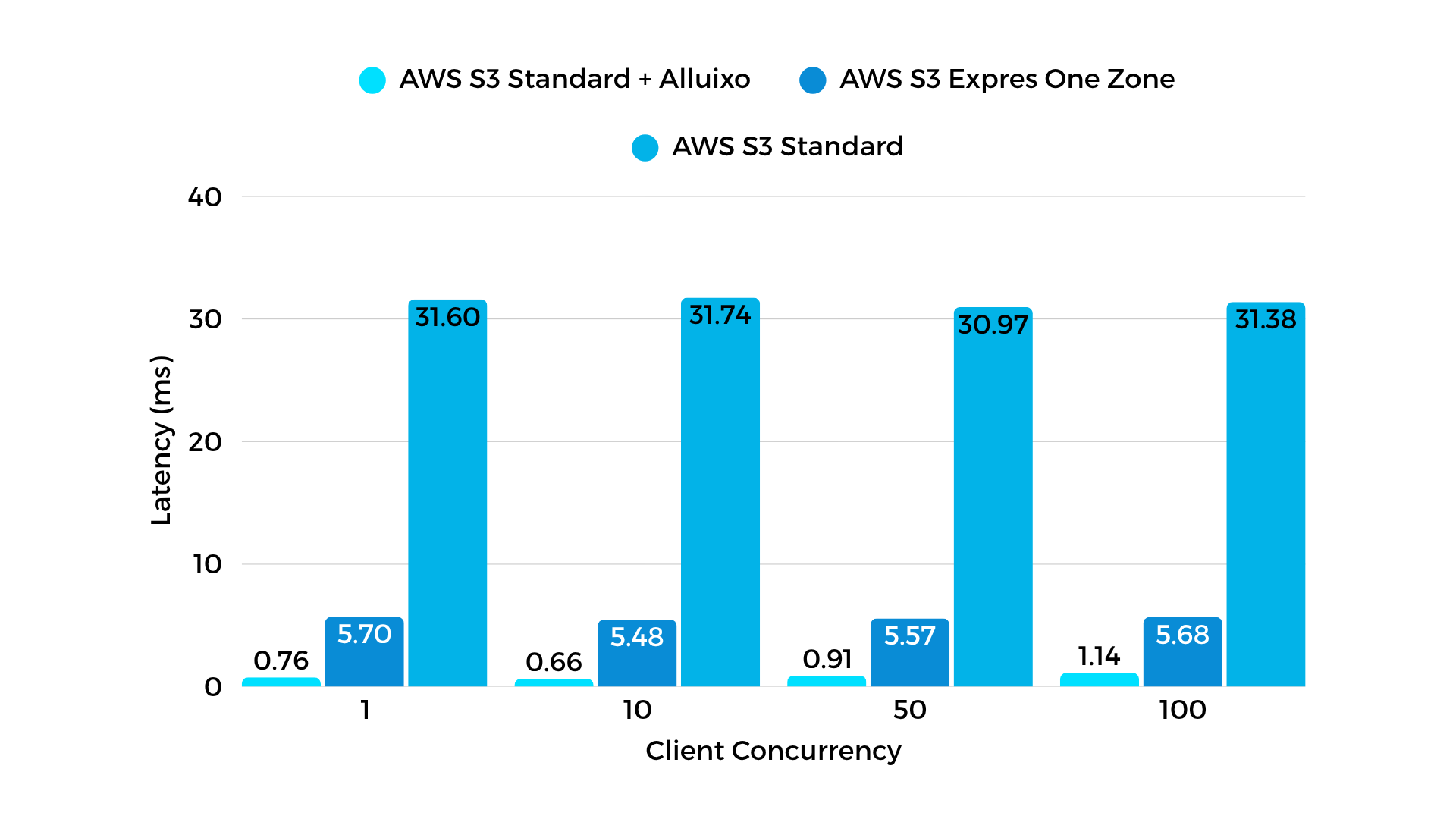
1 Alluxio Client; 1 Alluxio Worker
Read Throughput Comparison

1 Alluxio Client; 1 Alluxio Worker
Alluxio AI: Augmenting S3 for Unmatched AI Performance
Alluxio AI is purpose-built for the performance patterns of modern AI workloads. It delivers a "high-low mix" of durable, low-cost capacity from S3 with a high-performance, semantic-aware layer.

Blazingly Fast Feature Stores, RAG, & Agent Memory
Maximize GPU Utilization

Sub-Millisecond Latency
Achieve sub-millisecond TTFB latency for cache hits, crucial for agentic memory, feature stores, RAG pipelines, and inference serving. This is up to 45x faster than S3

Enhanced Data Semantics
Enable critical operations like append writes for write-ahead logs and checkpointing large objects, which are unsupported by S3

Lower Infrastructure Costs
Reduce S3 requests by over $1M per day (as seen in a real-world use case), improve GPU utilization, and significantly lower data movement, egress, and cloud access fees
Multi-Cloud Ready & Storage Agnostic
Works across clouds, storage systems (S3, GCS, OCI, Azure, HDFS, NFS, on-prem object stores), and frameworks like PyTorch, TensorFlow, Ray, and Spark, offering true hybrid and multi-cloud flexibility

Zero Data Migration
Keep your source-of-truth data in S3 without any `scp` or `rsync` — simply point clients at the Alluxio endpoint and run
Customer Testimonies
"The new distributed caching architecture has improved model training speed, reduced storage costs, increased GPU utilization across clusters, lowered operational overhead, enabled training workload portability, and delivered 40% better I/O performance compared to parallel file systems.”
FAQ
Is Alluxio a storage system like Amazon FSx?
No, Alluxio is not a storage system like Amazon FSx for Lustre. Alluxio is an AI-scale distributed caching platform bringing data locality and horizontal scalability to AI workloads. Alluxio does not offer persistent storage, instead Alluxio has the Under File System concept and leverages your existing data lakes and commodity storage systems. In contrast, Amazon FSx for Lustre is a traditional parallel file system limited to the AWS ecosystem and typically lacks advanced caching or federated data access across storage types.
Can Alluxio read directly from AWS S3?
Yes—Alluxio can connect directly to AWS S3 as an underlying data source. It reads and caches S3 objects on demand, enabling high-throughput, low-latency access without data duplication or manual pre-staging. Unlike FSx for Lustre, which requires staging S3 data into a file system before use, Alluxio provides zero-copy access to S3—eliminating delays and operational overhead.
Why choose Alluxio instead of FSx?
Alluxio is purpose-built to accelerate AI workloads in ways FSx for Lustre cannot. Compared to FSx, Alluxio offers:
- Faster end-to-end model training and deployment by eliminating data staging delays
- High performance that scales linearly across compute clusters and storage tiers
- Improved GPU utilization by minimizing idle time during data loading
Lower total cost of ownership—no IOPS charges and more efficient use of storage - Seamless support for hybrid and multi-cloud environments, not just AWS
Whether you're running training pipelines, inference, or retrieval-augmented generation (RAG), Alluxio delivers intelligent caching and zero-copy access to data in AWS S3 and other data lakes—without the limitations of FSx.
Can I use Alluxio in a Kubernetes environment?
Absolutely. Alluxio offers a Kubernetes-native operator, simplifying deployment and integration in containerized AI platforms. Unlike FSx, it’s built to work smoothly in cloud-native environments.
Do I need to modify my application to use Alluxio?
No. Alluxio provides transparent data access via POSIX (FUSE), S3, HDFS, and Python APIs—so you can integrate it with existing applications without any code changes.
Do I need to have a hybrid or multi-cloud environment in order to get the benefits from Alluxio?
Not at all, you can still benefit from performance gains and cost savings compared to FSx even if you are all in a single cloud, such as AWS.
How does Alluxio pricing compare to Amazon FSx for Lustre pricing?
In head to head comparisons with FSx, Alluxio can save 50-80% on storage costs alone. Additionally, unlike FSx, Alluxio does not charge for IOPS, which can be high. Contact us for a custom quote.
What are Alluxio’s top workloads and industries?
Alluxio is designed for AI workloads including, Gen AI, LLM training and inference, multi-modal, autonomous systems and robotics, agentic systems and more. Alluxio powers AI platforms across industries from fintech, autonomous driving, embodied AI, robotics, inference-as-a-service, social media content platforms, enterprise AI and more.