
AI training checkpoint writes to cloud object storage incur 30–40 ms of latency per operation and trigger S3 throttling at scale. This guide explains the root causes, surveys every major architectural approach, and describes the write-back caching architecture that eliminates the problem.
The write-back caching architecture is particularly relevant for teams operating across multiple clouds, GPU providers, or on-premises environments that need a portable way to accelerate checkpoint writes while preserving object storage as the system of record.
Who this guide is for: MLOps engineers, AI infrastructure leads, and platform teams responsible for distributed training at scale — whether operating a shared training platform across hundreds of concurrent jobs or building infrastructure for a single large training run.
What this guide covers: The root causes of checkpoint-induced GPU idle time; a comprehensive survey of checkpoint architectures with scenario-based guidance on where each fits; and a technical description of the write-back caching architecture — including how Alluxio Write Cache implements it in production across multi-cloud and hybrid environments.
We checkpoint and restart as often as we can.
- Jensen Huang CEO and Co-Founder, NVIDIA
Section 1: What Is a Training Checkpoint?
A checkpoint is a snapshot of model state written to persistent storage at regular intervals during a training run. It captures everything the training job needs to resume from a known-good state: model weights, optimizer state, gradient accumulators, and scheduler state.
If a node fails, a job is preempted, a network link flaps, or a run produces unexpected behavior — an irregular learning rate, a loss spike — the job restarts from the most recent checkpoint rather than from scratch. At the scale of Meta's Llama 3 training, hardware failures occurred roughly every three hours across thousands of GPUs, making frequent checkpointing not optional but the primary defense against losing hours of irreplaceable compute.1
Checkpoints serve purposes beyond fault recovery. They enable seamless resumption at any training step, platform migration between systems, and deviation correction when a model strays from its objective. Intermediate checkpoints can also serve as seeds for new training objectives, repurposing a partially-trained model for adjacent tasks without starting from scratch.
Checkpoint size is consistently larger than teams expect. The raw weight size is only part of the story.
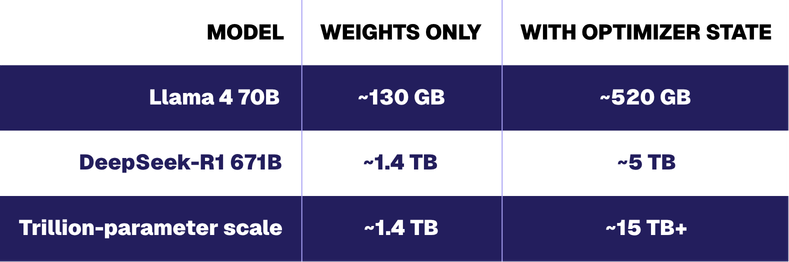
The optimizer state multiplier — approximately 4x over weights alone — comes from Adam-class optimizers, which store per-parameter first and second moment estimates in addition to the weights themselves. For trillion-parameter-scale models, checkpoint data per event can reach 15 TB or more.
In distributed training, this large write is not sequential. In Fully Sharded Data Parallel (FSDP) training, every GPU process writes its shard simultaneously — creating massive write concurrency across hundreds or thousands of ranks. In Distributed Data Parallel (DDP) training, a single rank writes the complete checkpoint while all other ranks wait. Both patterns create significant storage pressure at exactly the moment storage is least equipped to handle it.
Checkpointing frequency compounds the cost. Production training runs typically checkpoint every few hundred steps, or every few minutes of wall-clock time. Storage performance is therefore not a one-time cost. It is a recurring tax on every training job, every run, at every checkpoint interval.
Section 2 explains exactly why that tax is higher than it needs to be — and what it is actually costing AI teams.
Section 2: Why Checkpointing Slows Down Training
Checkpointing slows down training because of two compounding bottlenecks: object storage write latency and burst write contention. Together, these mean that every checkpoint event consumes GPU capacity that could be spent on training — capacity that, for most AI teams, is already scarce.
Root Cause 1: Object Storage Was Not Built for Checkpoint Writes
Most AI training infrastructure stores model artifacts in cloud object storage — Amazon S3, Google Cloud Storage, or Azure Blob. Object storage is the right choice for persistence. It is durable, cheap, and universally accessible.
But object storage was architected for high-throughput batch reads and sequential large-object access — not for the low-latency, bursty, fine-grained write patterns that model training generates. A standard S3 PUT operation incurs 30 to 40 ms of latency per request.3 For a single sequential write this is negligible. But checkpointing is a coordinated burst across all training ranks, writing many files or file segments simultaneously. At that latency, the training process must wait. Every GPU in every rank sits idle while checkpoint writes drain to S3.
Object storage also has limited support for the semantics training workflows need. Atomic renames are a particular problem: on S3 and GCS, a rename is not atomic but a copy followed by a delete — doubling the I/O cost of every checkpoint finalization step. Append operations and write-ahead log patterns are either unsupported or inconsistently implemented across providers, forcing training frameworks to use workarounds that add additional round trips. Alluxio Write Cache addresses the rename problem directly: checkpoint data is written to the final path without the copy-plus-delete cycle, eliminating this category of per-operation overhead at every checkpoint event.
Root Cause 2: Burst Writes Trigger Rate Limits and Retries
Cloud object storage enforces request rate limits at the bucket and prefix level. Under the burst write pattern of large-scale training — hundreds of training ranks writing checkpoint fragments simultaneously across dozens of concurrent jobs — S3 request rates spike dramatically and trigger throttling.
When S3 throttles it returns HTTP 503 errors. The client retries. Retries add latency that blocks every GPU in the affected job. In the worst case, retries fail repeatedly — causing checkpoint writes to take tens of seconds rather than tens of milliseconds. In some production environments, sustained throttling causes checkpoint writes to fail entirely, triggering full job restarts and destroying hours of training progress in a single event.
Tuning retry logic does not solve this. It is a structural consequence of writing bursty checkpoint traffic directly to object storage.
How the Problem Scales: Wasted Capacity, Disrupted Teams
For AI companies, the impact of checkpoint bottlenecks goes beyond infrastructure cost. GPUs are the scarcest resource in AI development — every hour of idle GPU time is an hour that cannot be applied to the next experiment, the next training run, or the next model iteration. Checkpoint overhead is a silent tax on the resource that determines how fast teams can move.
Consider a platform running 200 concurrent training jobs, each on a 64-GPU cluster. Every checkpoint event blocks all 64 GPUs while writes drain to S3. At 35 ms of overhead per checkpoint — a conservative estimate of S3 PUT latency — and 144 checkpoint events per job per day:
- Synchronous stall: 200 jobs × 64 GPUs × 144 checkpoints × 35 ms = approximately 18 GPU-hours of wasted capacity per day from baseline write latency alone.
- Throttling retries: When burst traffic triggers S3 rate limits, each retry event adds seconds of stall across all ranks. A conservative estimate of 2 throttling events per job per day, each adding 2 seconds: 200 jobs × 64 GPUs × 2 events × 2,000 ms = approximately 14 additional GPU-hours per day.
- Full job restarts: Under sustained throttling, checkpoint writes can fail entirely — forcing a full restart from the last successful checkpoint. A single restart on a 64-GPU cluster mid-way through a 6-hour run loses 192 GPU-hours of training progress in one event. Even at a conservative rate of 1 restart per 10 jobs per day, that produces approximately 1,280 GPU-hours of lost capacity.

These three components compound differently and affect teams differently. The synchronous stall is constant and invisible — no alarm fires, every dashboard looks healthy, but capacity is silently eroding on every checkpoint cycle. The throttling retries are intermittent and disruptive — they introduce unpredictable latency spikes that make training timelines unreliable. The job restarts are catastrophic and demoralizing — they force engineers to stop what they are doing, triage the failure, confirm the restart, and re-evaluate training progress. At scale, frequent checkpoint failures erode team confidence in the infrastructure and introduce an operational burden that compounds alongside the GPU waste.
No single job looks broken. Every job is silently penalized. The GPU utilization dashboard looks healthy. The training loss curves look normal. But the capacity that should be advancing your next model is being consumed by storage infrastructure that was never designed for this workload.
Section 3 surveys the checkpoint architectures available today — with scenario-based guidance on where each one fits best.
Section 3: Choosing the Right Checkpoint Architecture
There is no single right answer to the checkpoint architecture question. The right choice depends on your infrastructure environment, model scale, budget, and how much operational overhead you can absorb.
What follows is a comprehensive survey of every major approach — what each does well, where it falls short, and the scenarios where it is genuinely the right fit. Some of these approaches are sufficient on their own for certain environments. Others work best in combination. The goal is to help you match your situation to the right solution.
Approaches are organized by the layer of the stack where they operate. Understanding which layer each approach targets is the key to understanding what it can and cannot solve.

Tier 1: Training Job and Framework Layer
Local Disk (NVMe)

|

|
Writing checkpoints to node-local NVMe disk avoids object storage latency entirely. Local NVMe delivers sequential write throughput of 3 to 7 GB/s and sub-millisecond latency — orders of magnitude better than S3.
The fundamental limitation is durability and accessibility. If the node goes down, the checkpoint is gone. Other jobs, replicas, and evaluation pipelines on different nodes cannot access it. NVMe capacity per node is fixed and shared with OS, data caches, and other workloads.
Local disk works well as a short-term staging buffer. It does not work as a standalone checkpoint strategy at scale.
RAM Disk / tmpfs
|
|
|
|
Writing checkpoints to a RAM disk delivers near-zero latency, limited only by memory bus speed. Some teams use this for very frequent intermediate saves, treating RAM as an ultra-fast first tier.
RAM is volatile: a node failure or process crash destroys in-memory checkpoints with no recovery path short of the last durable save. RAM capacity is shared with model activations, gradient buffers, CPU-side optimizer state, and dataloader prefetch. For frontier-scale models where cluster-wide optimizer state reaches 5 TB, RAM-based checkpointing requires careful per-node memory budgeting and peer replication for any durability guarantee.
Framework-Level Async Checkpointing (PyTorch AsyncCheckpointManager)
|
|
|
|
PyTorch's AsyncCheckpointManager offloads checkpoint serialization to a background thread. The mechanism: PyTorch takes an in-memory snapshot — a memcpy from GPU to CPU — then writes that snapshot to the target storage system from a separate thread. The main training loop does not block on the write.
This meaningfully reduces GPU blocking time and is worth enabling. But it solves a framework-layer problem, not a storage-layer problem. The write still terminates at object storage — with full exposure to 30 to 40 ms PUT latency and burst throttling from concurrent rank writes. AsyncCheckpointManager moves the bottleneck; it does not remove it.
PyTorch's async checkpointing and Alluxio Write Cache are complementary, not competing. Used together the benefits are fully additive: the GPU un-blocks at PyTorch snapshot time, and the async write lands on local NVMe at sub-2 ms rather than on S3 at 30 to 40 ms.
Tier 2: Storage Client and Request Layer
Write Batching and Prefix Sharding
|
|
|
|
Distributing checkpoint writes across multiple S3 prefixes reduces the per-prefix request rate, lowering the probability of hitting bucket-level throttling limits. Batching small writes into larger sequential objects reduces the total number of PUT requests.
Neither technique addresses baseline PUT latency. A well-sharded, well-batched write to S3 still incurs 30 to 40 ms of latency per operation. At sufficient scale, synchronized checkpoint bursts can still trigger throttling even across sharded prefixes.
Object Storage Acceleration (S3 Express One Zone, GCS High-Throughput Storage)
|
|
|
|
AWS S3 Express One Zone delivers single-digit millisecond latency on reads and writes, along with significantly higher per-bucket request rates than S3 Standard. This genuinely reduces the checkpoint latency gap for teams committed to a single cloud provider.
Cost. S3 Express One Zone costs approximately $110/TB/month versus $23/TB/month for S3 Standard — roughly a 5x premium.8 Alluxio Write Cache on spare GPU NVMe drives adds approximately $11 to $42/TB/month on top of S3 Standard — a fraction of the Express premium with comparable or better write latency.
Durability. S3 Express One Zone is a single-AZ offering. Checkpoint data is not replicated across availability zones — a durability risk most production training platforms cannot accept.
Portability. S3 Express One Zone is AWS-only. It is a point solution for one provider, not a portable architecture.
Latency ceiling. Even at single-digit millisecond latency, S3 Express does not match NVMe-speed writes. At high checkpoint frequency across large clusters the gap still accumulates into meaningful GPU idle time.
Tier 3: File System and Infrastructure Layer
Parallel File Systems (FSx for Lustre, WekaFS, GPFS / IBM Spectrum Scale, DDN)
|
|
|
|
High-performance parallel file systems deliver high aggregate throughput, low-latency POSIX semantics, and the ability to stripe data across multiple storage nodes simultaneously. Vendors like DDN report their platforms can write a checkpoint up to 15 times faster than direct object storage, with more than 2x checkpoint performance improvements demonstrated on NVIDIA NeMo and HuggingFace workloads.
Google Cloud positions parallel file systems as appropriate for large clusters needing high throughput. AWS FSx for Lustre is commonly deployed alongside SageMaker training jobs for this reason. For on-premises DGX SuperPOD reference architectures, parallel file system vendors are frequently part of the certified stack.
Cost. FSx for Lustre costs approximately $600/TB/month for the high-performance tier — roughly 26 times S3 Standard. Even the capacity tier runs approximately $143/TB/month.8
Operational complexity. Parallel file systems require dedicated infrastructure separate from compute — provisioned, sized, monitored, and maintained independently.
Cloud portability. FSx for Lustre is AWS-only. WekaFS and GPFS are available across clouds but require separate licensing and deployment per environment. Not viable for multi-cloud training.
Co-location. Parallel file systems are typically separate clusters connected over the network. Write latency is network-bound rather than NVMe-bound.
Cloud-Managed Tiered Checkpointing (AWS SageMaker HyperPod, Google AI Hypercomputer)
|
|
|
|
Both AWS and Google Cloud have introduced managed tiered checkpointing following the same general architecture: write to CPU RAM first, replicate to adjacent nodes for resilience, flush asynchronously to object storage for durability.
AWS SageMaker HyperPod uses RDMA over Elastic Fabric Adapter (EFA) for peer replication, validated at clusters from hundreds to more than 15,000 GPUs.5 Google AI Hypercomputer uses a Replicator component with topology-aware peer selection, automatic data deduplication for data-parallel workloads, and garbage collection, reporting a 6.59% ML Goodput increase on a 35,000-chip TPU v5p workload.4
RAM volatility. The fast tier is CPU RAM, not NVMe. If the node is lost entirely, in-memory checkpoints are gone and recovery falls back to object storage. NVMe survives software failures and node restarts without peer replication.
Capacity constraints. RAM capacity is shared with the training process. At the largest model sizes — optimizer state checkpoints reaching 5 TB at the cluster level — RAM-based tiering becomes constrained by per-node memory budgets.
Platform lock-in. AWS HyperPod managed tiered checkpointing requires an EKS-backed HyperPod cluster. Google's multi-tier checkpointing is purpose-built for AI Hypercomputer. Neither is available on bare-metal, on-prem, independent Kubernetes, or across multiple clouds.
Combining Approaches
None of these approaches is mutually exclusive with the write-back caching architecture. PyTorch's AsyncCheckpointManager, prefix sharding, and write batching operate at the framework or storage-client layer and can run alongside any infrastructure-layer solution. Alluxio Write Cache operates at the storage layer and is deployable independently of any managed platform.
A training job running PyTorch async checkpointing against Alluxio Write Cache gets benefits at both layers: the GPU un-blocks at PyTorch snapshot time, and the async write lands on local NVMe at sub-2 ms rather than on S3 at 30 to 40 ms.
Key Takeaways — Section 3
- No single approach is universally correct. The right choice depends on infrastructure environment, model scale, budget, and portability requirements.
- Framework-layer approaches reduce blocking but cannot change where the write terminates.
- Infrastructure-layer approaches (parallel file systems, cloud-managed tiering) solve the problem well within their target environments but introduce cost, operational complexity, or platform lock-in.
- Multiple approaches can and should be combined — they operate at different layers and their benefits are additive.
- For multi-cloud, hybrid, or portable infrastructure environments, the write-back caching architecture fills a gap the other approaches cannot.
Section 4 describes the write-back caching architecture in detail — and the production evidence that confirms it is the right approach for environments where portability and NVMe durability matter.
Section 4: The Write-Back Caching Architecture
For environments where portability, NVMe durability, or cost efficiency matter — and where managed platform solutions are unavailable or insufficient — the write-back caching architecture is the right answer.
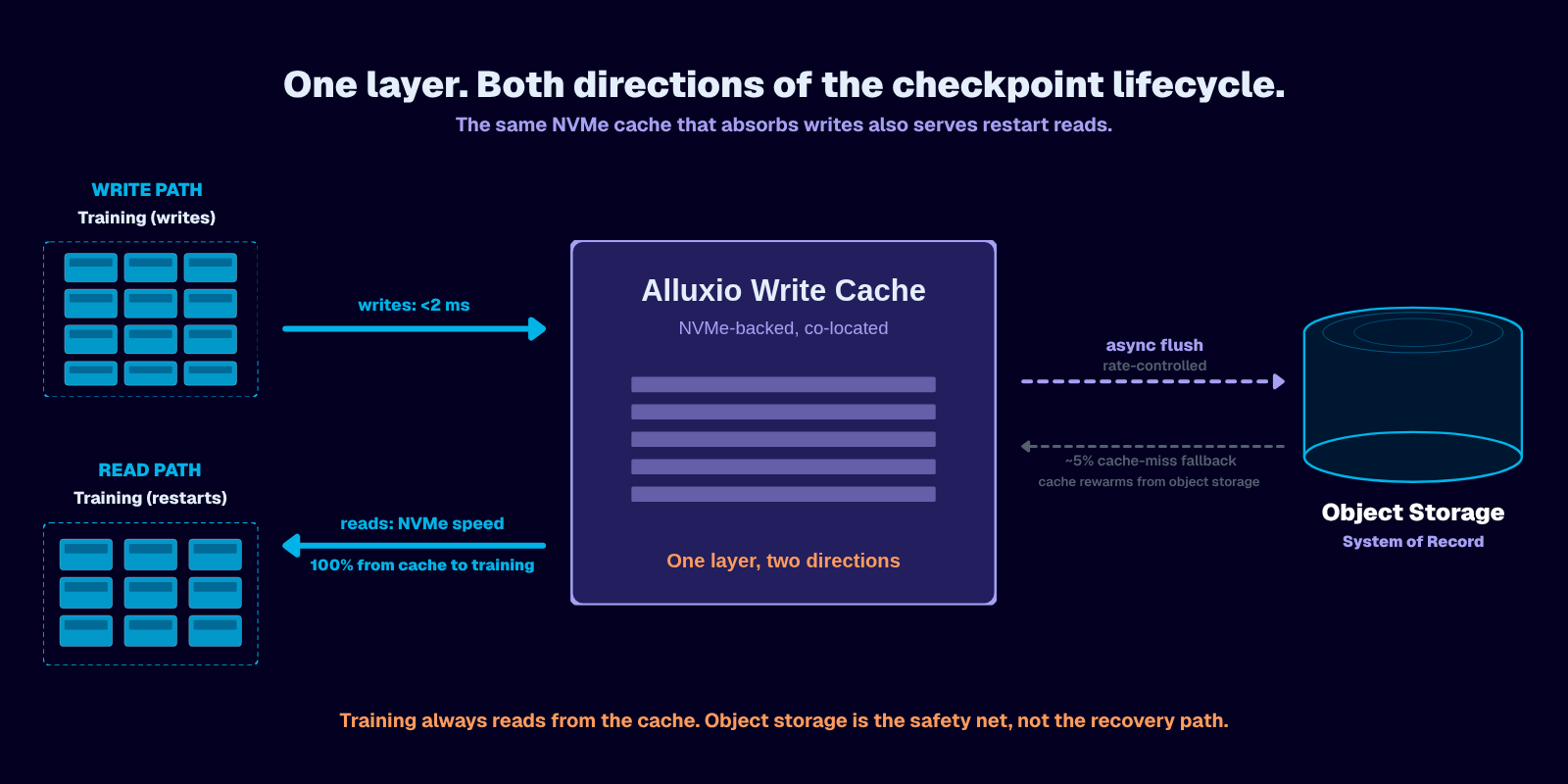
The architecture: training jobs write to a fast, local NVMe-backed cache that absorbs the write immediately and persists to object storage asynchronously in the background. From the training framework's perspective, the write is complete the instant the cache acknowledges it. From object storage's perspective, the write arrives as a smooth, rate-controlled stream rather than a synchronized burst.
Three key properties define the write-back caching architecture:
- Write latency drops to NVMe speed (sub-2 ms P99). Fully decoupled from object storage network latency. The training loop never waits on object storage — checkpoint latency is bounded to local NVMe speed.
- Burst traffic is smoothed. The cache absorbs the synchronized write burst from all training ranks and flushes to object storage as a steady, rate-controlled stream. The throttling trigger is eliminated entirely.
- Immediate read-after-write. Once a checkpoint lands in the cache it is instantly readable by any process — including a restarting training job or a downstream evaluation pipeline — without waiting for async persistence to complete.
The architectural requirements: NVMe-backed storage co-located with compute, distributed scaling to match cluster size, configurable persistence guarantees for durability, and transparent integration requiring no changes to training code.

This architecture is validated by production behavior across large-scale training environments. Teams that checkpoint efficiently maintain overlap under 10% of total training time by using a fast local tier to absorb writes and draining to global storage asynchronously at a controlled rate. The global storage bandwidth requirement is modest and predictable:
Checkpoint bandwidth (GB/s) = (N_params × bytes_per_param) / (checkpoint_interval_seconds × overlap_fraction) × 10⁻⁹
For a 405-billion-parameter model on 16,000 H100 GPUs — 14 bytes per parameter including optimizer state, 15-minute checkpoint interval, 10% overlap target — the required global bandwidth is approximately 63 GB/s. For a 1-trillion-parameter model at the same assumptions with a 5-minute interval, approximately 467 GB/s. Both figures are well within reach of most production storage systems.
This conclusion is corroborated by the fact that AWS, Google Cloud, and Alluxio have independently converged on the same answer: a fast local tier absorbs writes, global storage receives an asynchronous drain. The differences are in the fast tier medium, portability, and supported infrastructure environments. AWS HyperPod and Google AI Hypercomputer use CPU RAM — fast but volatile and platform-constrained. Alluxio Write Cache uses NVMe — non-volatile, portable, and deployable on any infrastructure.
The NVMe versus RAM distinction is architecturally meaningful. RAM is volatile: if the node is lost entirely, in-memory checkpoints are gone and recovery falls back to the last checkpoint written to durable global storage. NVMe survives software failures and node restarts without depending on peer replication for recovery. Given that approximately 95% of large-scale training failures are subcomponent failures rather than whole-node losses, NVMe-backed checkpoints cover the vast majority of failure events durably without replication overhead.
Section 5 describes how Alluxio Write Cache implements this architecture in production — including two specific optimizations that directly address the root causes identified in Section 2.
Section 5: How Alluxio Write Cache Works
Alluxio Write Cache is a production implementation of the write-back caching architecture, deployed at scale across multi-cloud and hybrid environments.
Alluxio Write Cache operates in WRITE_BACK mode to bound checkpoint latency to local NVMe speed and flush to object storage asynchronously, removing the checkpoint stall from the training loop entirely.
Training jobs access Alluxio Write Cache through either a POSIX-compatible FUSE mount or Alluxio's S3-compatible API — whichever interface the framework already uses. Alluxio Write Cache intercepts checkpoint writes, acknowledges them at NVMe speed, and persists checkpoint data to cloud object storage in the background.
1. NVMe-Speed Writes
Checkpoint data lands on local NVMe drives co-located with GPU compute, fully decoupled from object storage network latency. P99 write latency is below 2 ms, with peak write throughput of 7.6 GiB/s per worker — scaling to 20 GiB/s peak across a three-worker cluster with near-linear scaling and less than 2% write-back overhead.6
Unlike the RAM-based tiering approaches used by AWS HyperPod and Google AI Hypercomputer, NVMe is non-volatile: checkpoint data survives node restarts and software failures without depending on peer replication for recovery. Aggregate write throughput scales horizontally as additional Alluxio Write Cache worker nodes are added — there is no single point of bottleneck.
2. Immediate Read-After-Write
Data written to Alluxio Write Cache is instantly accessible for reads, at the same NVMe speed, without waiting for async persistence to object storage to complete.
This is critical for checkpoint recovery: when a training job fails and restarts it reads the most recent checkpoint from cache at NVMe speed rather than pulling from S3. For the approximately 95% of failures that are subcomponent failures recoverable from the local fast tier, those recoveries happen entirely from NVMe, in seconds, with no object storage dependency.
3. Async Persistence
Alluxio Write Cache flushes checkpoint data to cloud object storage asynchronously, without blocking the training loop. Object storage remains the system of record — checkpoints are fully durable in S3, GCS, or Azure Blob after flush — but the training job never waits on that flush.
The flush rate is controlled and smooth, eliminating the burst pattern that triggers object storage throttling. Durability guarantees are configurable: operators can tune flush frequency, retention policies, and the number of object storage copies to match their recovery time and recovery point objectives.
4. Zero Code Changes, Any Infrastructure
Training jobs access Alluxio Write Cache through a POSIX-compatible FUSE mount or Alluxio's S3-compatible API. No library imports, no custom storage writers, no training loop modifications, no platform-specific configuration.
Alluxio Write Cache runs on any Kubernetes cluster, any cloud, any bare-metal environment, and is compatible with any training framework. The same deployment that accelerates checkpoints on AWS operates identically on GCP, Azure, CoreWeave, Lambda Labs, or an on-premises H100 cluster — without reconfiguration.
Alluxio Write Cache is also fully compatible with PyTorch's AsyncCheckpointManager. The two operate at different layers of the stack and their benefits are additive.
5. S3 API Compatibility and No-Rename Optimization
Alluxio Write Cache supports checkpoint writes through both FUSE and the standard S3 API, including full support for multi-gigabyte checkpoint files. Training frameworks that write checkpoints via the S3 API natively — including PyTorch, DeepSpeed, and Megatron-LM — are fully supported without requiring a FUSE mount or any code changes.
Alluxio Write Cache also eliminates the rename overhead that S3 and GCS impose on checkpoint workflows. As described in Section 2, a rename on object storage is a copy followed by a delete — doubling the I/O cost of every checkpoint finalization step. Alluxio Write Cache writes checkpoint data directly to the final path, bypassing the rename cycle entirely. The no-rename optimization delivers up to 2x faster checkpoint writes, independent of the NVMe-speed acknowledgment benefit.7
The two gains are fully additive: NVMe-speed acknowledgment eliminates object storage network latency on the write path; the no-rename optimization eliminates copy-plus-delete overhead on the finalization path. Higher GPU utilization follows directly — reduced checkpoint latency means less idle time between training iterations.
Section 6 describes how Alluxio Write Cache accelerates the read side of the checkpoint lifecycle — specifically, how training jobs recover faster when they restart after a failure.
Section 6: Checkpoint Reads — Faster Restarts After Failure
Alluxio Write Cache's benefit extends beyond the write path. The same NVMe-backed distributed cache tier that absorbs checkpoint writes also accelerates the read side of the checkpoint lifecycle: reloading the most recent checkpoint when a training job fails and needs to restart.
When a training job fails and restarts it must load the most recent checkpoint before resuming. If that checkpoint lives only in object storage, restart time is dominated by S3 read latency and throughput — potentially minutes for large models. During that window the full GPU cluster sits idle, burning scarce capacity without producing training progress.
If the checkpoint is already resident in Alluxio Write Cache's local NVMe tier, restart reads from cache at NVMe speed, with aggregate cluster read throughput scaling horizontally as the cluster grows.
The practical impact depends on failure type. For the approximately 95% of failures that are subcomponent failures — link flaps, GPU ECC errors, software crashes — the local NVMe checkpoint survives intact. The restarting job reads from cache in seconds, with no object storage dependency. Only the rarer whole-node failures require falling back to the object storage copy, and even those recover faster once the replacement node fetches the checkpoint from object storage and re-warms its cache.
Alluxio Write Cache effectively covers the full checkpoint cycle for the most common failure scenarios: the checkpoint is written to NVMe at sub-2 ms latency, persisted to object storage asynchronously in the background, and read back from NVMe at full cache speed on restart. Object storage is the safety net for catastrophic failures, not the primary recovery path.
The same NVMe cache layer that removes the checkpoint stall from the training write path also removes the checkpoint load bottleneck from the training restart path. One infrastructure layer solves both sides of the checkpoint lifecycle.
Section 7 brings everything together: a scenario-based decision guide and a summary of root causes.
Section 7: Summary and Decision Framework
Why Checkpointing Slows Down AI Training
- Object storage write latency (30 to 40 ms per PUT) forces every GPU in every rank to idle while checkpoint writes complete.3
- Synchronized burst writes from concurrent training ranks trigger S3 throttling, causing retries, failed checkpoints, and full job restarts — each of which destroys hours of training progress and forces engineering teams to stop and triage.
- Training frameworks block on synchronous writes by design — every checkpoint event is a forced pause in the training loop.
- Object storage rename semantics (copy + delete) add per-operation overhead on every checkpoint finalization step.
- At platform scale these effects compound into tens to hundreds of GPU-hours of wasted capacity per day — invisible on utilization dashboards, but real in their impact on training velocity, team productivity, and the pace of model development.
What Good Checkpoint Architecture Looks Like
- A fast local tier absorbs checkpoint writes at NVMe speed and acknowledges them immediately — no object storage wait.
- Global storage receives an asynchronous, rate-controlled drain from the local tier — not a synchronized burst.
- The fast local tier should be non-volatile: most training failures (~95%) are subcomponent failures that do not destroy locally-resident checkpoints.
- Global storage bandwidth requirements are modest and predictable. The hard problem is write latency at the fast local tier, not global throughput.
Which Solution Fits Your Situation
The table below maps common infrastructure scenarios to recommended approaches, ordered from simplest to most complex. Multiple solutions may apply in some environments.
How to Get Started with Alluxio Write Cache
Alluxio Write Cache deploys as a Kubernetes-native distributed cache co-located with your GPU cluster. It mounts transparently via FUSE or S3-compatible API, requires no changes to training or inference code, and connects to any S3-compatible object storage as the durable backend.
Request a demo or talk to an Alluxio engineer at www.alluxio.io/demo
Explore the Alluxio AI Docs at documentation.alluxio.io/ee-ai-en
SOURCES & NOTES
- Meta Llama 3 training failure rates (hardware failures every ~3 hours; ~5% whole-node failures): Meta, "The Llama 3 Herd of Models," arXiv:2407.21783, July 2024.
- Checkpoint size estimates for Llama 3 70B (~130 GB weights; ~521 GB with optimizer state) and DeepSeek-R1 671B (~1.4 TB weights; ~5 TB with optimizer state) are derived from published model parameter counts using standard BF16 precision (2 bytes/param for weights) and Adam optimizer state conventions (additional ~6 bytes/param). See also AWS SageMaker HyperPod managed tiered checkpointing documentation, September 2025.
- S3 PUT latency range (30–40 ms): consistent with AWS S3 published performance characteristics and widely reported in production AI infrastructure benchmarks.
- Google AI Hypercomputer multi-tier checkpointing: 6.59% ML Goodput increase on 35,000-chip TPU v5p workload. Google Cloud Blog, "Using multi-tier checkpointing for large AI training jobs," June 2025.
- AWS SageMaker HyperPod managed tiered checkpointing validated on clusters from hundreds to 15,000+ GPUs. AWS Blog, "Accelerate your model training with managed tiered checkpointing on Amazon SageMaker HyperPod," September 2025.
- Alluxio Write Cache performance (P99 < 2 ms write latency; 7.6 GiB/s peak write throughput per worker; 20 GiB/s peak across a three-worker cluster; <2% write-back overhead): internal benchmark using Alluxio Write Cache WRITE_BACK mode, ien.24xlarge worker nodes, c5n.18xlarge FUSE clients, 256KB block size. Results will vary by environment.
- "Up to 2x faster checkpoint writes" from no-rename optimization: Alluxio AI 3.9 release notes, internal product documentation.
- FSx for Lustre pricing (~$143–600/TB/month depending on tier) and S3 Standard pricing (~$23/TB/month): AWS published pricing, current as of May 2026. S3 Express One Zone pricing (~$110/TB/month): AWS published pricing. Alluxio NVMe cache tier cost estimate ($11–42/TB/month): derived from GPU cloud instance NVMe storage costs (AWS ien.24xlarge, c5n.18xlarge) plus S3 Standard backend.
- RDMA transport in Alluxio AI 3.9 supports read I/O only. Write cache operations use standard TCP transport in this release. RDMA write support is planned for a future release. Alluxio AI 3.9 release notes.


.avif)