X
Complete the form below to access the full whitepaper:
The Multi-GPU Cluster World
Organizations pursuing state-of-the-art AI capabilities now operate in a fragmented landscape where GPU resources are distributed across multiple environments, spanning multiple regions in a cloud, multiple public clouds, private datacenters, and specialized AI infrastructure providers.
This multi-GPU cluster architecture emerged not by design but by necessity. The global GPU shortage, fueled by exploding demand across industries, has forced infrastructure teams to adopt a "compute wherever available" approach. Rather than waiting months for concentrated GPU allocations in a single location, organizations now piece together computational capacity across different environments.
This approach introduces critical data-related challenges, including:
- Training Job Delays: The separation between central data lake and GPUs can introduce latency in data access, slowing down AI training jobs.
- High Costs: Moving data between different clouds is expensive. When you move data out of a cloud provider, they charge egress fees (also known as data transfer costs), which can quickly escalate with large data sizes.
- Data Management Complexity: To avoid high egress costs, organizations may choose to duplicate data across different cloud environments, leading to management complexity, data consistency challenges, and additional data delays.
The consequences of these challenges directly impact the metrics that matter most: GPU utilization, training completion times, and infrastructure costs.
Diagnosing Low GPU Utilization
GPU utilization, or GPU usage, is the percent of available GPU processing power being used at a particular time. High GPU utilization (80% or above) indicates that the end-to-end AI/ML workloads are effectively utilizing the available compute resources for complex calculations. On the other hand, low GPU utilization indicates that the end-to-end AI/ML workloads are hitting one or more bottlenecks in steps prior to the calculations being executed on the GPUs.
According to a recent survey on AI infrastructure, a majority of AI/ML teams struggle to garner the full potential of their GPU investment. With only 7% of respondents indicating GPU utilization exceeding 85% during peak periods, organizations have made improving GPU utilization a top priority.

Common Causes of Low GPU Utilization in Model Training
As with any complex software system, there are a number of root causes that can cause AI/ML workloads to underutilize GPUs and thus suffer poor performance. Before we explore the most common causes, let’s first understand at a high level the key stages of AI/ML model training as they relate to GPU utilization:
- The AI/ML model training code, using CPU resources, locates and then loads training data from storage into CPU memory.
- With the data in CPU memory, model training code transforms the data, again using CPU resources, in preparation for the subsequent model training calculations.
- Once the data is prepared, the transformed data is copied from CPU memory to GPU memory and the model training calculations are executed using GPU resources.
With this basic understanding, we can now explore common factors contributing to underutilized GPUs organized in two categories: Infrastructure Bottlenecks and Code Bottlenecks.
Infrastructure Bottlenecks
As outlined above, the AI/ML model training code locates and loads training data from storage into CPU memory and then performs data transformations. With training datasets in the hundreds of terabytes range and above, it is extremely common for bottlenecks to occur in the data loading and transformation phases due to:
- The physical distance between the storage system and the GPU clusters introduces bandwidth and latency constraints that negatively affect the performance of the AI workloads and the utilization of GPU resources.
- Storage systems hosting the training data are unable to meet the I/O bandwidth and latency requirements of the AI/ML workload’s data loading phase.
- The network between the storage system and the GPU servers does not meet the bandwidth and latency requirements of the AI/ML workload.
- The available CPU resources are unable to process the data transformation code fast enough to meet the AI/ML workload requirements.
- While not part of data loading or transformation, another common bottleneck is introduced when the AI/ML workload periodically writes model checkpoint files to the storage system.
Code Bottlenecks
While infrastructure bottlenecks are the most common, inefficient coding practices can further exacerbate infrastructure limitations or introduce new bottlenecks into the system. The most common code–related bottlenecks include:
- Inefficient data transformation code that overloads the CPU resources, introducing a bottleneck before the data is copied to GPU memory.
- Workloads that don’t effectively parallelize computations can leave GPUs idle. GPUs are designed for and excel at executing multiple threads in parallel, however applications must be designed to execute in parallel.
- Training workloads using batch sizes that are too small can also lead to low GPU utilization. Batch size is a hyperparameter that determines the amount of training data used during each iteration or training step of an epoch. The batch size must be optimized to load enough data for each iteration to keep GPUs busy.
Optimizing Data Loading into GPU Clusters
I/O Bottlenecks Reduce GPU Utilization and Slow Down AI Workloads
For any application, bottlenecks at the storage or network layer diminish the utility of the compute layer. AI training applications are no different, except for the exorbitant cost of the bottleneck, measured in infrastructure and productivity costs, and often, lost revenue.
When storage or network bottlenecks prevent sufficient training data from reaching GPUs, it creates a "Data Stall." Data Stalls are the primary cause of low GPU utilization and poor AI workload performance. Since model training calculations require a steady stream of data to be loaded into GPU memory, it is paramount that I/O bottlenecks are eliminated in order to optimize GPU utilization and improve end-to-end model training performance.
There are two primary aspects of model training that involve I/O operations:
- Data Loading, as the name implies, is the process of loading training datasets from storage into the GPU server’s CPU memory. The data loading process (using PyTorch’s DataLoader, for example) issues both sequential and random read I/O requests to the storage system hosting the training data. Model training typically requires multiple epochs (an epoch is a full run of the training code using the entire training dataset) and therefore, the data loader will read the training datasets from the storage system multiple times throughout the life of the training project.
- Model Checkpointing is the process by which the training code periodically saves the model state to disk. In the event there is a failure during training, the saved model state can be reloaded and training can resume from that point in time. Checkpointing is an expensive operation because the training calculations are paused until the model state files are written to disk. Most training workloads checkpoint after each iteration, which is a full pass of the training code on a single batch of data. Throughout an epoch, the model state files grow larger with each iteration and can reach hundreds of gigabytes in size or more.

With a better understanding of the interactions between model training applications, GPUs, and storage systems, let’s look at several factors that result in slow I/O and data stalls during model training:
- Hybrid/Multi-Cloud Architecture: GPU computation was traditionally optimized to co-locate with datasets. However, computation and storage are now disaggregated in modern data architectures, especially in hybrid or multi-cloud environments. With the high-cost of GPUs and ongoing supply constraints, teams are running training workloads wherever the lowest-cost GPUs are available. This means that the GPU clusters where the training workloads run are geographically located in different datacenters, clouds, or regions than the training datasets. These all lead to slow data access.
- Inefficient Storage Throughput: Traditional storage systems equipped with hard disk drives (HDDs) are not capable of delivering the throughput AI applications require. They have slower read/write speeds compared to solid-state drives (SSDs), making them unsuitable for high-performance tasks like large-scale data loading.
- High I/O Storage Latency: Data access from object storage systems, such as Amazon S3 or Google Cloud Storage, can introduce significant latency. This is especially problematic when training data is distributed across geographically distant regions or accessed frequently without caching.
- Network Bandwidth Constraints: Network-attached storage (NAS) or distributed file systems may experience bandwidth limitations, especially when multiple processes or users compete for the same resources. This congestion can drastically slow down data transfer speeds.
How to Address I/O Bottlenecks
When designing AI training infrastructure, platform engineers typically consider three main approaches for storing and accessing training data. Each option presents different trade-offs in terms of performance, cost, and operational complexity.
There are four common options for storing and accessing AI training data.
Option 1: Direct Access to Cloud Object Storage
Direct access is the most straightforward approach as it doesn’t introduce additional layers or require data movement and it ensures training workloads access the latest data. Training applications, running on GPU servers that may or may not be located in the same cloud or region as the cloud object storage, access data using the storage system’s native APIs. The training applications must read data from cloud storage for every epoch. While the advantage of this approach is simplicity, the disadvantages for large-scale training are significant:
- Low performance due to network latency and limited aggregate bandwidth. As noted earlier, this can leave GPUs starving.
- Potentially high costs (for cloud object stores, every read request and data egress costs money).
- Concurrent access from many nodes to cloud object storage can trigger rate limits by the cloud provider that introduce further I/O latency and bandwidth issues.
- Strong coupling: training code might need to know about the storage specifics (paths, APIs), and if you change storage backends, engineers have to modify the code or configs for all jobs.
Option 2: Local Node Caching (e.g. S3FS/FUSE on each node)
This approach installs a file system adapter (like s3fs for Amazon S3) on each training node. It can cache files in the local filesystem of that node. This helps avoid repeatedly downloading the same file on that node – within a single node’s lifetime, epochs after the first will hit the local disk cache. It also provides a file system interface, so code can open paths normally. While better than no cache, there are still problems:
- No sharing of cache between nodes: If you have 8 nodes reading the same data, each node will download its own copy into its cache. That’s redundant network I/O and storage.
- Limited capacity per node: A node-level cache might only hold what fits on that machine. If the dataset is larger, it will evict and re-download data constantly.
- Lack of advanced management: Simple caches often use least-recently-used eviction and that’s it. You may require more advanced mechanisms to control and optimize the cache, which can be crucial for ML (e.g. ensure validation data stays in cache even if it’s accessed less often than training data).
- Consistency and data engineering features: Basic fuse might not handle consistency at all (it may show stale data or no easy way to refresh except manually clearing cache). This is important if your pipeline updates a training dataset incrementally.
Option 3: Dedicated High-Performance Storage
Introducing a high-performance storage solution between the training nodes and cloud object storage is the third option. These solutions aim to deliver low latency, high throughput performance and typically include distributed architectures with data stored on SSD drives and managed by a parallel file system. While there are various offerings on the market with different features and capabilities, the common problems include:
- Expensive: These solutions are generally quite expensive and require dedicated infrastructure. If you run GPU clusters in multiple clouds or datacenters, then deploying these solutions in each location will substantially increase your total cost.
- Complex: Installing, configuring, and ongoing management for these solutions is non-trivial. Initial implementation requires a significant time investment from the infrastructure team and on-going management and administration also requires time and effort.
- Manual Data Copy: While some solutions offer integrations with cloud object storage, most solutions require source data to be copied manually from the cloud object store to the storage solution. Model training jobs can’t start until all training data has been copied and verified.
- File/Object Granularity: Whether your AI workload needs the entire contents of a file/object or just a small subset, these systems copy and store entire files. This increases the total storage capacity needed to support AI workloads, increasing not only hardware costs but also software costs derived from total capacity.
- Vendor Lock-in: While vendor-dependent, solutions may require specific hardware or only support certain cloud providers. These requirements limit flexibility and workload portability. With scarce GPU resources available - this can be a non-starter for many AI teams.
Option 4: Alluxio Distributed Cache
Alluxio’s read-through distributed cache automatically caches active or hot data, while inactive data remains on disk in the underlying storage system (S3 for example). Applications access data through Alluxio’s FUSE-based POSIX filesystem, S3 API endpoints, or a Python SDK. Alluxio retrieves data from cache if available and from the underlying storage if not, maximizing cost-efficiency without sacrificing performance.
Unlike single-node caches (e.g. a local S3Fuse on each machine), Alluxio coordinates a cluster-wide cache. Data cached on one node can be served to other nodes, avoiding redundant transfers. The cache is distributed across the NVMe drives of all nodes, which means even datasets larger than a single node’s storage capacity can be cached in aggregate. This is crucial for large AI datasets (tens of TBs): Alluxio can hold the working set in the cluster, whereas per-node caching would thrash.
Compared to dedicated high-performance storage solutions, Alluxio’s intelligent and dynamic caching minimizes your infrastructure footprint for a much lower total cost, while also delivering low latency, high throughput performance. Specifically, Alluxio:
- Intelligently caches only subsets of files containing the data needed for the workload to minimize cache capacity requirements and maximize transfer speeds from cloud storage to cache.
- Pre-fetches data and replicates “hot” slices to multiple nodes for parallel training. For instance, if certain user embeddings or product features are accessed repeatedly, Alluxio can detect this and keep multiple copies on different nodes’ NVMe storage for faster multi-GPU access.
- Automatically evicts infrequently accessed data as needed, while supporting custom data eviction and retention policies to ensure cache efficiency.
- Cost-effectively ensures low-latency, high-throughput performance for multi-GPU cluster deployments across different clouds, regions, or datacenters without duplicating source data in each location or maintaining multiple source of truth data stores.
Alluxio distributed caching addresses the problems and limitations of the other approaches with limited downside: adding an additional layer to manage.
Each option has its pros and cons. As you can see from the table below, Alluxio distributed caching provides substantial technical advantages and addresses the fundamental challenges of large-scale AI training environments by maintaining a single source of truth while intelligently managing data locality.

Alluxio AI Overview
The Critical Role of Alluxio in the AI Infra Stack
Alluxio is a critical component in the AI/ML stack. Alluxio solves data loading performance bottlenecks and enables full utilization of GPU resources without infrastructure teams having to invest in complex, expensive storage solutions or duplicate entire persistent data stores closer to GPU clusters.

Alluxio provides the following benefits:
- Accelerated Training Data Access: Alluxio caches frequently accessed data closer to compute nodes, reducing the latency associated with remote storage access.
- Unified Data Access: Alluxio abstracts underlying storage systems, enabling compute frameworks to access heterogeneous storage systems through a single namespace.
- Lower Cloud Storage Costs: With data cached in Alluxio, less data is transferred out of cloud storage and AI workloads make fewer data access requests, resulting in lower egress and data access fees from cloud providers.
- Enhanced GPU Utilization: Faster and more reliable data access ensures that GPUs remain active and productive, avoiding idle time due to data starvation.
- Reduced Bandwidth Consumption: By caching data locally, Alluxio minimizes repeated network calls to remote storage, significantly reducing bandwidth consumption.
Key Features of Alluxio AI

1. Distributed Caching For Faster Data Loading and Model Checkpointing
Distributed caching is at the core of Alluxio's architecture, enabling high-performance data access and seamless scalability for large-scale AI infrastructure. Alluxio ensures efficient resource utilization, enhanced fault tolerance, and improved throughput by sharding the cached data across multiple nodes in a cluster. This robust distributed design empowers Alluxio to address the demands of modern AI workloads, which are characterized by their size, complexity, and need for low-latency data access.
Alluxio’s distributed caching is optimized to handle both latency-sensitive and high-throughput AI training workloads by leveraging NVMe SSDs to store frequently accessed data. This design provides sub-millisecond access times, ensuring GPUs remain fully utilized and never starved for data.
- Data loading (Read Optimization): Alluxio accelerates data loading by caching training data on NVMe SSDs close to or collocated with GPU clusters. This ensures low-latency, high-throughput data access, keeping GPUs fully utilized during data loading.
- Checkpointing (Read & Write Optimization): Alluxio accelerates saving and restoring checkpoint files through caching, enabling faster writes and low-latency reads for checkpoints. By caching data locally on NVMe SSDs, Alluxio supports rapid writes and reduces delays from remote storage, ensuring efficient and reliable checkpointing.
To scale effectively, Alluxio employs consistent hashing, a proven technique for evenly distributing data across cache nodes in the cluster. This approach delivers several key benefits:
- Efficient Resource Utilization: Data is distributed evenly across nodes, preventing hotspots where some nodes become overloaded while others remain underutilized.
- Dynamic Scaling: When nodes are added to the cluster, Alluxio automatically redistributes cached data, maintaining balanced workloads without requiring a full cache rebuild.
- Fault Tolerance: In the event of a node failure, consistent hashing ensures minimal data movement to rebalance the cache across the remaining nodes, preserving cluster performance with minimal disruption.
Alluxio’s distributed caching capabilities are a cornerstone of its value within the AI infrastructure stack. With unlimited scalability through consistent hashing, low-latency data access via SSD caching, and high throughput, Alluxio enables AI workloads to operate at peak efficiency. By bridging the gap between diverse storage systems and compute frameworks, Alluxio empowers organizations to scale their AI infrastructure without sacrificing performance or cost-effectiveness.
2. Cache Preloading and Management
Effective cache preloading is critical for optimizing the performance of caching systems, particularly in AI workloads where efficient data access patterns significantly impact overall throughput and latency.
Alluxio offers two flexible methods for warming up the cache:
- Proactive Cache Preloading: Users can explicitly load data into the cache by running a CLI command or using an API call to prefetch specific datasets into the Alluxio cluster. This ensures that data is immediately available for workloads, minimizing latency and enabling peak performance from the start.
- Passive Cache Loading: Alternatively, Alluxio can passively populate the cache by fetching data on demand as applications read it. This approach automatically adapts to dynamic and unpredictable workloads, caching only the data actually accessed.
By supporting both methods, Alluxio provides the flexibility to meet a variety of workload requirements, ensuring frequently accessed data is readily available while reducing dependencies on remote storage systems.
Given the finite storage capacity in Alluxio’s cache, efficient cache management is essential to ensure new data can be accommodated without degrading performance. Alluxio employs a robust cache eviction system with multiple configurable strategies, including:
- Least Recently Used (LRU): Evicts data that has not been accessed recently, prioritizing frequently accessed data.
- First-In, First-Out (FIFO): Removes the oldest cached data first, ensuring newer data is prioritized.
- Least Frequently Used (LFU): Evicts data accessed less frequently, making space for more frequently used datasets.
Infrastructure teams can also create custom cache eviction and retention policies based on the needs of a specific workload. For example, a policy can ensure a specific dataset is never evicted or that certain datasets are prioritized such that, regardless of how recently or often the data is accessed, the dataset will be last in line for eviction.
These eviction strategies allow users to tailor cache management to their specific workloads, balancing the trade-offs between recency, frequency, and space availability.
3. Unified Namespace – Unified Logical “alluxio://” Namespace
Alluxio’s unified namespace is a foundational capability that abstracts the complexities and differences of underlying storage systems, providing a single, cohesive view of data distributed across multiple backends. By consolidating access under a unified namespace, Alluxio simplifies data access for compute frameworks, enhances distributed caching, and streamlines workflows across diverse storage environments. This powerful abstraction bridges the gap between disparate storage systems and compute workloads, delivering high performance, increased flexibility, and ease of use.
The unified namespace in Alluxio is represented by the alluxio:// scheme, offering a global, logical view of all mounted storage systems. This feature consolidates data from multiple backends into a single directory structure, simplifying application development and data management.
- Global View of Discrete Storage Systems: All storage systems—whether cloud-based, distributed, or on-premise—are presented as part of the alluxio:// namespace. For instance:
- An object store like S3 can be mounted as alluxio:///s3_data.
- A distributed file system like HDFS can be mounted as alluxio:///hdfs_data.
- Applications and users can traverse this unified directory structure seamlessly without needing to account for the specific protocols or APIs of the underlying storage systems.
- Preserving Physical Addresses: For scenarios where the original storage address is preferred or required, users can still use native paths (e.g., s3:// or hdfs://) to indicate the physical location of data. Alluxio respects these references while continuing to provide its caching and data acceleration benefits, ensuring compatibility and flexibility.
Alluxio supports mounting a broad range of storage systems, including:
- Object Stores: Amazon S3, Google Cloud Storage, Azure Blob Storage, and more.
- Distributed File Systems: HDFS and other similar systems.
- On-Premise Storage Systems: NAS or other traditional storage solutions.
4. Enterprise-Grade Security Features
TLS and integration with Apache Ranger:
- TLS Support: Transport Layer Security is supported, which ensures secure communication between Alluxio components and between Alluxio and Under File Systems (UFS).
- Apache Ranger Integration: Alluxio integrates directly with Ranger to manage and enforce policies at the Alluxio namespace level.
View details in the documentation: https://documentation.alluxio.io/ee-da-en/security.
5. Other Features
To learn more about other features, please refer to the documentation page: https://documentation.alluxio.io/ee-ai-en.
Case Study: Global Top 10 E-Commerce Giant Accelerates Training of Search & Recommendation AI Model
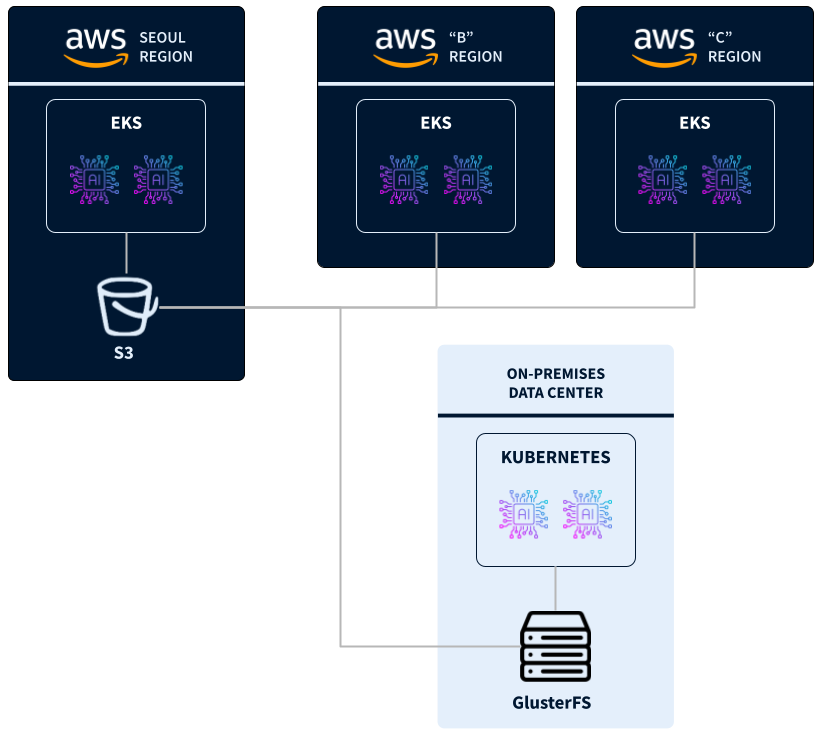
A large, publicly traded global e-commerce company builds and trains AI/ML models to enhance and customize product search and recommendation results for its 100+ million customers. The company’s training data, stored in AWS S3, has grown to hundreds of petabytes. The AI/ML training workloads were distributed across multiple AWS regions and in an on-premises data center.
Challenges
AI/ML training workloads running on AWS access training data directly from S3. Each training workload running in its on-premises data center downloads training data from S3 and stores it in network attached storage with Gluster FS.
With this strategy, this e-commerce giant suffered from storage and network bandwidth constraints, causing slow and unstable AI/ML training workloads. Additionally, they faced:
- High AWS S3 API and egress costs
- Low GPU utilization during training jobs
- High cost and operational complexity of managing Gluster FS and associated hardware
Alluxio’s Solution
Since deploying Alluxio AI, this e-commerce company’s AI/ML training workloads have become faster and more stable while also:
- Reducing AWS S3 API and egress charges by over 50%
- Improved GPU utilization by 20%
- And reduced operational complexity in their on-premises data center
Summary
In today's AI infrastructure landscape, optimizing GPU utilization through effective I/O management represents a critical challenge for platform engineers. This white paper explores how I/O bottlenecks can significantly impact training performance and infrastructure costs.
Modern AI workloads demand a sophisticated approach to data access and management. Traditional storage architectures, whether direct cloud storage access or high-performance storage systems, often struggle to effectively meet these demands. Alluxio emerges as a transformative solution, providing the performance of high-end storage systems while maintaining the simplicity and cost-effectiveness of cloud storage.
Through its distributed architecture, intelligent cache management, and deep integration with AI frameworks, Alluxio enables near-linear scalability with consistently high performance, while lowering storage infrastructure costs by decoupling storage performance from storage capacity. With Alluxio, organizations can leverage low-cost yet low-performance storage solutions as their persistent data stores while relying on Alluxio to ensure fast and scalable data access to AI training workloads.
.png)
White Paper

Storing data as Parquet files on S3 is increasingly used not just as a data lake but also as a lightweight feature store for ML training/inference or a document store for RAG. However, querying petabyte- to exabyte-scale data lakes directly from cloud object storage remains notoriously slow (e.g., latencies ranging from hundreds of milliseconds to several seconds on AWS S3).
This Whitepaper introduces how RAG and Feature Stores can benefit from Alluxio’s high-performance caching, serving as an acceleration layer atop hyperscale data lakes for queries on Parquet files. Alluxio enables direct, ultra-low-latency point queries on Parquet files, achieving submillisecond latency per query and 3,000 queries per second on a single thread—representing a 1,000x performance gain over querying Parquet files stored on S3 Standard and achieves equivalent latency as S3 Express but at a fraction of the cost.

Are you struggling with slow data access, managing AI infrastructure at scale, low GPU utilization, or budget constraints in Geo-distributed GPU clusters?
In this insightful white paper, we’ll discuss common causes of slow AI workloads and low GPU utilization, how to diagnose the root cause, and offer solutions to the most common root cause of underutilized GPUs. You'll learn:
- Challenges introduced by multi-GPU cluster architecture and the metrics they impact
- Diagnosing and common causes of low GPU utilization
- How to optimize data loading in order to address the I/O bottlenecks
- How Alluxio Distributed Cache solves data loading performance bottlenecks and enables full utilization of GPU resources
- A case study of a global e-commerce giant, showcasing how Alluxio accelerates slow and unstable AI/ML training workloads with 20% improvment in GPU utilization and 50% cloud cost reduction
.avif)
AI Platform and Data Infrastructure teams rely on Alluxio Data Acceleration Platform to boost the performance of data-intensive AI workloads, empower ML engineers to build models faster, and lower infrastructure costs.
With high-performance distributed cache architecture as its core, the Alluxio Data Acceleration Platform decouples storage capacity from storage performance, enabling you to more efficiently and cost-effectively grow storage capacity without worrying about performance.
- Data Acceleration
- Simplicity at Scale
- Architected for AI Workload Portability
- Lower Infrastructure Costs
In this datasheet, you will learn how Alluxio helps eliminate data loading bottlenecks and maximize GPU utilization for your AI workloads.