Alluxio AI
Alluxio accelerates data access at every stage of the AI lifecycle – from model training to deployment and inference cold starts to feature store queries – all without replacing your storage or changing your code.
Accelerated by Alluxio






How Alluxio Works at a Glance
Intelligent Caching Brings AI Data Closer to AI Workloads
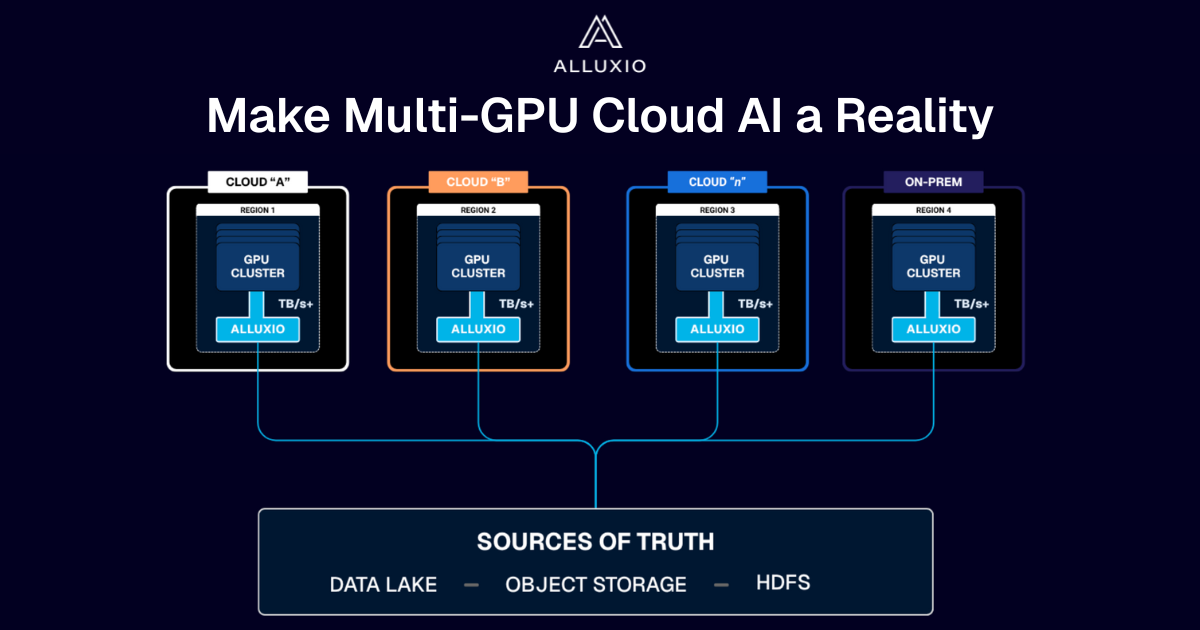
Alluxio deploys as a lightweight, distributed cache between your AI compute workloads (training jobs, feature stores, inference servers) and wherever your AI data is persistently stored (e.g., cloud storage like S3, data lakes, NFS).
GPU SERVER
GPU SERVER
GPU SERVER
ALLUXIO
S3 API
POSIX CLIENT
PYTHON SDK
GLOBAL NAMESPACE
DISTRIBUTED CACHING
CLOUD STORAGE
NFS
HDFS
Alluxio automatically caches data on NVMe drives either leveraging excess capacity on existing GPU nodes or on dedicated CPU nodes — delivering data at local NVMe speed.
Designed for AI Workloads
Engineered for the Unique Demands of Machine Learning and Inference
AI workloads are different — they’re I/O intensive, GPU-bound, and often run at massive scale. Alluxio AI was purpose-built to address the key challenges platform teams face:
Faster Model Training
Eliminate I/O bottlenecks and saturate GPUs with high-throughput, low-latency access to training data.
Simplified Model Deployments
Efficiently serve and replicate large model artifacts (e.g., model checkpoints) across multi-region clusters.
No More Inference Cold Starts
Cache model files and inference inputs near the serving layer to reduce startup and response time.
Blazingly Fast Feature Stores
Get sub-ms TTFB to accelerate feature store queries powering your inference and training workloads.
Key Alluxio Capabilities
Capability
Description
AI-Scale Caching
Optimized for billions of files/objects, petabyte+ scale, repeated access, and bursty I/O
Cloud-Native
Easy to deploy and scale across containerized environments with Kubernetes Operator; integrated metrics, tracing, and observability
Sub-ms TTFB Latency
Get sub-ms time to first byte (TTFB) latency for feature store queries, agentic AI, and inference serving
Pluggable Storage
Seamlessly integrates with S3, GCS, Azure, HDFS, NFS, on-prem object stores, and more
Transparent & Seamless to Use
Alluxio S3 API, POSIX interface, and Python SDK means no changes to code or workflows
Custom Cache Policies
Customize by dataset, priority, TTL, or workload pattern
Distributed Cache Preloading
Preload Alluxio to warm up the cache before AI workloads start to optimize I/O access from the start
Observability Built-In
Monitor cache hit ratios, latency, throughput, and more via APIs and UI