Raft is an algorithm for state machine replication as a way to ensure high availability (HA) and fault tolerance. This blog shares how Alluxio has moved to a Zookeeper-less, built-in Raft-based journal system as a HA implementation.
Introduction
Alluxio implements a virtual distributed file system that allows accessing independent large data stores with compute engines like Hadoop or Spark through a single interface. Within an Alluxio cluster, the Alluxio master is responsible for coordinating and keeping access to the underlying data stores or filesystems (UFS for short) consistent. The master contains a global snapshot of filesystem metadata, and when a client wants to read or modify a file, it first contacts the master. Given its central role in the system, the master must be fault tolerant, highly available, strongly consistent, and fast. This blog will discuss the evolution of the Alluxio master from a complex multi-component system using Zookeeper to a simpler and more efficient one using Raft.
The operation of a file system can be thought of as a sequence of commands performed on the system (e.g., create/delete/read/write). Executing these commands one at a time in a single thread gives us a sequential specification for our file system that is easy to reason about and to implement applications on top of. While this sequential specification is simple, the actual implementation of Alluxio’s virtual distributed file system consists of many moving parts all executing concurrently: the master who coordinates the system, the workers who store the file data and act as a cache between the client and the UFS, the UFSs themselves, and the clients who, at the direction of the master, access all other parts of the system. Again here, we may want to reason about each of these individual components as a sequential thread executing one operation at a time, but in reality, they are running complex systems themselves.
The core problem we want to solve here is how to make the Alluxio master seem like it is being run by a single node running a single operation at a time so that it is simple to implement and easy for other components to interact with, yet still be fault tolerant and highly available. Furthermore the master must be fast enough to perform tens of thousands of operations per second and scale to support the metadata of hundreds of millions of files.
The Journal and HA (Highly Availability)
The internal state of the Alluxio master is made up of several tables containing the filesystem metadata, the block metadata, and the worker metadata. The filesystem metadata consists of an inode table which maps each directory and file’s metadata (its name, parent, etc) to a unique identifier called the inode id, and an edge table that maps directories to their children using the inode ids. The actual data of each file is split into one or more blocks located on the Alluxio workers which can be located using the block metadata table which maps each file to a set of block identifiers and the worker metadata table which maps each worker to the list of blocks it contains.
Each operation that modifies this metadata, for example creating a new file on the virtual file system, outputs a journal entry containing the modifications made to the tables. The journal entries are stored in the order they are created in a log, thus satisfying our sequential specification of the master. Starting from an initial state and replaying these journal entries in order will result in the same state of the metadata, allowing a master node to recover after a failure. To ensure the journal does not grow too large, snapshots of the metadata will be taken periodically. Now if this journal is stored in a location that is highly available and fault tolerant, then we have a basis for our reliable system. For example, we can start a single node and assign it the role of master. Some time later, if we detect that the node has failed, then a new node is started, it replays the journal, and takes its place as the new master. One possible issue with this is that it may take a long time to start a new node and replay the journal, during which time the system is unavailable. To increase the availability of the system, we can have multiple replicas of the master running at the same time where only one is serving client operations (call this master the primary master), while the others are just replaying journal entries as they are created (call these masters the secondary masters). Now when the primary master fails, a secondary master can take over immediately as the new primary master.
Implementing Our Initial Design
From this basic design, there remain two problems to solve, 1: How to ensure there is a single primary master running at all times, and 2: how to ensure the journal itself is consistent, fault tolerant, and highly available. Starting from 2013, we introduced the initial implementation to resolve these two problems.
The first is solved by Zookeeper [1]. Zookeeper is a highly reliable distributed coordination service providing a filesystem-like interface running over the ZAB [2] consensus algorithm. Zookeeper provides a leader election recipe [3] where multiple nodes can join the recipe and a single node will be chosen as the leader. If a leader is no longer responsive for a certain period then a new leader will be chosen. In Alluxio all masters start as secondary masters and join the Zookeeper leader election recipe, when the recipe elects a node as leader it can then step-up to primary master.
To solve the second problem and ensure the journal is highly available and fault tolerant, the journal entries are stored on the UFS. Of course a UFS that is available and fault tolerant should be used. Finally, the journal must be consistent. As described earlier the journal entries should be a totally ordered log of events satisfying our sequential specification. As long as there is no more than one primary master running at a time it can just append journal entries to a file in the UFS to satisfy consistency. But doesn’t our leader election recipe already ensure this? If we have a perfect failure detector or a synchronous system, then yes, but unfortunately we have neither. When Zookeeper performs a leader election it will notify the previous leader it has lost its leadership before electing the new leader, but if the previous leader (or the network) is slow, it may still be appending entries to the journal when the new leader is elected. As a result, we may have multiple primary masters appending to the journal concurrently. To reduce the chance of this happening, a mutual exclusion protocol is run using the consistency guarantees of the UFS by using a specific file naming scheme.
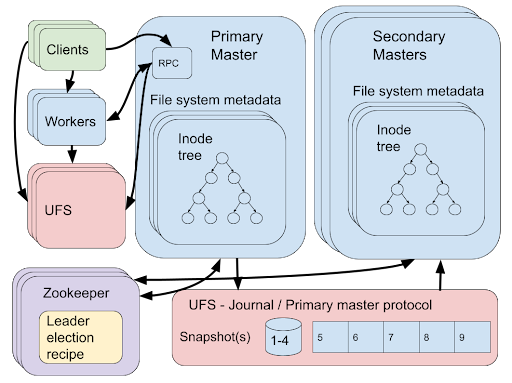
Let us examine some of the issues of this solution. First, it relies on several external systems, Zookeeper and a UFS, running alongside the Alluxio masters. This complicates the design and analysis of the system. Each component has a different fault and availability model to consider. The choices between different UFSs also complicate the system, for example, one UFS may not provide high performance with frequent small append operations. Furthermore, each UFS may have different consistency guarantees, complicating the case when two concurrent Primary Masters are trying to write to the journal. For these reasons, HDFS is the recommended UFS for this configuration.
We now describe how a simpler and more efficient design can be made using Raft.
An Improved Design Based on the Replicated State Machine
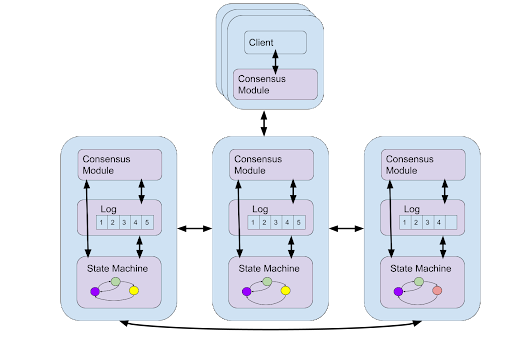
First let us introduce the concept of a (replicated) state machine. A state machine takes as input a series of commands which modify the internal state of the system and may produce some outputs. For our case, the state machine must be deterministic, namely given the same set of inputs, the system will produce the same outputs. If we think of our journal as a state machine, we can think of it as simply a log which has an append command that appends a journal entry to the end of the log. A replicated state machine is then a state machine that provides high availability and fault tolerance. It does this by replicating the state machine over multiple nodes and running a consensus algorithm to ensure the same commands are run in the same order at each replica. Raft [4] is one such replicated state machine protocol, a user just needs to provide a deterministic state machine as input to the protocol. One important property about Raft is that it ensures the consistency condition of linearizability[5]. Consider that each command executed on the replicated state machine by a client has an invocation and response. Linearizability ensures that an operation is observed by all clients to have taken place at some instant in time between the invocation and response. This instant in time is called the operation’s linearization point. The linearization points of all operations give us a total order of the operations following the sequential specification of the state machine being implemented. So even though our state machine is replicated, to the client it appears to be executing operations sequentially in real time.
Implementing the Journal using Raft
Now we could simply provide the log of journal entries as the state machine to be replicated by Raft, but we can simplify the system further. Recall that the reason for representing the state as a log of journal entries was to allow masters to recover to the most recent state by replaying the journal entries. Since Raft takes care of fault tolerance, we can use a higher level of abstraction for our state machine that represents the state of the master. This is simply the collection of tables containing the state of the metadata of the Alluxio file system. The master will execute its normal operations, and provide to the statemachine commands that represent modifications to the tables, which are clearly deterministic. Raft internally handles the logging, snapshotting and recovery of the state in case of failures. The Raft code runs alongside the Alluxio code on the master nodes allowing quick access to the metadata in the tables stores.
The tables are implemented using RocksDB [6]. RocksDB is an on-disk key-value store implemented using a log-structured merge-tree [7] which allows for efficient updates. By using RocksDB the size of the filesystem metadata can grow larger than the memory available on the master nodes. Alluxio additionally implements an in memory cache above RocksDB to ensure reading keys is fast.
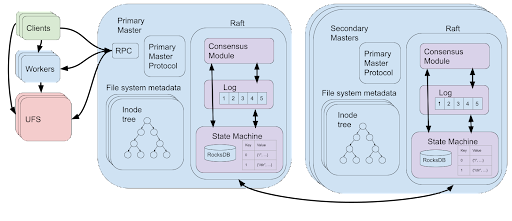
Like before, a single master node will be designated the primary master which serves the client requests. This is because the virtual file system operations that create the journal modifications should only happen at the primary master as they may modify external state (the UFS and worker nodes). Raft internally uses leader election as part of its consensus algorithm which Alluxio uses to appoint a primary master. To decrease the likelihood of two primary masters running concurrently, Alluxio adds an additional layer of synchronization allowing the previous primary master to explicitly step-down or timeout before the new primary master starts serving client requests.
Using Raft has greatly simplified the implementation and improved the performance and scalability of the highly available and fault tolerant masters of Alluxio. The running of the external systems of Zookeeper and a UFS has been replaced with the Apache Ratis [8] implementation of Raft running directly on the Alluxio master nodes. The concept of a low level log to be replayed after recovery is no longer needed. Instead, we only need to access fast key-value stores using RocksDB, which are efficiently and consistently replicated by Raft to ensure high availability and fault tolerance. We also recommend reading how Confluent simplified and improved the performance of their distributed architecture by moving from Zookeeper to Raft in Apache Kafka [9].
References
[1] Hunt, Patrick, et al. "{ZooKeeper}: Wait-free Coordination for Internet-scale Systems." 2010 USENIX Annual Technical Conference (USENIX ATC 10). 2010. https://zookeeper.apache.org.
[2] Junqueira, Flavio P., Benjamin C. Reed, and Marco Serafini. "Zab: High-performance broadcast for primary-backup systems." 2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN). IEEE, 2011.
[3] Apache Curator Leader Election. https://curator.apache.org/curator-recipes/leader-election.html
[4] Ongaro, Diego, and John Ousterhout. "In search of an understandable consensus algorithm." 2014 USENIX Annual Technical Conference (Usenix ATC 14). 2014. https://raft.github.io.
[5] Herlihy, Maurice P., and Jeannette M. Wing. "Linearizability: A correctness condition for concurrent objects." ACM Transactions on Programming Languages and Systems (TOPLAS) 12.3 (1990): 463-492.
[6] RocksDB. http://rocksdb.org.
[7] O’Neil, Patrick, et al. "The log-structured merge-tree (LSM-tree)." Acta Informatica 33.4 (1996): 351-385.
[8] Apache Ratis. https://ratis.apache.org.
[9] Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper. https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/.
.png)
Blog


Coupang, a Fortune 200 technology company, manages a multi-cluster GPU architecture for their AI/ML model training. This architecture introduced significant challenges, including:
- Time-consuming data preparation and data copy/movement
- Difficulty utilizing GPU resources efficiently
- High and growing storage costs
- Excessive operational overhead maintaining storage for localized data silos
To resolve these challenges, Coupang’s AI platform team implemented a distributed caching system that automatically retrieves training data from their central data lake, improves data loading performance, unifies access paths for model developers, automates data lifecycle management, and extends easily across Kubernetes environments. The new distributed caching architecture has improved model training speed, reduced storage costs, increased GPU utilization across clusters, lowered operational overhead, enabled training workload portability, and delivered 40% better I/O performance compared to parallel file systems.

Suresh Kumar Veerapathiran and Anudeep Kumar, engineering leaders at Uptycs, recently shared their experience of evolving their data platform and analytics architecture to power analytics through a generative AI interface. In their post on Medium titled Cache Me If You Can: Building a Lightning-Fast Analytics Cache at Terabyte Scale, Veerapathiran and Kumar provide detailed insights into the challenges they faced (and how they solved them) scaling their analytics solution that collects and reports on terabytes of telemetry data per day as part of Uptycs Cloud-Native Application Protection Platform (CNAPP) solutions.