This is part 2 of the blog series talking about the design and implementation of the Cross Cluster Synchronization mechanism in Alluxio. In the previous blog, we discussed the scenario, background and how metadata sync is done with a single Alluxio cluster. This blog will describe how metadata sync is built upon to provide metadata consistency in a multi-cluster scenario.
Multi-cluster Consistency Using Time Based Sync
One use case for time based metadata sync is when using multiple Alluxio clusters which share a portion of the UFS data space. Generally we may consider that these clusters are running separate workloads that may need to share data at certain points in time. For example one cluster may ingest and and transform the data from one day, then another cluster may run queries on the data the next day. The cluster running the queries may not need to always see the most up to date data, for example a lag of up to an hour may be acceptable.
In practice using a time based sync may not always be efficient, as only specific workloads will update files at a regular interval. In fact, for many workloads the majority of files are only written once, whereas a small portion of files are updated frequently. Here time based sync becomes inefficient as the majority of synchronizations are unnecessary, and increasing the time interval will result in the frequently modified files remaining inconsistent for longer periods of time.
Multi-cluster Consistency Using Cross Cluster Sync
In order to avoid the inefficiencies of time based synchronization, the Cross Cluster Synchronization feature allows inconsistencies to be tracked directly so that files are only synchronized when necessary. This means that whenever a path is modified on an Alluxio cluster, that cluster will publish an invalidation message, notifying other Alluxio clusters that the path has been modified. The next time a client accesses this path on a subscriber cluster, a synchronization will be performed with the UFS.
Compared to time based synchronization, this has two main advantages, first synchronizations are only performed on files that have been modified, and second, modifications become visible to other clusters quickly, i.e. in about as long as it takes to send a message from one cluster to another.
From this we see that the cross cluster synchronization feature will be most useful when the following assumptions are satisfied:
- There are multiple Alluxio clusters which mount intersecting portions of one or more UFSs. (Here we expect there to be anywhere from 2 to 20 Alluxio clusters in the system.)
- At least one of the clusters is making updates to the files on the UFS(s).
- All updates to the UFS(s) go through the Alluxio clusters (see Section Other Use Cases on ways to handle other situations).
Now we want to ensure that updates coming from one Alluxio cluster will be eventually observed in all other Alluxio clusters (i.e. the clusters will be eventual consistency with the UFS) so that applications can share data across clusters.
Path Invalidation Publish/subscribe
The basis of the cross cluster synchronization feature is a publish/subscribe (pub/sub) mechanism. When an Alluxio cluster mounts a UFS path, it will subscribe to that path and whenever a cluster modifies a file on a UFS it will publish the path of the modification to all subscribers.
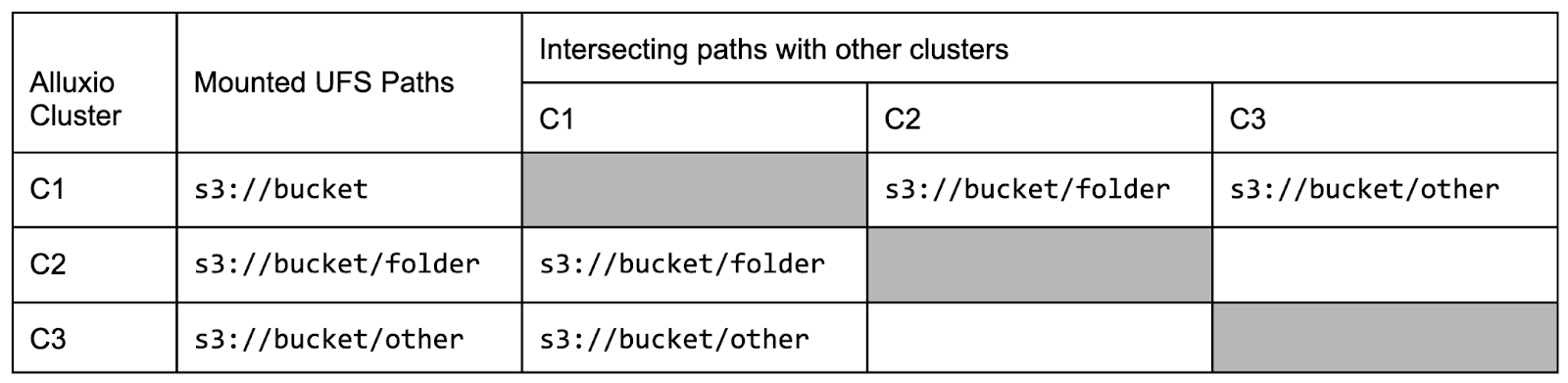
Table: An example where three Alluxio clusters mount different UFS paths.
Consider the example in Table 1 with three Alluxio clusters, each mounting a different S3 path. Here, cluster C1 mounts the S3 bucket s3://bucket to its local path /mnt/, cluster C2 mounts a subset of the same bucket s3://bucket/folder to its local path /mnt/folder, and finally C3 mounts s3://bucket/other to its root path /.
From this, C1 will subscribe to the path (i.e. topic in the language of pub/sub) s3://bucket, C2 will subscribe to the path s3://bucket/folder, and C3 will subscribe to path s3://bucket/other. Any message that is published which starts with the topic will be received at the subscriber.
Now, for example, if cluster C1 creates a file /mnt/folder/new-file.dat it will publish an invalidation message containing s3://bucket/folder/new-file.dat which will be received at subscriber C2. Alternatively if C1 creates a file /mnt/other-file.dat no message will be sent as there are no subscribers with a topic matching s3://bucket/other-file.dat.
As described previously, metadata in Alluxio includes the last time the path was synchronized. With cross cluster synchronization it also contains the last time an invalidation message was received for the path through the pub/sub interface. Using this, when a path is accessed by a client a synchronization with the UFS will be performed in either of the following cases:
- It is the first time the path is accessed.
- The invalidation time for the path is more recent than the synchronization time.
Assuming there are no failures in the system, it is fairly straightforward to show that eventual consistency will be ensured. Every modification to a file will result in an invalidation message being received at every subscriber cluster, resulting in a synchronization the next time the file is accessed.
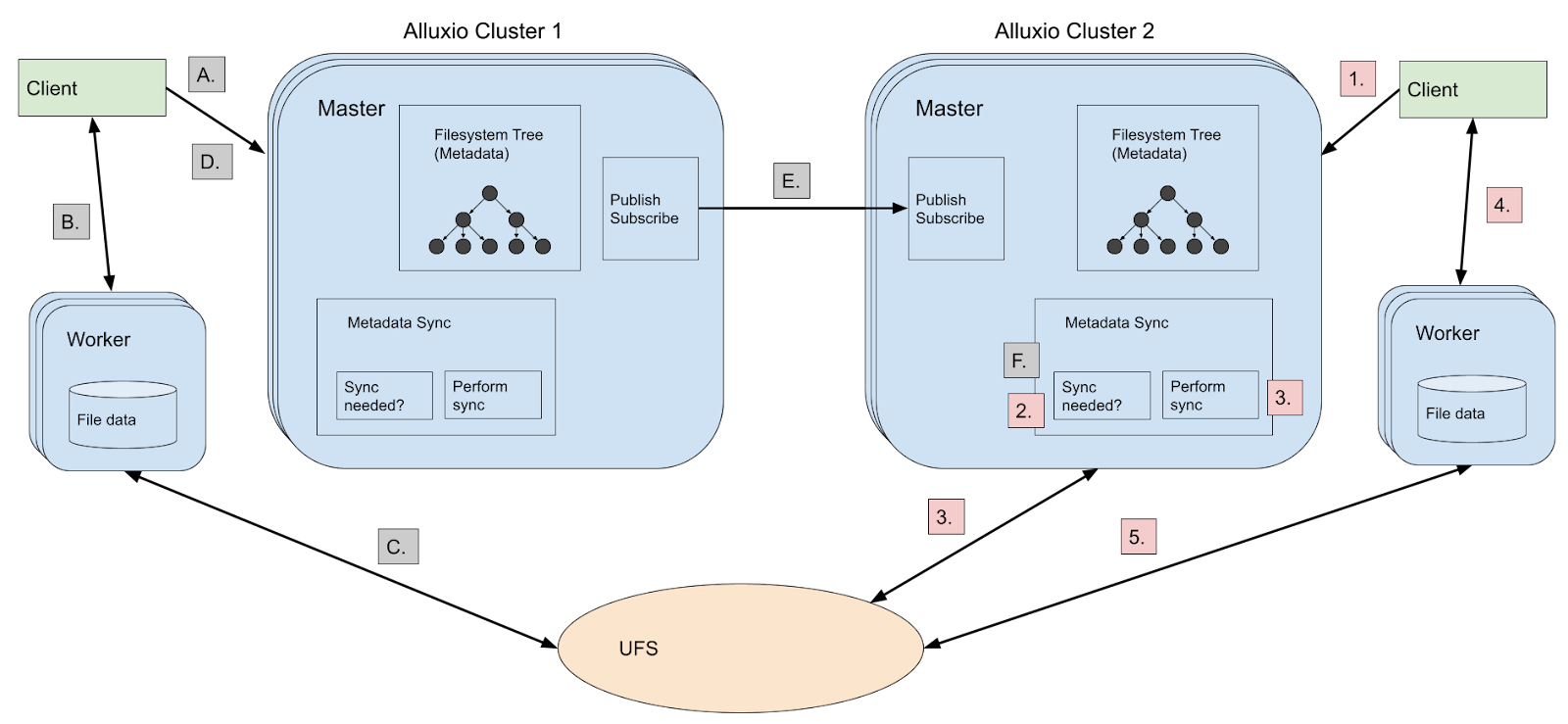
Figure: The cross cluster synchronization mechanism during file creation. A. A client creates a file on Cluster 1. B. The client writes the file to the worker. C. The worker writes the file to the UFS. D. The client completes the file on the master. E. Cluster 1 publishes an invalidation message for the file to the subscriber at Cluster 2. F. Cluster 2 marks the file as needing synchronization in its Metadata Sync component. Later when a client accesses the file, a synchronization will be performed using the same steps 1-5 as shown in Figure 1.
Implementing the Pub/sub mechanism
The pub/sub mechanism is implemented through the combination of a discovery mechanism allowing clusters to know which other clusters mount what paths, and a networking component used to send the messages.
The discovery mechanism is a single java process called the CrossClusterMaster which must be accessible by all Alluxio clusters through a configured address/port combination. Whenever an Alluxio cluster is started, it will inform the CrossClusterMaster of the addresses of all the master nodes of the cluster. Additionally, whenever a cluster mounts or unmounts a UFS, the mounted path will be sent to the CrossClusterMaster. Each time any of these values are updated, the CrossCluster master will inform all Alluxio clusters of the new values.
Using this information, each Alluxio cluster will compute the intersection of its local UFS mount paths with all UFS mounts at external clusters. For each intersecting path, the cluster’s master will then create a subscription with the path as the topic to the external cluster’s master using a GRPC connection. In the example from Table 1, C1 will create a subscription with topic s3://bucket/folder to C2, and a subscription with topic s3://bucket/other to C3. Additionally, C2 will create a subscription with topic s3://bucket/folder to C1, and C3 will create a subscription with topic s3://bucket/other to C1. Now whenever a cluster modifies a path, for example by creating a file, it will publish the path of the modification to any subscriber whose topic is a prefix of the path. For example if C1 creates a file /mnt/other/file, it will publish s3://bucket/other/file to C3.
On each Alluxio master a thread is run to actively maintain subscriptions to other clusters in case of mounts or clusters being added or removed, or connection failures.
Whenever a subscriber receives a path, it will update the invalidation time metadata to the current time so that the next time a client accesses this path, a synchronization with the UFS will be performed. Following our example above, the next time a client reads the path /file on cluster C3, a synchronization with the UFS will be performed on s3://bucket/other/file.
Ensuring Eventual Consistency
Now if for every published message exactly once delivery is guaranteed to all subscribers (including future subscribers), it is clear that eventual consistency will be ensured as every modification will result in a synchronization at any subscriber when the path is accessed. But how can we guarantee exactly once message delivery when connections may drop, clusters may leave and join the system, and nodes may fail? The simple answer is that we don’t. Instead, exactly once message delivery is only ensured while a subscription (using an underlying TCP connection) is active. Furthermore, when the subscription is first established the subscriber will mark the metadata for the root path (the topic) as needing synchronization. This means that, after the subscription is established, for any path that is a superstring of the topic, a synchronization will be performed the first time the path is accessed.
For example, when C1 establishes a subscription to C2 with topic s3://bucket/folder, C1 will mark s3://bucket/folder as needing synchronization. Then, for example, the first time s3://bucket/folder/file is accessed, a synchronization will be performed.
This greatly simplifies the task of dealing with faults or configuration changes in the system. If a subscription fails for any reason; network issues, master failover, configuration change, then the recovery process is the same: reestablish the subscription, and mark the corresponding path as out of sync. To mitigate the impacts of network issues a user defined parameter can be set for how many messages can be queued at the publisher as well as the possibility to block operations for a given timeout in the case of the queue being full.
Of course the expectation will be that while failures in our system will happen, they will not happen frequently, otherwise performance will be impacted. Fortunately even in the case of frequent failures, the performance degradation will be similar to that of using the time based sync. For example if a failure occurs every 5 minutes, we should expect performance similar to that of having time based sync enabled at a 5 minute interval.
Note that if the CrossClusterMaster process fails, then new cluster and mount discovery will not be available, but clusters will maintain their existing subscriptions without disruption. Furthermore the CrossClusterMaster is stateless (think of it as just a point through which clusters exchange addresses and mount paths) and, therefore, can be stopped and restarted as necessary.
Other Use Cases
Previously it was mentioned that for this feature to be useful, all updates to the UFS(s) should go through the Alluxio clusters. Of course this may not always be the case, so there are several ways to deal with this:
- A path can be marked as needing synchronization manually by the user.
- Time based synchronization can be enabled along with cross-cluster synchronization.
In the next blog, we will discuss some design decisions and certain future work.
.png)
Blog


Coupang, a Fortune 200 technology company, manages a multi-cluster GPU architecture for their AI/ML model training. This architecture introduced significant challenges, including:
- Time-consuming data preparation and data copy/movement
- Difficulty utilizing GPU resources efficiently
- High and growing storage costs
- Excessive operational overhead maintaining storage for localized data silos
To resolve these challenges, Coupang’s AI platform team implemented a distributed caching system that automatically retrieves training data from their central data lake, improves data loading performance, unifies access paths for model developers, automates data lifecycle management, and extends easily across Kubernetes environments. The new distributed caching architecture has improved model training speed, reduced storage costs, increased GPU utilization across clusters, lowered operational overhead, enabled training workload portability, and delivered 40% better I/O performance compared to parallel file systems.

Suresh Kumar Veerapathiran and Anudeep Kumar, engineering leaders at Uptycs, recently shared their experience of evolving their data platform and analytics architecture to power analytics through a generative AI interface. In their post on Medium titled Cache Me If You Can: Building a Lightning-Fast Analytics Cache at Terabyte Scale, Veerapathiran and Kumar provide detailed insights into the challenges they faced (and how they solved them) scaling their analytics solution that collects and reports on terabytes of telemetry data per day as part of Uptycs Cloud-Native Application Protection Platform (CNAPP) solutions.