When applications are only reading and writing through Alluxio, the Alluxio file system provides strong consistency. However, when clients are writing data across both Alluxio and under storage, the consistency depends on the Alluxio write type and under storage type. This article discusses what to expect in each scenario.
Cloud analytics Caching
featured use case
Is data in the public cloud slowing your compute down? With Alluxio, get in-memory data access for Spark, Presto, Hive and other analytics frameworks on AWS S3, Google Cloud, or Microsoft Azure.
are analytics workloads in the cloud getting slow and expensive?
Running compute on top of S3/GCS/Azure comes with its own set of data engineering problems to solve.

Performance is variable and consistent query SLAs are hard to achieve

Metadata operations like list and rename are expensive, so workloads run longer

Egress costs, particularly cross-region, can add up, making the solution expensive

Eventual consistency on writes makes it hard to predict query results
alluxio accelerates analytic workloads in the cloud and saves costs
Co-locate your data with your compute for in-memory data access so you can cache data in the cloud in the same instance as your compute. Run in the cloud of your choosing or use AWS EMR with Alluxio.

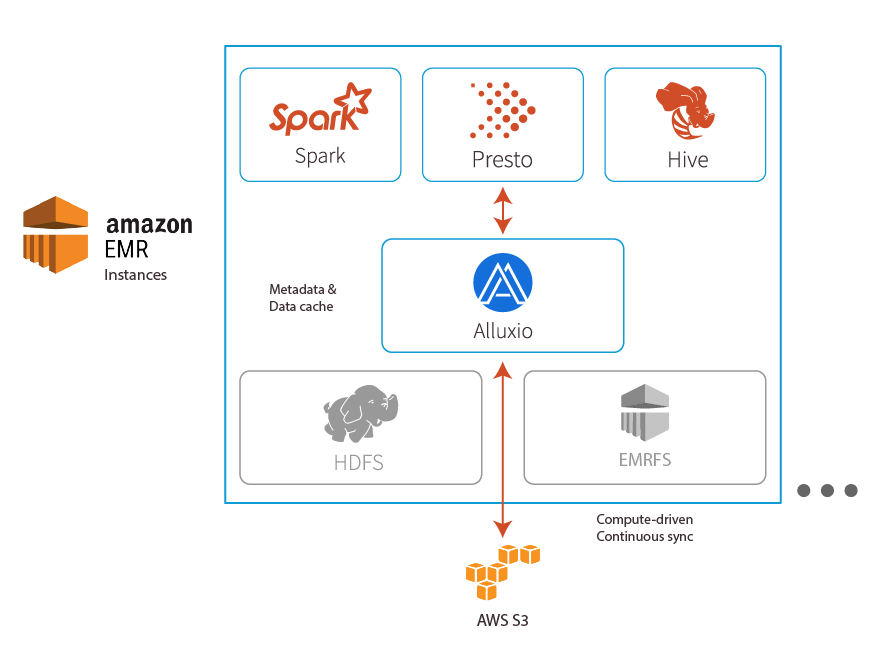
Reading S3/GCS/Azure data into Spark, Presto, Hive, or any other compute framework and enabling data sharing is automated and transparent with Alluxio, which serves data to compute to improve the end-to-end model development efficiency. Alluxio can be deployed colocated with your compute cluster, exposing the data through Alluxio POSIX or HDFS compatible interfaces and backed by a mounted remote storage like S3.
Want help getting your analytics workloads faster and less expensive? Schedule a meeting with an Alluxio solutions engineer.
alluxio on aws

Alluxio on S3
Alluxio supports access to different storage systems through its unified namespace. Configure S3 as Alluxio’s under storage system in six steps.

Alluxio on EMR + S3
Run clusters on-demand for compute workloads with AWS EMR. Alluxio on EMR and S3 provides more functionality than EMRFS.
alluxio on google cloud

Alluxio on GCS
Alluxio supports access to different storage systems through its unified namespace. Configure GCS as Alluxio’s under storage system in four steps.
Alluxio on Dataproc + GCS
Deploy Alluxio on GCP with the Dataproc initialization action. To run an Alluxio cluster on Dataproc, you’ll need to sign up for a Google Cloud account first.
alluxio on azure

Alluxio on Azure Blob Store
Alluxio supports access to different storage systems through its unified namespace. Configure Azure Blob Store as Alluxio’s under storage system in three steps.

alluxio + presto and azure
Run Presto to query Alluxio as a distributed cache layer with Azure Blob Store. Alluxio will allow Presto tp access data from Azure and transparently cache the data frequently accessed.
LATEST RELATED POSTS
This blog explores an innovative platform with Presto as the computing engine and Alluxio as a data orchestration layer between Presto and S3 storage, to support online services with instantaneous response within the gaming industry. The preliminary results show that Presto with Alluxio outperforms S3 significantly in all cases.Alluxio with metadata caching shows up to 5.9x performance gain when handling large numbers of small files.
This article described how engineers at datasapiens brought down S3 API costs by 200x by implementing Alluxio as a data orchestration layer between S3 and Presto.
Bay Area Meetup which include presentations on the architecture of Presto, its separation of compute and storage, cloud-readiness, recent advancements in the project such … Continued
The AWS EMR service has made it easy for enterprises to bring up a full-featured analytical stack in the cloud that elastically scales based … Continued
In this article, Thai Bui from Bazaarvoice describes how Bazaarvoice leverages Alluxio to build a tiered storage architecture with AWS S3 to maximize performance and minimize operating costs on running Big Data analytics on AWS EC2.