Introduction
The exponential growth of the raw computational power, communication bandwidth, and storage capacity results in continuous innovation in how data is processed and stored. To address the evolving nature of the compute and storage landscape, we are continuously advancing Alluxio, a state-of-the-art memory-centric virtual distributed storage system.
This blog post highlights unified namespace, an abstraction that makes it possible to access multiple independent storage systems through the same namespace and interface. With Alluxio’s unified namespace, applications simply communicate with Alluxio and Alluxio manages the communication with the different underlying storage systems on applications’ behalf.
In the remainder of this blog post, we first discuss the importance of decoupling computation from data, providing motivation for Alluxio’s unified namespace. We then describe the feature itself and present two examples that illustrate how unified namespace makes it possible for applications to transparently work with different storage systems.
Benefits
Leveraging Alluxio’s unified namespace provides the following benefits:
- Future-proofing your applications: applications can communicate with different storage systems, both existing and new, using the same namespace and interface; seamless integration between applications and new storage systems enables faster innovation
- Enabling new workloads: integrating an application or a storage system with Alluxio is a one-time effort which enables the application to access many different types of storage systems and the storage system to be accessed by many different types of applications
Motivation
There are two common approaches to large-scale data processing. Computation and data can be either co-located in the same cluster or dedicated compute and storage clusters are used. On one hand, managing compute and storage resources separately enables scaling infrastructure resources in a cost-effective manner. On the other hand, co-locating computation and data avoids expensive data transfers, which benefits I/O intensive workloads such as data processing pipelines.
In a previous blog post, we talked about how to use Alluxio with Spark and demonstrated the performance benefits Alluxio provides when Spark communicates with remote storage such as S3. Alluxio realizes these performance benefits through its state-of-the-art memory-centric storage layer, possibly improving application performance by orders of magnitude.
However, decoupling computation from data at the physical level does not address the logical dependencies between computation and data. In particular, because of the differences between different types of applications and storage systems, it can be challenging to allow applications to access data across different types of storage systems, both existing and new.
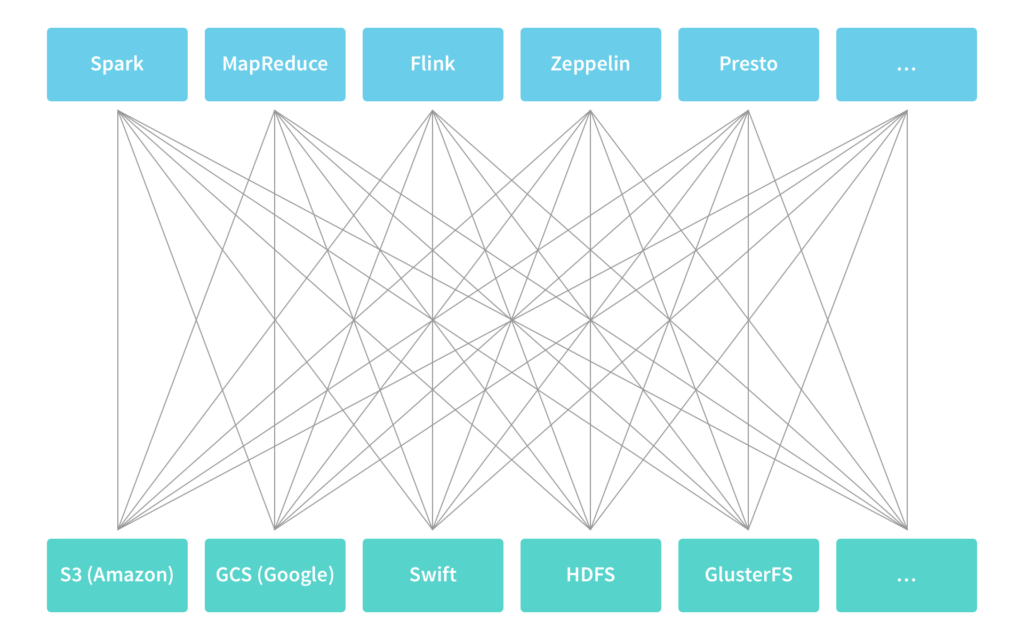
Common solutions to this problem are sub-optimal. Applications either need to be: 1) integrated with different types of storage systems, which does not scale as the number of applications and storage systems grows; or 2) data needs to be first extracted to a temporary location that applications know how to access, which leads to data duplication and increases time to insight.
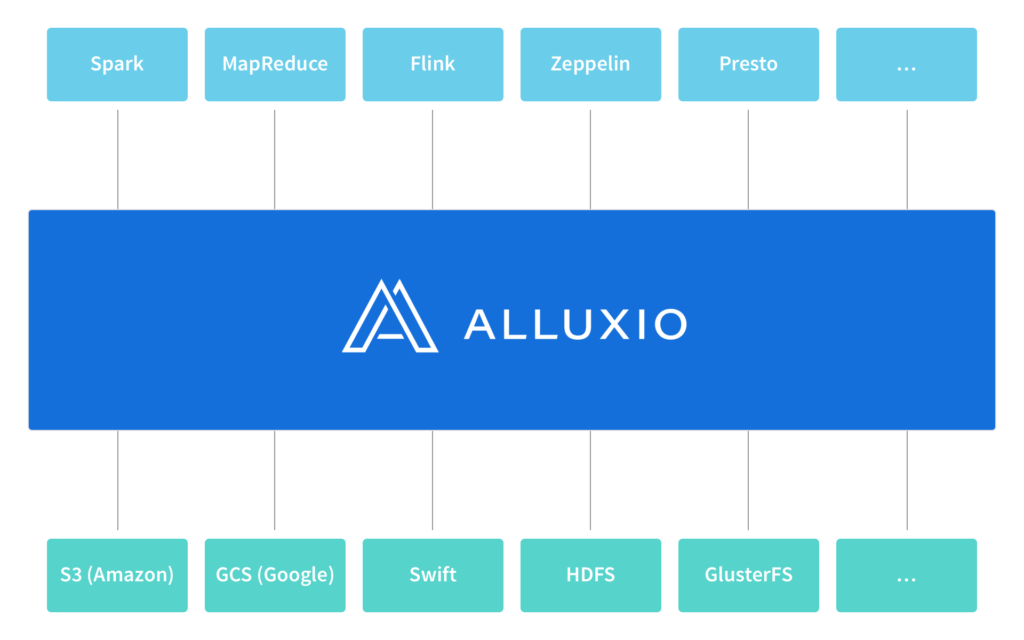
In this blog post, we talk about how Alluxio addresses this challenge by providing a layer of indirection called unified namespace that logically decouples the computation from data. With Alluxio’s unified namespace, applications simply communicate with Alluxio while Alluxio handles the communication with the different underlying storage systems on applications’ behalf.
Unified Namespace
Storing, accessing, and managing data at scale is an increasingly common challenge, rooted in the fact that data typically spans multiple storage systems with different interfaces and independent namespaces. To address this challenge, Alluxio provides a unified namespace, a feature that greatly simplifies data management at scale by making it possible to interact with different storage systems using the same namespace and interface.
Similar to how a local workstation allows applications to use the same interface to access different devices (such hard disks or USB drives), Alluxio allows distributed applications to use the same interface to access different types of distributed storage systems (such as S3 or HDFS).

However, Alluxio’s unified namespace is not just an interface; it is also a set of adapters that make it possible to use the same interface to access many popular storage systems. In addition, accessing data through Alluxio leverages Alluxio’s memory-centric data management layer, enabling significant performance benefits.
Similar to how a personal computer maps different local paths to different devices, Alluxio maps different Alluxio paths to different underlying storage systems. The mapping is dynamic and Alluxio provides an API for creating and removing these mappings and transparently surfacing objects from the underlying storage system in Alluxio.
Examples
In this section, we walk through a couple examples to illustrate how Alluxio’s unified namespace works in the real world.
Working With Multiple Storage Systems
In this example, we illustrate how Alluxio’s unified namespace enables applications to use one API to interact with multiple different storage systems at the same time.
For the sake of this example, we assume that the application is written in Java and is sharing data between HDFS and S3.
The following logic illustrates how Alluxio can be used to read data from HDFS, process it, and then write the results to S3:
package io;
import alluxio.client.file.FileInStream;
import alluxio.client.file.FileOutStream;
import alluxio.client.file.FileSystem;
// mount HDFS and S3 to Alluxio
FileSystem fileSystem = FileSystem.Factory.get();
fileSystem.mount("/mnt/hdfs", "hdfs://...");
fileSystem.mount("/mnt/s3", "s3n://...");
// read data from HDFS
AlluxioURI inputUri = new AlluxioURI("/mnt/hdfs/input.data");
FileInStream is = fileSystem.openFile(inputUri);
... // read data
is.close();
... // perform computation
// write data to S3
AlluxioURI outputUri = new AlluxioURI("/mnt/s3/output.data");
FileOutStream os = fileSystem.createFile(outputUri);
... // write data
os.close();
A special case of the above example is the following logic, which can be used to copy data from one storage system to another.
package io;
import alluxio.client.file.FileInStream;
import alluxio.client.file.FileOutStream;
import alluxio.client.file.FileSystem;
import org.apache.commons.io.IOUtils;
// mount HDFS and S3 to Alluxio
FileSystem fileSystem = FileSystem.Factory.get();
fileSystem.mount("/mnt/hdfs", "hdfs://...")
fileSystem.mount("/mnt/s3", "s3n://...")
// copy data from HDFS to S3
AlluxioURI inputUri = new AlluxioURI("/mnt/hdfs/input.data");
AlluxioURI outputUri = new AlluxioURI("/mnt/s3/output.data");
FileInStream is = fileSystem.openFile(inputUri);
FileOutStream os = fileSystem.createFile(outputUri);
IOUtils.copy(is, os);
is.close();
os.close();
A code-complete version of this example can be found here.
Porting an Application to a Different Storage System
In this example, we illustrate how using unified namespace greatly reduces the effort needed to port an application when the data the application accesses moves to a different storage system.
For the sake of this example, let us again assume that the application is written in Java and that the data it accesses moves from HDFS to S3.
Without Alluxio, the original application would use the HDFS API for read and writing the data:
package io;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
// reading data
Path path = new Path("hdfs://<host>:<port>/<path>");
FileSystem fileSystem = path.getFileSystem(new Configuration());
FSDataInputStream is = fileSystem.open(path);
... // read data
is.close();
... // perform computation
// writing data
Path path = new Path("hdfs://<host>:<port>/<path>");
FileSystem fileSystem = path.getFileSystem(new Configuration());
FSDataOutputStream os = fileSystem.create(path);
... // write data
os.close();
When the data moves to S3, the application needs to use a different API, such as jets3t, to read and write the data:
package io;
import org.jets3t.service.impl.rest.httpclient.RestS3Service;
import org.jets3t.service.model.S3Object;
import org.jets3t.service.security.AWSCredentials;
import java.io.InputStream;
// reading data
RestS3Service client = new RestS3Service();
S3object object = client.getObject(<bucket>, <key>);
InputStream is = object.getDataInputStream();
... // read data
is.close();
... // perform computation
// writing data
OutputStream os = new FileOutputStream();
... // write data
os.close();
InputStream is = new FileInputStream(<tmpFile>);
RestS3Service client = new RestS3Service(<credentials>);
S3Object object = new S3Object(<key>);
object.setDataInputStream(is);
client.putObject(<bucket>, object);
is.close();
In addition to the difference in the above logic, the logic for reading and writing data (not shown) needs to change as well to reflect the differences between HDFS API and S3 API.
In contrast to the above changes, with Alluxio, the application can use the following logic to access data from both HDFS and S3:
package io;
import alluxio.client.file.FileInStream;
import alluxio.client.file.FileOutStream;
import alluxio.client.file.FileSystem;
// mount a storage system (HDFS or S3) to Alluxio
FileSystem fileSystem = FileSystem.Factory.get();
fileSystem.mount("/mnt/data", <url>;)
// reading data
AlluxioURI uri = new AlluxioURI("/mnt/data/...");
FileInStream is = fileSystem.openFile(uri);
... // read data
is.close();
... // perform computation
// writing data
AlluxioURI uri = new AlluxioURI("/mnt/data/...");
FileOutStream os = fileSystem.createFile(uri);
... // write data
os.close();
In particular, when data moves from HDFS to S3, the only part of the application that needs to be updated is the <url> to mount, which can be read from configuration or a command-line argument to avoid any application changes at all.
Conclusion
Alluxio’s unified namespace provides a layer of indirection that logically decouples the computation from data. Applications simply communicate with Alluxio while Alluxio handles the communication with the different underlying storage systems on applications’ behalf.
Alluxio supports many popular storage systems including S3, GCS, Swift, HDFS, OSS, GlusterFS, and NFS. Adding support for new storage systems is relatively straightforward — the existing adapters are less than a thousand lines of code each.
Please do not hesitate to contact us if you would like to propose or lead an integration. We welcome more integrations and look forward to hearing from you!