An introduction to the Apache Spark architecture
What is the Apache Spark architecture?
Apache Spark includes Spark Core and four libraries: Spark SQL, MLlib, GraphX, and Spark Streaming. Individual applications will typically require Spark Core and at least one of these libraries. Spark’s flexibility and power become most apparent in applications that require the combination of two or more of these libraries on top of Spark Core, which provides the management functions such as task scheduling
- Spark SQL: This is how Spark works with structured data to support workloads that combine SQL database queries with more complicated, algorithm-based analytics. Spark SQL supports Hive and JDBC/ODBC connections so you can connect to databases, data warehouses and BI tools.
- MLlib: Scalable machine learning library which implements a set of commonly used machine learning and statistical algorithms. These include correlations and hypothesis testing, classification and regression, clustering, and principal component analysis.
- GraphX: Supports analysis of and computation over graphs of data, and supports a version of graph processing’s Pregel API. GraphX includes a number of widely understood graph algorithms, including PageRank.
- Spark Streaming: For processing of streaming data, Spark Streaming can integrate with sources of data streams like Kafka, Flume, etc. Applications written for streaming data can be repurposed to analyze batches of historical data with little modification with it.
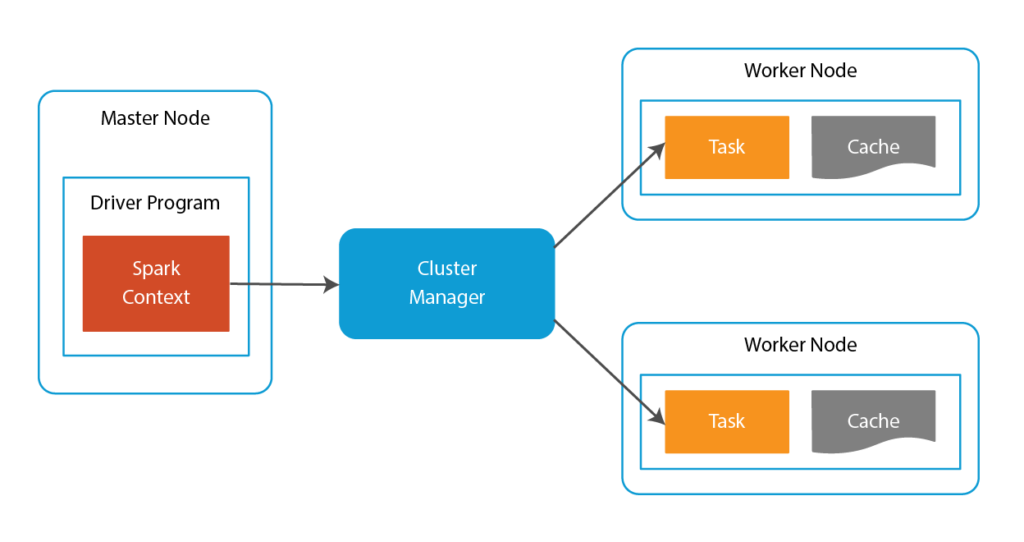
The internals of Spark include:
- Spark Context: This is located in the Master Node’s driver program. Spark Context is a gateway to all the Spark functionalities. It is similar to your database connection. Any command you execute in your database goes through the database connection. Likewise, anything you do on Spark goes through Spark context.
- Cluster Manager: This manages various jobs. The driver program and Spark Context takes care of the job execution within the cluster. A job is split into multiple tasks which are distributed over the worker node. Anytime an RDD is created in Spark context, it can be distributed across various nodes and can be cached there.
- Executors/Workers: These are slave nodes that execute the tasks. These tasks are then executed on the partitioned RDDs in the worker node and results are returned back to the Spark Context.
RDDs are the building blocks of any Spark application.
- Resilient: Fault tolerant and is capable of rebuilding data on failure
- Distributed: Distributed data among the multiple nodes in a cluster
- Dataset: Collection of partitioned data with values
The data in RDDs is split into chunks based on a key. RDDs are highly resilient – they recover quickly because the same data is replicated across multiple executor nodes. So even if one executor node fails, another will still process the data. This allows you to perform your functional calculations against your dataset very quickly by harnessing the power of multiple nodes.
For storage, you can use Apache Spark with the following:
- Google Cloud
- Amazon S3
- Apache Cassandra
- Apache Hadoop (HDFS)
- Apache HBase
- Apache Hive
- Alluxio (caching)
If you want to learn more about accelerating your Spark workloads, learn more about how to deploy Alluxio + Spark.