An introduction to the PRESTO architecture
What is the Presto architecture?
Presto is an open source distributed system that can run on multiple machines. Its distributed SQL query engine was built for fast analytic queries. A typical Presto deployment will include one Presto Coordinator and any number of Presto Workers.
Presto Coordinator: Used to submit queries and manages parsing, planning, and scheduling query execution across Presto Workers
Presto Worker: Processes the queries, adding more workers gives you faster query processing
At a high level, the Presto architecture looks something like this:
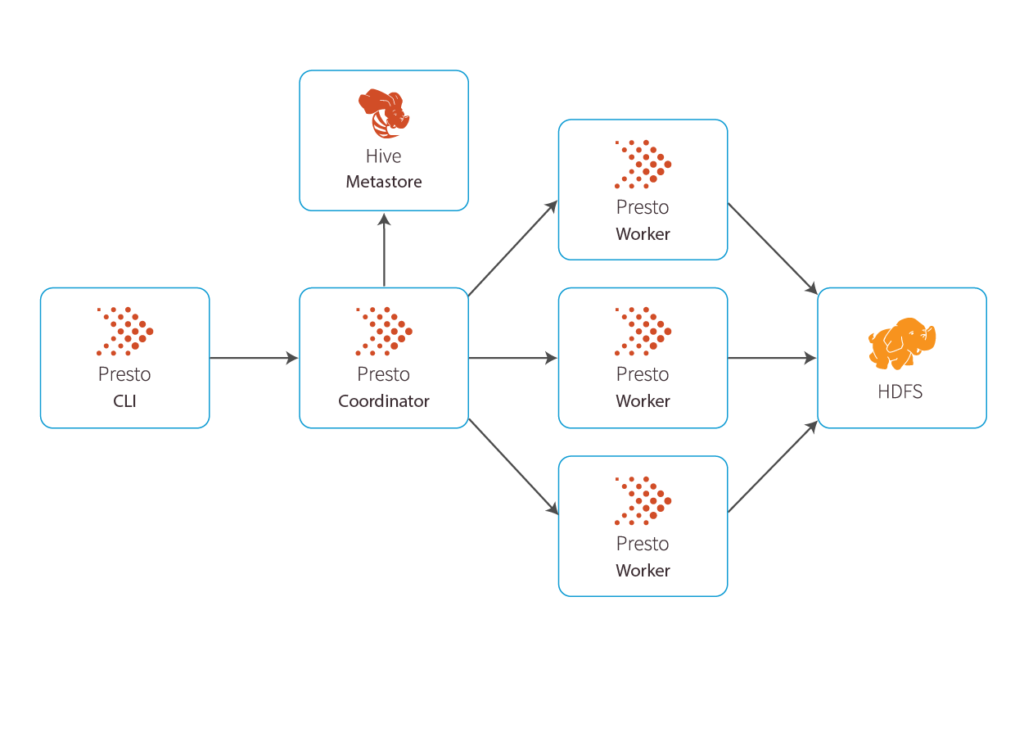
Presto components
Diving a little deeper into the Presto components, let’s start with the server types (Coordinator and Worker).
Coordinator: The Presto Coordinator is truly the brain of any Presto installation and every installation requires it. It parses statements, plans queries, and manages Presto worker nodes, and it tracks all the Workers’ activity to coordinate queries. It gets results from the Workers and returns final results back to the client. Coordinators connect with workers and clients via REST.
Worker: The Presto Worker executes tasks and processes data. These nodes share data amongst each other and get data from the Coordinator. When you first start up a Presto Worker, it will be identified by the Coordinator and make itself available for task execution.
When it comes to managing the data itself, Presto has several important components that enable this.
Catalog: Presto Catalogs contain the information about where data is located – they contain schemas and the data source. When users run a SQL statement in Presto, it means they’re running it against one or more catalogs. For example, you may build a Hive catalog to access Hive information from the Hive data source. Catalogs are defined in properties files stored in the Presto configuration directory.
Tables and schemas: If you’re familiar with relational databases, it’s the same concept. A table is a set of unordered rows of data that can be organized into named columns/types. Schema is what you use to organize your tables. Catalogs and schemas are how users define what will be queried.
Connector: Connectors are used to integrate Presto with external data sources like object stores, relational databases, or Hive. You can integrate with these sources using standard APIs via Presto’s SPI implementation. Presto has over 20 built-in connectors for various data sources. Every Presto Catalog is associated with a specific connector, and more than one catalog can use the same connector to access different instances/clusters of the same data source.
Last, when it comes to running Presto queries there are some specific components to know.
Statements and Queries: Presto executes ANSI-compatible SQL statements. When a statement is executed, Presto creates a query along with a query plan that is then distributed across a series of Presto workers. When Presto parses a statement, it converts it into a query and creates a distributed query plan among Presto workers. A statement is simply passing along the instructions while the query is actually executing it.
Stage: To execute a query, Presto breaks it up into stages. Depending on how much data it needs to aggregate, there may be several stages that implement different sections of the query. Stages are typically done in a hierarchical manner (it may look like a tree). Every query has a “roots” stage which aggregates all the data from other stages. Keep in mind the stages themselves don’t run on Presto workers, they may run on the database underneath (this is called push-down).
Task: Stages (from above) are implemented as a series of tasks that may be distributed over a network of Presto workers. Tasks have inputs and outputs and are executed in parallel with a series of drivers.
Split: Splits are sections of larger data sets and how tasks operate. When Presto schedules a query, the Coordinator keeps track of which machines are running tasks and what splits are being processed by tasks.
Drivers and Operators: Tasks contain one or more parallel drivers and they are operators in memory. An operator consumes, transforms and produces data.
Exchange: Exchanges transfer data between Presto nodes for different stages of a query. Tasks produce data into an output buffer and consume data from other tasks using an exchange client.
Deployments, Configurations & Installations
In practice, you might deploy Presto in the cloud or on-prem. Presto sits between your BI tool and your storage. Here’s an example taken from Starburst, the company behind Presto:
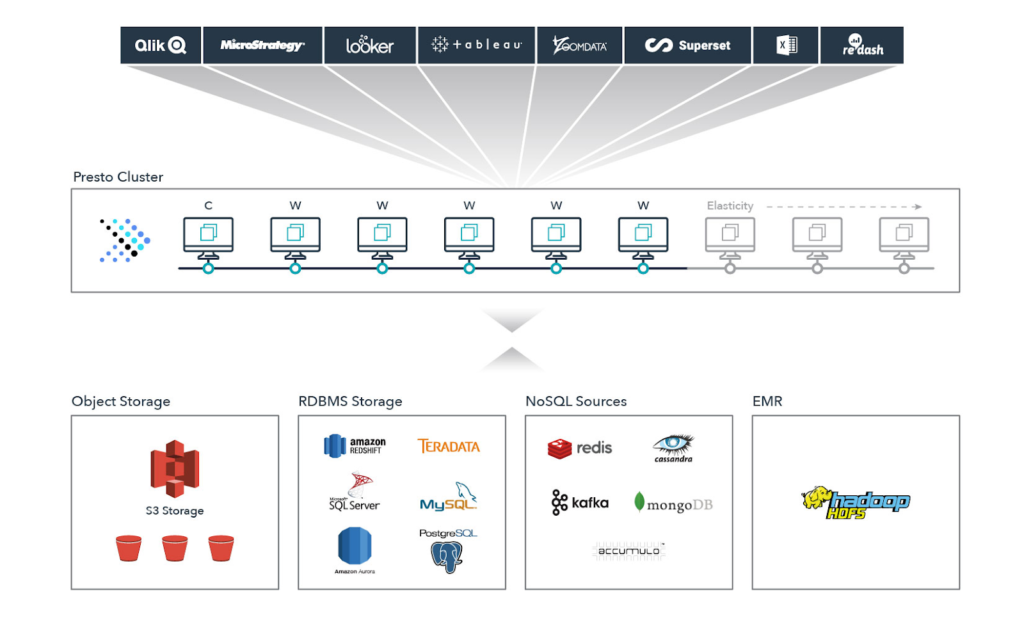
Companies use Alluxio with Presto to speed up Presto performance.
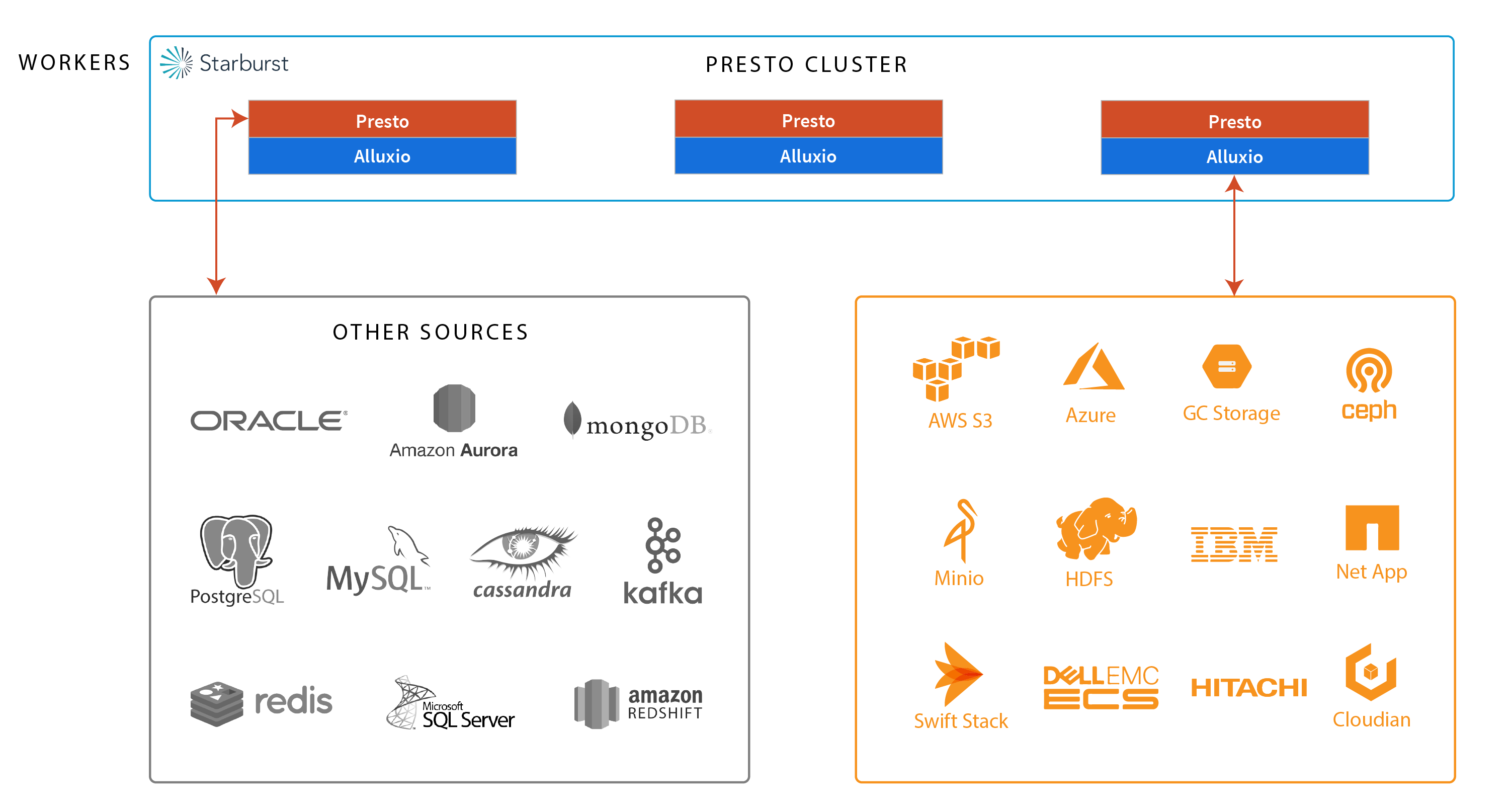
Alluxio provides a multi-tiered layer for Presto caching, enabling consistent high performance with jobs that run up to 10x faster, makes the important data local to Presto, so there are no copies to manage (and lower costs), and connects to a variety of storage systems and clouds so Presto can query data stored anywhere.
You can do a quick 10min tutorial to see how Alluxio can speed up Presto queries.