Get Faster Analytics Across Data Centers and Clouds
Got lots of data? Great.
Generate insights faster and gain the freedom to move to better storage solutions without making any changes to your analytics apps.
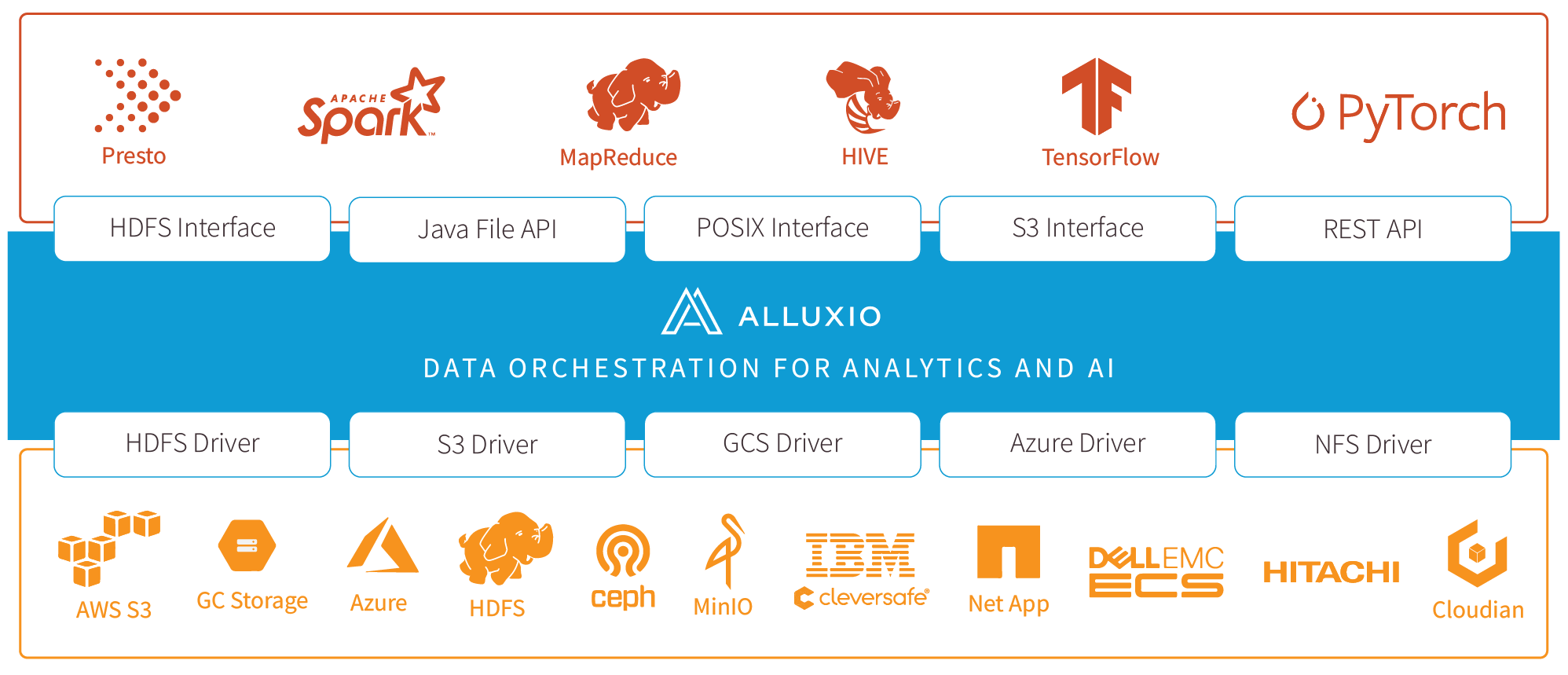
Alluxio is the leading open source platform for unifying data access and accelerating large-scale analytics and AI/ML workloads. It provides a unified namespace plus advanced caching to simplify and accelerate data access across distributed, hybrid cloud, and multi-cloud environments. Alluxio provides up to a 10x performance boost for Presto and Spark-based analytics workloads. Together with the latest-generation Intel® Xeon® Scalable Processors and Intel® Optane™ persistent memory, you can take analytics performance to new heights.
Accelerate Presto and Spark Workloads with Alluxio
Alluxio enables separation of compute from underlying storage while advanced caching and data tiering, accelerates large-scale analytics workloads in distributed on-prem, hybrid cloud, and multi-cloud environments.
Bring Data Closer to COMPUTE

Data locality
Bring your data closer to compute.
Make your data local to compute workloads for Spark caching, Presto caching, Hive caching and more.

Data Accessibility
Make your data accessible.
No matter if it sits on-prem or in the cloud, HDFS or S3, make your files and objects accessible in many different ways.

Data On-Demand
Make your data as elastic as compute.
Effortlessly orchestrate your data for compute in any cloud, even if data is spread across multiple clouds.
PROVEN AT SCALE
Alluxio is in use by eight of the top ten largest Internet companies, including Facebook, Uber, TikTok, Walmart, Tencent, Comcast, and more. Alluxio’s free Community Edition and Alluxio Enterprise Edition are also used in production at thousands of the most data-intensive companies in finance, retail, communications, pharmaceuticals, and more.


Key Technical Features
Compute-focused

Support for hyperscale workloads
Supports a billion files and thousands of workers and clients, all with high-availability.
Flexible APIs
Integrates your compute frameworks like Spark, Presto, TensorFlow, Hive and more out-of-the-box using the HDFS, S3, Java, RESTful, or POSIX-based APIs.
Intelligent data caching and tiering
Automatically utilizes near-compute storage media for optimal data placement based on data topology and workload.
Storage-focused

Built-in data policies
Provides highly customizable data policies for persistence, cross storage data migration, and distributed load.
Plug and play under stores
Integrates your under store systems like HDFS, S3, Azure Blob Store, Google Cloud Store and more through a range of interfaces.
Transparent unified namespace for file system and object stores
Mounts multiple storage systems into a single consolidated namespace for both read and write workloads.
Enterprise-ready

Security
Provides data protection on the wire and in the cloud with built-in auditing, role-based access control, LDAP, active directory, and encrypted communications.
Monitoring and management
Provides a user-friendly web interface and command line tools, allowing users to monitor and manage their cluster.
Enterprise high availability with tiered locality
Includes adaptive replication across regions and zones to maximize performance and availability.
Alluxio + Intel: Better Together
Running data-intensive analytics workloads with Alluxio helps them run faster. And with Alluxio running on 2nd Gen Intel® Xeon® Scalable processors and Intel® Optane™ persistent memory, data teams can leverage an advanced in-memory acceleration layer, significantly boosting storage capacity and performance for faster data access and processing.


Today’s analytical workloads demand fast access to expansive amounts of data. See benchmarks illustrating how Alluxio’s data orchestration platform, running on Intel Optane persistent memory, accelerates access to this data and uncovers its valuable business insights faster.
GET MORE FACTS


Accelerating analytics workloads with Alluxio data orchestration and Intel® Optane™ persistent memory
Ultra Fast Deep Learning in Hybrid Cloud using Intel Analytics Zoo & Alluxio
Accelerating Queries on Cloud Data Lakes
Enabling Hybrid Cloud Analytics and AI with Data Orchestration
Intel: How to Use Alluxio to Accelerate Big Data Analytics on the Cloud and New Opportunities with Persistent Memory
Ultra Fast Deep Learning in Hybrid Cloud Using Intel Analytics Zoo & Alluxio
