Alluxio 2.6 significantly improves the performance of data-intensive AI/ML workloads across any storage, and also improves the general maintainability and visibility of Alluxio clusters, especially for large-scale deployments. We have taken the feedback and contributions from the community and introduced features which simplify deployment, introduce new data management capabilities, optimize performance, and provide enhanced visibility into system behavior.
whY Data orchestration
A data orchestration platform brings your data closer to compute across clusters, regions, clouds, and countries

Alluxio founder, Haoyuan Li, offers an overview of a data orchestration layer for big data analytics and AI in the cloud.
Data challenges in today’s disaggregated world
Today we see more enterprise architectures shifting to hybrid and multi-cloud environments. And while this shift allows for more flexibility and agility, it also means having to separate compute from storage, creating new challenges in how data needs to be managed and orchestrated across frameworks, clouds, and storage systems.

low performance
Data is not local to compute, leading to degraded workload performance.

POOR accessibility
The same data needs to be accessible to different, popular analytical & ML frameworks.

RIGID
scaling
Running computation where data persists makes scaling extremely limited & expensive.

No self service data
To make data accessible to the users, complex ETL jobs are needed that copy data across different silos.

high Cost of management
Cloud storage egress costs continue to rise due to multiple data storage layers in the cloud.

unreliable s3 performance
Today’s object storage capabilities are not ready for interactive big data workloads.

complex Data
ManagemeNT
High availability, storage system data management and disaster recovery is complex.

limiteD DATA security
No unified way to secure data across different clouds and storage systems.
The need for a new DATA ORCHESTRATION platform
To address these data challenges, enterprises are adopting a new platform: the data orchestration platform. A unified data orchestration platform simplifies your data’s cloud journey.
A data orchestration platform fundamentally enables separation of storage and compute. It brings speed and agility to big data and AI workloads and reduces costs by eliminating data duplication and enables users to move to newer storage solutions like object stores.
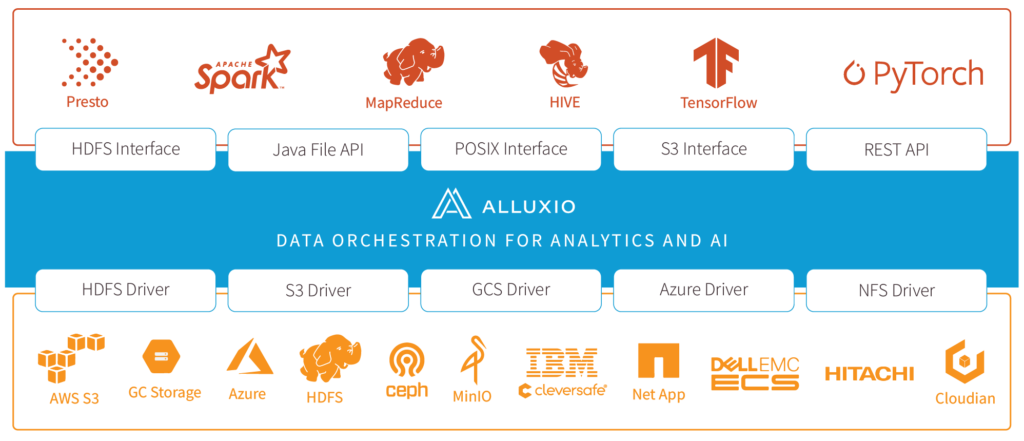
Alluxio – BIG Data orchestration fRAMEWORK for The cloud
Alluxio is a compute agnostic, storage agnostic and cloud agnostic solution for big data and machine learning applications.

Data locality
Data is local to compute, giving you memory-speed access for your big data and AI/ML workloads

Data accessibility
Data is accessible through one unified namespace, regardless of where it resides

Data ON-DEMAND
Data is as elastic as compute so you can abstract and independently scale compute and storage
Resources
Alluxio’s capabilities as a Data Orchestration framework have encouraged users to onboard more of their data-driven applications to an Alluxio powered data access layer. … Continued
Alluxio is expanding the data integration capabilities of its multi-cloud/hybrid cloud data management platform, boosting the system’s data pipelines for business analytics and machine learning applications.
Data processing is increasingly making use of NVIDIA computing for massive parallelism. Advancements in accelerated compute mean that access to storage must also be quicker, whether in analytics, artificial intelligence (AI), or machine learning (ML) pipelines.
In this talk, HY discussed the key challenges and trends impacting data engineering, and explores the concept of Data Orchestration. … Continued
Large-scale analytics and AI/ML applications require efficient data access, with data increasingly distributed across multiple data stores in private data centers and clouds. Data … Continued