DATA ORCHESTRATION SUMMIT

DECEMBER 8-9, 2020 | VIRTUAL
The virtual event for all building cloud-native data and AI platforms.
This is an open source community conference focused on the key data engineering challenges and solutions around building cloud-native data and AI platforms using latest technologies such as Alluxio, Apache Spark, Apache Airflow, Presto, Tensorflow, and Kubernetes. This Summit brings together data engineers, architects, cloud engineers, data scientists, and industry thought leaders who are solving data problems at the intersection of cloud, AI/ML, and data.
presentations anchor
PRESENTATIONS
DAY ONE | December 8, 2020
KEYNOTES
Presentation Slides >
The Pandemic Changes Everything, The need for speed and resiliency
Parviz Peiravi, Intel
CLOUD NATIVE JOURNEYS – MODERNIZING DATA PLATFORMS

Presentation Slides >
Building a high-performance platform on AWS to support real-time gaming services using Presto, Alluxio, and S3
Serena Wang, Electronic Arts

Presentation Slides >
Reducing large S3 API costs using Alluxio at Datasapiens
Juraj Pohanka & Koen Michiels, Datasapiens
Presentation Slides >
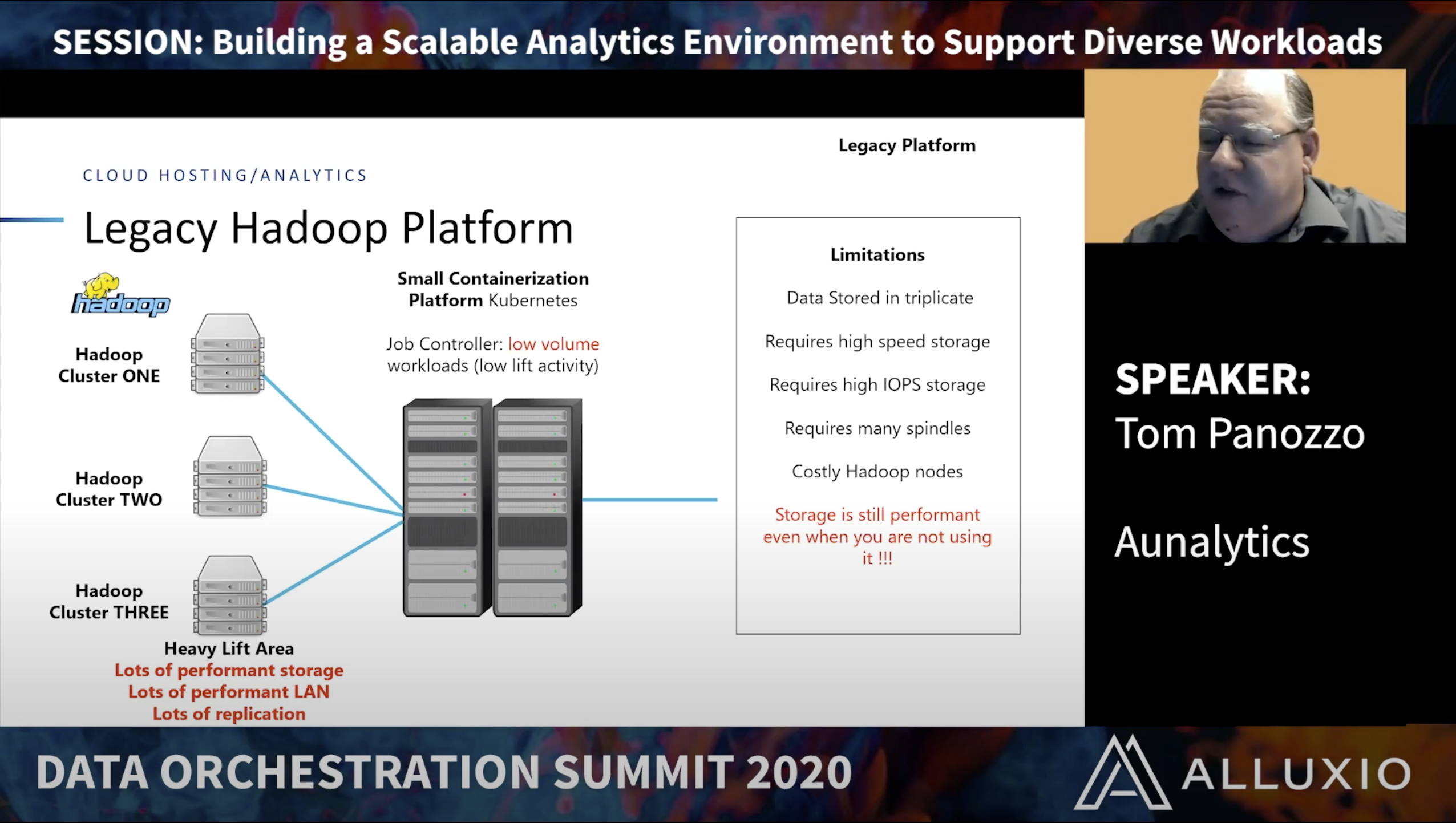
Building a Scalable Analytics Environment to Support Diverse Workloads
Tom Panozzo, Aunalytics

Presentation Slides >
How to Teach Your Data Scientist to Leverage an Analytics Cluster with Presto, Spark, and Alluxio
Katarzyna Orzechowska & Mariusz Derela, ING Tech
HIGH PERFORMANCE SQL ANALYTICS
Presentation Slides >
Optimizing Latency-sensitive queries for Presto at Facebook: A Collaboration between Presto & Alluxio
Ke Wang, Facebook & Bin Fan, alluxio
Presentation Slides >
Exploring Alluxio for Daily Tasks at Robinhood
Jiawei Zhang, Yichuan Huang, Grace Lu, & Wenlong Xiong, Robinhood

Presentation Slides >
Presto: Fast SQL-on-anything across data lakes, DBMS, and NoSQL Data stores
Kamil Bajda-Pawlikowski, Starburst Data

Presentation Slides >
High Performance Data Lake with Apache Hudi and Alluxio at T3Go
Trevor Zhang, T3Go

Presentation Slides >
Speeding Up Spark Performance using Alluxio at China Unicom
Ce Zhang, China Unicom
DAY TWO | December 9, 2020
KEYNOTES
Presentation Slides >
Modernizing Global Shared Data Analytics Platform and our Alluxio Journey
Sandipan Chakraborty, Rakuten
Hybrid Cloud Analytics & AI

Presentation Slides >
Securely Enhancing Data Access in Hybrid Cloud with Alluxio
Mike Fagan & Prashant Khanolkar, Comcast

Presentation Slides >
Bursting on-premise analytic workloads to Amazon EMR using Alluxio
Roy Hasson, AWS
Presentation Slides >
Hybrid Data Lake on Google Cloud with Alluxio and Dataproc
Roderick Yao, Google Cloud

Presentation Slides >
Ultra Fast Deep Learning in Hybrid Cloud using Intel Analytics Zoo & Alluxio
Jennie Wang & Tsai Louie, Intel
Orchestrating Data for Machine Learning
Presentation Slides >
Deep Learning in the Cloud at Scale: A Data Orchestration Story
Mickey Zhang, Microsoft

Presentation Slides >
Speeding Up Atlas Deep Learning Platform with Alluxio + Fluid
Yuandong Xie, Unisound

Presentation Slides >
The Hidden Engineering Behind Machine Learning Products at Helixa
Gianmario Spacagna, Helixa
High Performance SQL Analytics

Presentation Slides >
Achieving Massive Concurrency and Sub-second query latency on Cloud warehouses and data lakes with kyligence cloud
George Demarest, Kyligence
Presentation Slides >
Accelerating Data Computation on Ceph Objects using Alluxio
Leonardo Militano, Zurich University
Presentation Slides >
Unified Data Access with Gimel
Deepak Chandramouli, Anisha Nainani, & Dr. Vladimir Bacvanski, Paypal
Presentation Slides >
How to Build a new under filesystem in Alluxio: Apache Ozone as an example
Baolong Mao, Tencent

Presentation Slides >
The practice of Presto & Alluxio in E-commerce big data platform
Wenjun Tao, JD.com
Speakers Anchor
SPEAKERS

ion Stoica
RiseLab
Professor, EECS Dept. at UC Berkeley

Haoyuan Li
Alluxio
Founder, CEO

Ke Wang
Software engineer

Mike Fagan
Comcast
Distinguished Architect

Sandipan Chakraborty
Rakuten
Director of Engineering

Katarzyna Orzechowska
ING
Data Scientist

Serena Wang
Electronic Arts
Software Engineer

Mickey Zhang
Microsoft
Software Engineer

Jiawei Zhang
Robinhood
Data Infrastructure Engineer

Roderick Yao
Google Cloud
Strategic Cloud Engineer

parviz Peiravi
Intel
Global CTO/Principle Engineer

Roy Hasson
AWS
Sr. Manager, Analytics and Datalakes

Calvin Jia
Alluxio
Founding Engineer, Product

Anisha Nainani
PayPal
Sr. Software engineer

Yang Che
Alibaba
Staff Engineer

Kamil Bajda-Pawlikowski
Starburst
Co-founder & CTO

Jennie wang
Intel
Software Engineer

Deepak Chandramouli
PayPal
Engineering Lead

Baolong Mao
Tencent
Sr. System Engineer

Louie Tsai
Intel
Software engineer

Vladimir Bacvanski
PayPal
Principal Architect

Juraj Pohanka
Datasapiens
CTO

Dmytro Dermanskyi
WalkMe
Data Engineering Lead

George Demarest
Kyligence
Head of Marketing

Ce Zhang
China Unicom
Big Data Engineer

Koen Michiels
Datasapiens
CEO & Co-Founder

Davy Wang
Tencent
Chief Solutions Architect

Tom Panozzo
Aunalytics
Chief Technology Officer

Bin Fan
Alluxio
Founding Engineer, VP of Open Source

Yichuan Huang
Robinhood
Data Platform engineer

Adit Madan
Alluxio
Product Manager

Rong Gu
Nanjing University
Ph.D., Associate Research Professor

Mariusz Derela
ING Bank
DevOps Engineer

Wenjun Tao
JD.com

Danny Linden
Ryte
Chapter Lead Software Engineer

Trevor Zhang
T3Go
Big Data Sr. Engineer

Gianmario Spacagna
Helixa
Chief Scientist, Head of AI

Leonardo Militano
Zurich University
Senior Researcher

Yuandong Xie
Unisound
Platform Researcher

Yu Jin
Electronic Arts
Sr. Engineering Manager
Schedule Anchor
SCHEDULE-AT-A-GLANCE
MORE Program details coming soon.
Times are listed in Pacific Daylight Time (PDT)
KEYNOTES
Data platforms span multiple clusters, regions and clouds to meet the business needs for agility, cost effectiveness, and efficiency. Organizations building data platforms for structured and unstructured data have standardized on separation of storage and compute to remain flexible while avoiding vendor lock-in. Data orchestration has emerged as the foundation of such a data platform for multiple use cases all the way from data ingestion to transformations to analytics and AI.
In this keynote from Haoyuan Li, founder and CEO of Alluxio, we will showcase how organizations have built data platforms based on data orchestration. The need to simplify data management and acceleration across different business personas has given rise to data orchestration as a requisite piece of the modern data platform. In addition, we will outline typical journeys for realizing a hybrid and multi-cloud strategy.
Speakers:
Haoyuan (H.Y.) Li is the Founder and CEO of Alluxio. He graduated with a Computer Science Ph.D. from the AMPLab at UC Berkeley. At the AMPLab, he co-created and led Alluxio (formerly Tachyon), an open source virtual distributed file system. Before UC Berkeley, he got a M.S. from Cornell University and a B.S. from Peking University, all in Computer Science.
In this keynote, Calvin Jia will share some of the hottest use cases in Alluxio 2 and discuss the future directions of the project being pioneered by Alluxio and the community. Bin Fan will provide an overview of the growth of Alluxio open-source community with highlights on community-driven collaboration with engineering teams from Microsoft and Alibaba to advance the technology.
Speakers:
Calvin Jia is the top contributor of the Alluxio project. He has been involved as a core maintainer and release manager since the early days when the project was known as Tachyon. Calvin has a B.S. from UC, Berkeley.
Bin Fan is the founding engineer and VP of Open Source at Alluxio, Inc. Prior to Alluxio, he worked for Google to build the next-generation storage infrastructure. Bin received his Ph.D. in Computer Science from Carnegie Mellon University on the design and implementation of distributed systems.
Details coming soon…
Speakers:
Parviz has been with Intel 23+ years and holds a degree in Computer and Electrical Engineering and is a recipient of Intel Achievement Award (IAA) and Intel Quality Award (IQA). He is primarily responsible for designing and driving development of Artificial Intelligence, Big Data, Service Oriented/Microservices Architecture, Cloud, and IoT computing architectures in support of Intel’s focus areas within financial Services Industry. He is member of Silicon Valley CTO Professionals, Linux Foundation, Blockchain Hyper Ledger, Cloud Computing Group E3C, Cloud Security Alliance (CSA), DMTF, and other organizations.
Refill your coffee and get ready for what’s next!
CLOUD NATIVE JOURNEYS – MODERNIZING DATA PLATFORMS
Electronic Arts (EA) is a leading company in the gaming industry, providing over a thousand games to serve billions of users worldwide. The EA Data & AI Department builds hundreds of platforms to manage petabytes of data generated by games and users every day. These platforms consist of a wide range of data analytics, from real-time data ingestion to ETL pipelines. Formatted data produced by our department is widely adopted by executives, producers, product managers, game engineers, and designers for marketing and monetization, game design, customer engagement, player retention, and end-user experience.
Near real-time information for EA’s online services is critical for making business decisions, such as campaigns and troubleshooting. These services include, but are not limited to, real-time data visualization, dashboarding, and conversational analytics. Highly time-sensitive applications such as BI software, dashboards and AI tools heavily rely on these services. To support these use cases, we studied an innovative platform with Presto as the computing engine and Alluxio as a data orchestration layer between Presto and S3 storage. We evaluated this platform with real industrial examples of data visualization, dashboarding, and a conversational chatbot. Our preliminary results show that Presto with Alluxio outperforms S3 significantly in all cases, with a 6x performance gain when handling a large number of small files.
Speakers:
After receiving her Ph.D. degree from UMass, Boston in 2019, Teng started her career as a software engineer in Electronic Arts, Data Platform & AI Department. Teng mainly focuses on building high-efficiency data processing platforms and high-impact business intelligent services, with her strong hands-on skills in architecture, design, implementation, and operations.

Du Li
Yu Jin

Sundeep Narravula
Datasapiens is an international data-analytics startup based in Prague. We help our clients to uncover the value of their data and open up new revenue streams for them. We provide an end-to-end service that manages the data pipeline and automates the process of generating data insights.
In this talk, we will describe how we have solved an issue with large S3 API costs incurred by Presto under several usage concurrency levels by implementing Alluxio as a data orchestration layer between S3 and Presto. Also, we will show the results of an experiment with estimating the per-query S3 API costs using the TPC-DS dataset.
Speakers:
Juraj leads the technical development. Covering application development, data engineering, and data science. He studied pure and applied mathematics at the Czech Technical University in Prague. Juraj’s past experience includes Deloitte – as a financial modeler – and Deutsche Boerse as a software developer. Juraj is passionate about modern technologies and mathematical models.
Koen holds a Master in Marketing Communication Sciences and an Advanced Master of Science – magna cum laude – in Marketing Analysis from Ghent University. He worked 7 years at dunnhumby in various roles including promotions, trade intelligence & shopper thoughts in the UK. Later he became the head of the solutions team for the CZ & SK market spearheading the innovation of cloud technologies, open source software development and interactive data visualizations. Koen has extensive experience in delivering insights at board level.
Details coming soon…
Speakers:
Tom Panozzo, Chief Technology Officer at Data Realty
Details coming soon…
Speakers:
Katarzyna works as a Data Scientist at ING Tech, focusing on applications of Machine Learning and Statistical Analysis in Cybersecurity.
Mariusz Derela is DevOps Engineer at ING focused on security. As a member of Hunt Squad he is responsible for providing new solutions that can improve security processes in ING.
Details coming soon…
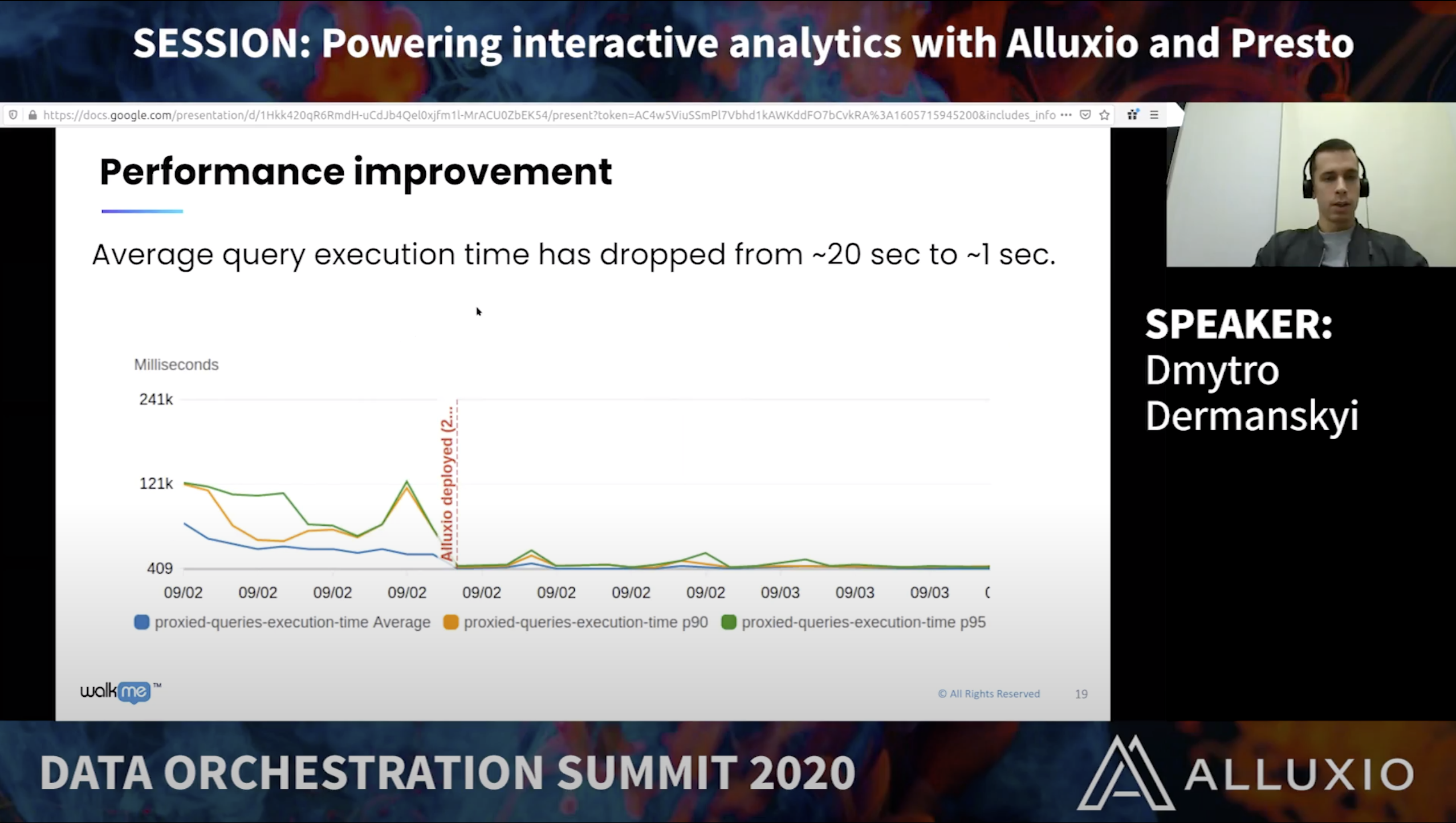
Speakers:
Dima Dermanskyi is a Data Engineering lead at WalkMe where he is responsible for development and operation of data-warehousing and computation infrastructure powering WalkMe’s analytics platform. He is obsessed with building data applications, and has a long record in development distributed systems in such domains as Telecom and e-commerce. Dima holds a master’s degree in computer science from Kyiv Polytechnic Institute.
Lunch, it’s time to grub!
HIGH PERFORMANCE SQL ANALYTICS
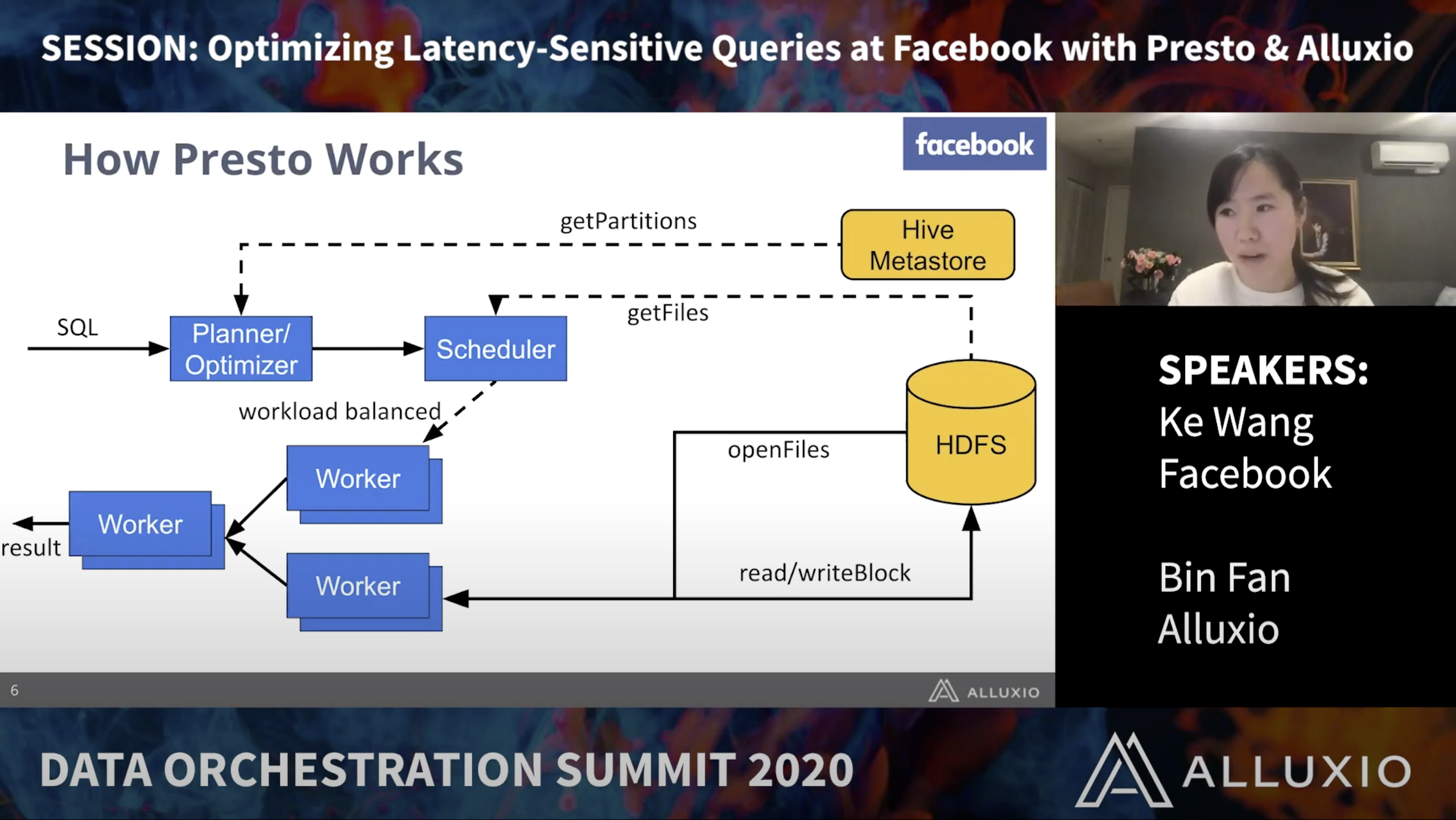
For many latency-sensitive SQL workloads, Presto is often bound by retrieving distant data. In this talk, Rohit Jain from Facebook will introduce their teams’ collaboration with Alluxio on adding a local on-SSD Alluxio cache inside Presto workers at Facebook to improve queries with unsatisfied latency.
Speakers:
Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.
Details coming soon…
Speakers:
Jiawei Zhang, Data Platform Engineer
Yichuan Huang, Data Platform Engineer

Grace Lu, Data Platform Engineer

Wenlong Xiong, Data Platform Engineer
Presto, an open source distributed SQL engine, is widely recognized for its low-latency queries, high concurrency, and native ability to query multiple data sources. Proven at scale in a variety of use cases at Comcast, GrubHub, FINRA, LinkedIn, Lyft, Netflix, Slack, Zalando, in the last few years Presto experienced an unprecedented growth in popularity in both on-premises and cloud deployments over Object Stores, HDFS, NoSQL and RDBMS data stores.
Delta Lake, a storage layer originally invented by Databricks and recently open sourced, brings ACID capabilities to big datasets held in Object Storage. While initially designed for Spark, Delta Lake now supports multiple query compute engines including Presto.
In this talk we discuss how Presto enables query-time correlations between Delta Lake, Snowflake, and Elasticsearch to drive interactive BI analytics across disparate datasets.
Speakers:
Kamil is a technology leader in the large-scale data warehousing and analytics space. He is CTO of Starburst, the enterprise Presto company. Prior to co-founding Starburst, Kamil was the Chief Architect at the Teradata Center for Hadoop in Boston, focusing on the open-source SQL engine Presto. Previously, he was the co-founder and chief software architect of Hadapt, the first SQL-on-Hadoop company, acquired by Teradata in 2014. Kamil holds master’s degrees in Computer Science from Yale University and Wroclaw University of Technology. He is co-author of several US patents and a recipient of 2019 VLDB Test of Time Award.
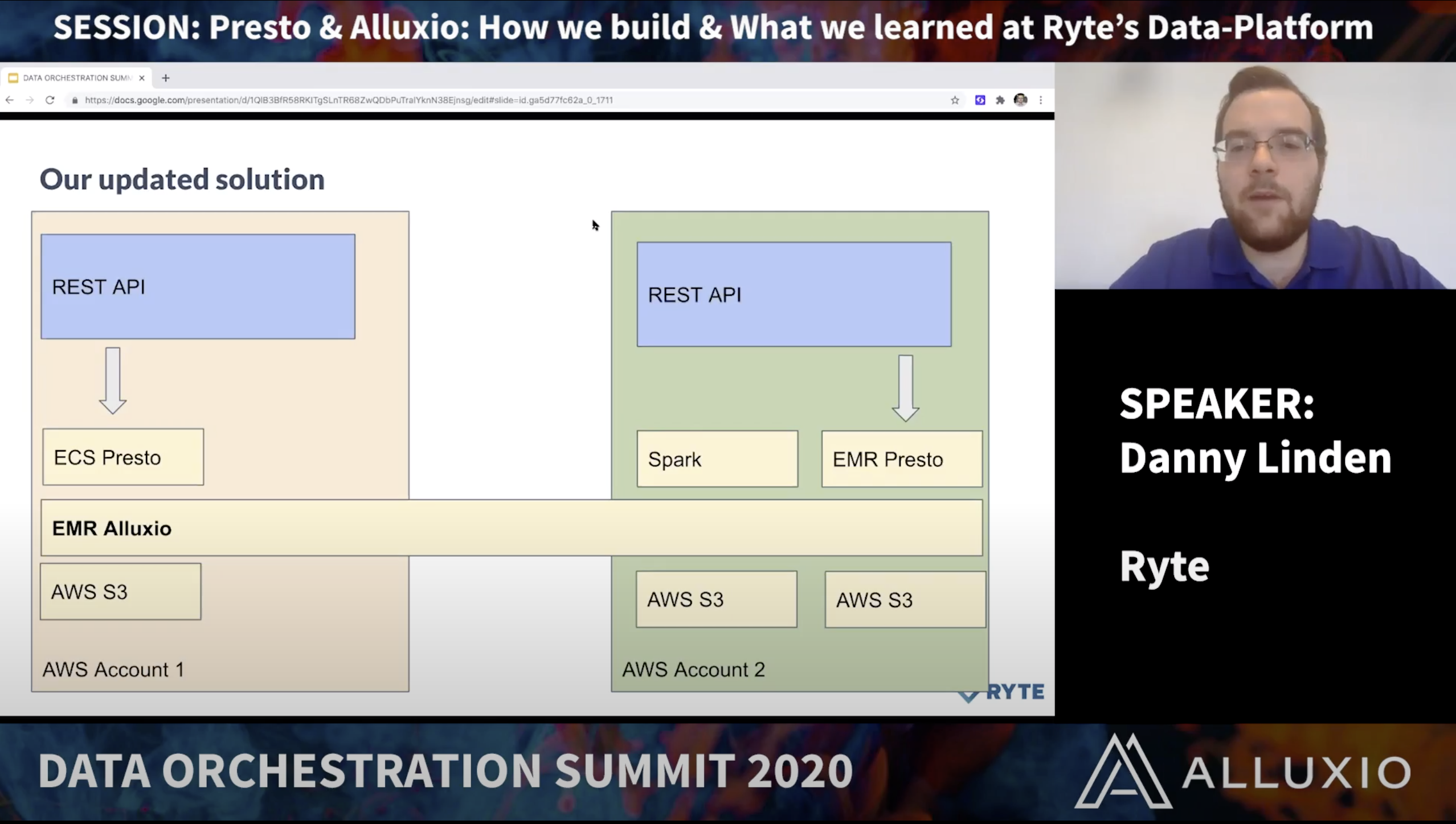
Presto & Alluxio on AWS: How we build a Up-To-Date Data-Platform at Ryte.
Speakers:
Danny is a chapter lead software engineer at Ryte responsible for their development team and technology stack. Danny’s background is in modern big data systems and scaling web & cloud infrastructure.
This talk introduces T3Go’s solution in building an enterprise-level data lake based on Apache Hudi & Alluxio, and how to use Alluxio to accelerate the reading and writing of data on the data lake when compute and storage are segregated.
Speakers:
Trevor Zhang is a Big Data Sr Engineer at T3. His work at T3 focuses on data lake and the surrounding big data ecosystem. He has extensive experience in big data analysis and computing. Trevor is also a contributor to many open source projects including Apache Hudi, Apache Zeppelin, and Alluxio.

Vino Yang is the Head of T3Go Big Data Platform. He is also an Apache Hudi committer & PMC member, an Apache Kylin committer, the author of Flink Cube engine, and an Apache Flink active contributor. Prior to T3Go, Vino was a senior engineer at Tencent, and led the Flink framework in Tencent from landing to supporting the daily processing scale of nearly 20 trillion messages.
Unicom’s traditional batch architecture consists mainly of IOE, Hive, and Greenplum systems. With the development of business, a large number of computing application modules based on diverse scenarios, chimney-like, decentralized applications have emerged. To solve the problem of resource fragmentation, we have introduced a unified computing platform for computing ecology with Spark and Alluxio as the core. Alluxio plays an important role in accelerating data processing and ensuring process stability.
Speakers:
Ce Zhang, China Unicom’s big data engineer, is responsible for the operation and optimization of Spark, Alluxio, Flink and other related systems. As an Alluxio contributor, he is active in the areas of Alluxio kernel, system operations, and community outreach.
KEYNOTES
Distributed applications are not new. The first distributed applications were developed over 50 years ago with the arrival of computer networks, such as ARPANET. Since then, developers have leveraged distributed systems to scale out applications and services, including large-scale simulations, web serving, and big data processing. However, until recently, distributed applications have been the exception, rather than the norm. However, this is changing quickly. There are two major trends fueling this transformation: the end of Moore’s Law and the exploding computational demands of new machine learning applications. These trends are leading to a rapidly growing gap between application demands and single-node performance which leaves us with no choice but to distribute these applications. Unfortunately, developing distributed applications is extremely hard, as it requires world-class experts. To make distributed computing easy, we have developed Ray, a framework for building and running general-purpose distributed applications.
Speakers:
Ion Stoica is a Professor in the EECS Department at the University of California at Berkeley. He is currently the leader of RISELab. He does research on cloud computing and networked computer systems. Past work includes Apache Spark, Apache Mesos, Tachyon, Chord DHT, and Dynamic Packet State (DPS). He is an ACM Fellow and has received numerous awards, including the SIGOPS Hall of Fame Award (2015), the SIGCOMM Test of Time Award (2011), and the ACM doctoral dissertation award (2001). He is also a co-founder of Anyscale in 2019 to commercialize technologies for distributed Python especially for AI applications, a co-founder of Databricks in 2013 to commercialize technologies for Big Data processing, and a co-founder of Conviva Networks in 2006 to commercialize technologies for large scale video distribution.
We introduce Data Orchestration Hub, a management service that makes it easy to build an analytics or machine learning platform on data sources across regions to unify data lakes. Easy to use wizards connect compute engines, such as Presto or Spark, to data sources across data centers or from a public cloud to a private data center. In this session, you will witness the use of “The Hub” to connect a compute cluster in the cloud with data sources on-premises using Alluxio. This new service allows you to build a hybrid cloud on your own, without the expertise needed to manage or configure Alluxio.
Speakers:
Adit is a product manager at Alluxio. He is also a core maintainer and PMC member of the Alluxio Open Source project. Before joining Alluxio he was a research engineer at Hewlett-Packard Laboratories. His experience is in distributed systems, storage systems, and large scale data analytics. He has an M.S. from Carnegie Mellon University and a B.S. from IIT.
In this keynote, you will learn about the evolution of the global data platform at Rakuten spread across multiple regions, and clouds. In addition, you will hear about the journey across the years, and the use of data orchestration for multiple use cases.
Speakers:
Sandipan Chakraborty works as Director of Engineering in the Global Data Office of Rakuten. He and his team are responsible for developing and maintaining the “Global Shared Data Analytics Platform” for Rakuten Group. The platform today serves analytical and Data services to more than 80+ different businesses in Rakuten Group. Sandi spent his last 20+ years in various aspects of Data including Data Integration, distributed systems, Big Data and BI.
Over the years, Alluxio has grown significantly to be the data orchestration framework for the cloud. The community developers and users have contributed a lot of effort and innovation to make Alluxio the system it is today. There are many users and companies deploying Alluxio at very large scale, and with the large scale, comes different types of challenges.
In this talk, I will introduce the high-level architecture of the current system, and present the various components of Alluxio. Also, I will discuss some of the main challenges of large scale Alluxio deployments, and the lessons we learned from those environments. This talk will detail some of the major scalability improvements added in the past several months, and how users can benefit from the changes.
Speakers:

Gene Pang is the PMC Maintainer of the Alluxio open source project and a founding member of Alluxio, Inc. He graduated with a Ph.D. from the AMPLab at UC Berkeley, working on distributed database systems. Before starting at Berkeley, he worked at Google and has an M.S. from Stanford University, and a B.S. from Cornell University.
Grab some coffee and get ready for what’s next!
HYBRID CLOUD ANALYTICS AND AI
Describe benefits and methods Alluxio enables secure data access in the Comcast’s dx hybrid data cloud.
- Review the data access challenges and tradeoffs in hybrid cloud
- Review our hybrid architecture and the important role Alluxio plays
- Provide performance metrics to highlight the benefits
Speakers:
Michael Fagan is a Distinguished Architect at Comcast and the Chief Architect of the DX organization. He has almost 30 years of experience building mission-critical systems for Media, Telecom, and Defense organizations. In his spare time, he is an avid mead maker.

Prashant Khanolkar is a Principal Big Data Architect at Comcast within the DX organization. He leads the architecture charge for several key Initiatives within the dx Data Foundry to build a self-service platform to make Big Data securely and universally available to everyone within the enterprise at Comcast-scale and to empower, enable and transform Comcast into an insights-driven organization. He has more than 30 years of diverse industry experience with a focus on Telecommunications and Cable industry verticals. In his spare time he enjoys skiing and spending time with family in the great Colorado outdoors.
Data infrastructure on-premises is increasingly complex and cloud adoption is attractive for business agility. Operating a hybrid environment is an approach to start benefiting from cloud elasticity quickly without abandoning the infrastructure on-premises. In this session I will discuss the benefits of using Alluxio’s Data Orchestration Platform to dynamically burst Apache Spark and Presto workloads to Amazon EMR for best performance and agility.
Speakers:
Roy is an analytics specialist helping customers modernize their big data platforms running on AWS
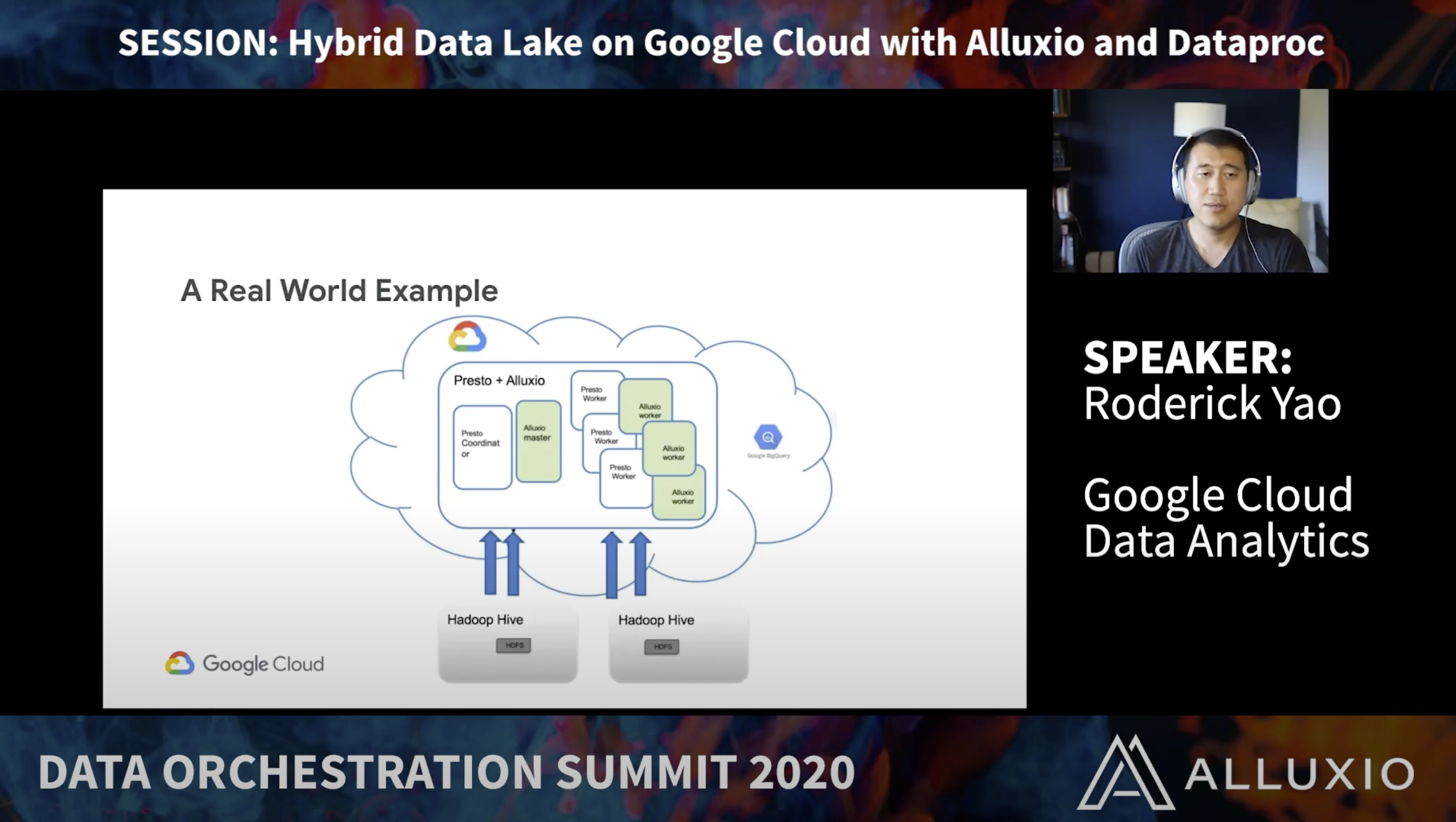
Dataproc is Google’s managed Hadoop and Spark platform. In this talk, we will showcase how to swiftly build a hybrid cloud data platform with Alluxio and Presto and migrate data seamlessly.
Speakers:
Roderick Yao is a Product Manager for Google Cloud Data Analytics products. He also designs and manages large scale migration to Google Cloud’s data platform for strategic customers. Roderick holds a M.S in IT from Bentley University and B.S in Computer Science from South China University of Technology.
Today, many people run deep learning applications with training data from separate storage such as object storage or remote data centers. This presentation will demo the Intel Analytics Zoo + Alluxio stack, an architecture that enables high performance while keeping cost and resource efficiency balanced without network being I/O bottlenecked.
Intel Analytics Zoo is a unified data analytics and AI platform open-sourced by Intel. It seamlessly unites TensorFlow, Keras, PyTorch, Spark, Flink, and Ray programs into an integrated pipeline, which can transparently scale from a laptop to large clusters to process production big data. Alluxio, as an open-source data orchestration layer, accelerates data loading and processing in Analytics Zoo deep learning applications.
Speakers:
Jiao (Jennie) Wang is a software engineer on the Machine Learning Platform team at Intel working in the area of big data analytics. She is engaged in developing and optimizing distributed deep learning framework on Apache Spark and provides customer support for end to end AI solutions on big data platforms.
Tsai Louie is working on optimizing AI Software on Intel architectures. He is currently focused on Deep Learning Software like BigDL, Tensorflow, and MKL-DNN. Prior to joining TCE team, Louie also supported different software performance optimization tasks like Baidu’s autonomous driving project with Intel performance libraries and tools.
ORCHESTRATING DATA FOR MACHINE LEARNING
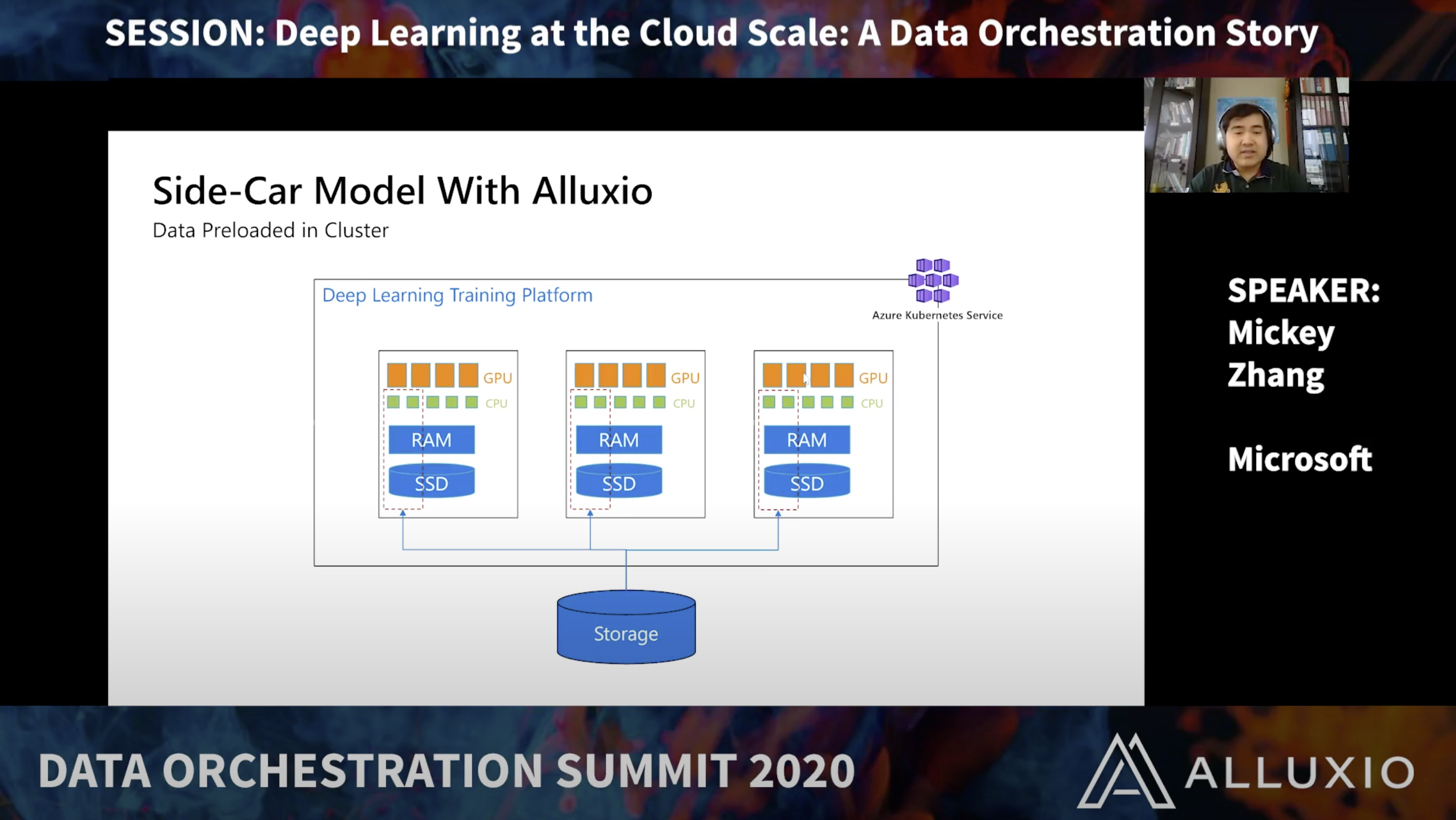
Details coming soon…
Speakers:
Mickey is a software engineer at Microsoft. He works on Azure Machine Learning Platform, focusing on data processing at scale for ML workflows. Mickey graduated from University of Illinois Urbana-Champaign with a B. S. in Computer Engineering.
Nowadays, cloud native environments have attracted lots of data-intensive applications deployed and ran on them, due to the efficient-to-deploy and easy-to-maintain advantages provided by cloud native platforms and frameworks such as Docker, Kubernetes. However, cloud native frameworks does not provide the data abstraction support to the applications natively. Therefore, we build Fluid project, which co-orchestrate data and containers together. We use Alluxio as the cache runtime inside Fluid to warm up hot data. In this report, we will introduce the design and effects of the Fluid project.
Speakers:
Yang Che is a Staff Engineer at Alibaba Cloud. He works in the Container Service for Kubernetes (ACK) team and focuses on Kubernetes and container related product development. Yang also works on building an elastic machine learning platform with cloud-native technology. He is the main author and core maintainer of GPU share Scheduler, and an active contributor at communities like Kubernetes, Docker, and Kubeflow.
Dr. Rong Gu, a founding PMC member and maintainer of the Alluxio Open Source project. Rong is an associate researcher at the Department of Computer Science of Nanjing University. He is also the author of one monograph on distributed file systems and has published more than 20 papers in peer-reviewed frontier journals. His research has been applied at Intel, Alibaba, Baidu, ByteDance, Sinopec, Huatai Securities, etc. Previously, Rong worked in the R&D of big data systems at Microsoft Research, Intel, and Baidu. Rong started contributing to Alluxio Open Source while pursuing his Ph.D. at PASALab at Nanjing University.
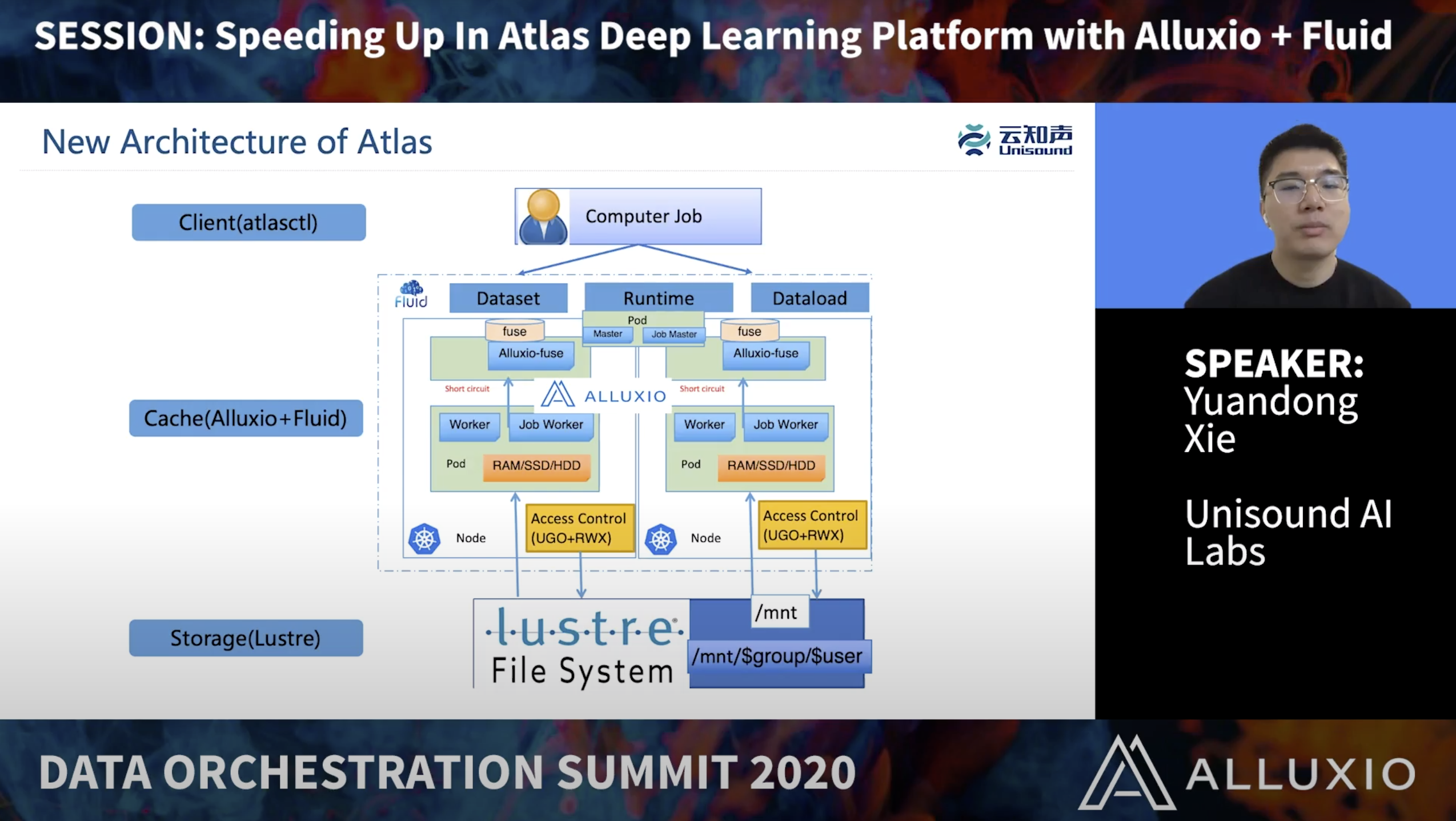
Unisound focuses on Artificial Intelligence services for the Internet of Things. It is an artificial intelligence company with completely independent intellectual property rights and the world’s top intelligent voice technology. Atlas is the Deep Learning platform within Unisound AI Labs, which provides deep learning pipeline support for hundreds of algorithm scientists. This talk shares three real business training scenarios that leverage Alluxio’s distributed caching capabilities and Fluid’s cloud native capabilities, and achieve significant training acceleration and solve platform IO bottlenecks. We hope that the practice of Alluxio & Fluid on Atlas platform will bring benefits to more companies and engineers.
Speakers:
YuanDong Xie is a Platform Researcher of Unisound AI Labs, focusing on AI Infrastructure, Deep Learning and High Performance. He is responsible for the overall architecture design of Atlas platform, providing training acceleration and inference optimization environment for algorithm scientists. Yuandong is also an algorithm researcher in computer version, focusing on cross-modal video generation. He also likes to explore and contribute to open source technologies.
Data and Machine Learning (ML) technologies are now widespread and adopted by literally all industries. Although recent advancements in the field have reached an unthinkable level of maturity, many organizations still struggle with turning these advances into tangible profits. Unfortunately, many ML projects get stuck in a proof-of-concept stage without ever reaching customers and generating revenue. In order to effectively adopt ML technologies, enterprises need to build the right business cases as well as to be ready to face the inevitable technical challenges. In this talk, we will share some common pitfalls, lessons learned, and engineering practices, faced while building customer-facing enterprise ML products. In particular, we will focus on the engineering that delivers real-time audience insights everyday to thousands of marketers via the Helixa’s market research platform.
During the talk you will learn:
- An overview of the Helixa ML end-to-end system
- Useful engineering practices and recommended tools (PyData stack, AWS, Alluxio, scikit-learn, tensorflow, mlflow, jupyter, github, docker, Spark, to name a few..)
- The R&D workflow and how it integrates with the production system
- Infrastructure considerations for scalable and cheap deployment, monitoring, and alerting
- How to leverage modern cloud serverless architectures for data and machine learning applications
Speakers:
Gianmario is the Chief Scientist and Head of AI at Helixa. His team’s mission is building the next generation of models of consumers patterns with careful attention to their potential and effects on society.
His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. Previously, he worked as a data scientist in IoT automotive (Pirelli Cyber Technology), retail and business banking (Barclays Analytics Centre of Excellence), threat intelligence (Cisco Talos), predictive marketing (AgilOne), plus some occasional freelancing.
He’s a co-author of the book Python Deep Learning, author of the DataScienceVademecum blog, a contributor to the “Professional Manifesto for Data Science,” founder of the Data Science Milan community, and speaker to several data and machine learning events.
Gianmario holds an MBA (Quantic School of Technology), and a master’s degree in Telematics (Polytechnic of Turin) and Software Engineering of Distributed Systems (KTH of Stockholm).
His favorite hobbies include martial arts, home cooking, social sciences, and exploring the surrounding nature on his motorcycle.
High performance sql analytics
Enterprises everywhere are racing to build the optimal analytics stack for creating repeatable success with predictive analytics, machine learning, and data applications. Cloud data platforms like data warehouses and data lakes are foundational elements of these software stacks and their associated data pipelines. But existing SQL query methods against these data platforms have repeatedly demonstrated disappointing performance and scaling due to poor concurrency.
In this presentation, we will discuss the use of the intelligent precomputation capabilities of Kyligence Cloud as a means of delivering on the promise of pervasive analytics at scale with massive concurrency and sub-second query latencies on large datasets in the cloud.
Kyligence, with our partner Alluxio, sits between the data platform and the processing layer. Kyligence Cloud delivers precomputed datasets for OLAP queries, BI dashboards, and machine learning applications.
Speakers:
George Demarest, Head of Marketing at Kyligence, is responsible for all go-to-market activities in North and South America. He spent several years as the lead marketer for the Oracle Database before turning to big data products for startups such as MapR, Bigstream, and Unravel. He has worked on all aspects of go-to-market activities for enterprise technology platforms such as relational databases, cloud computing, Hadoop/Spark, AIOps, and advanced analytics.
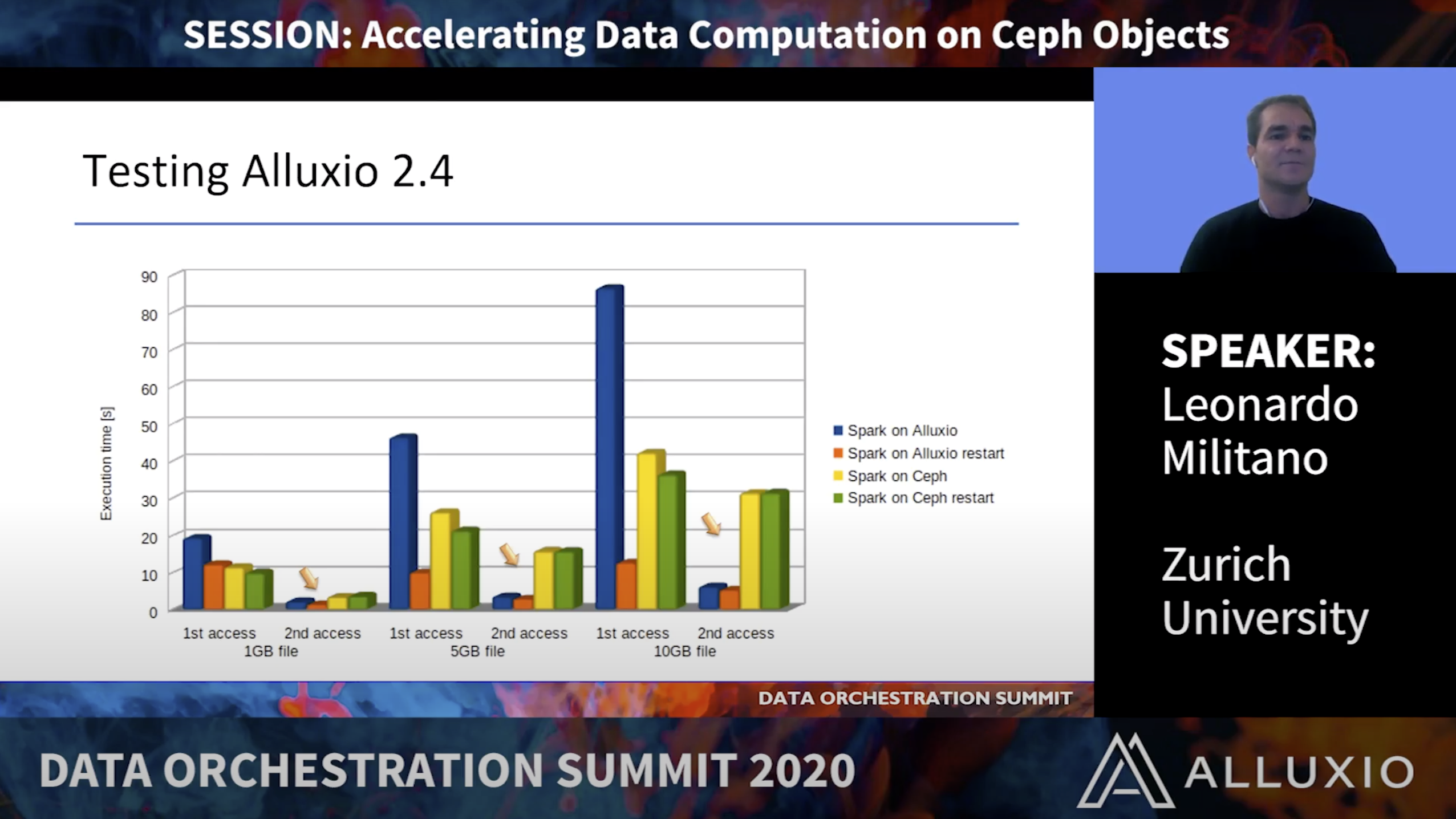
In this talk, we will present how using Alluxio computation and storage ecosystems can better interact benefiting of the “bringing the data close to the code” approach. Moving away from the complete disaggregation of computation and storage, data locality can enhance the computation performance. During this talk, we will present our observations and testing results that will show important enhancements in accelerating Spark Data Analytics on Ceph Objects Storage using Alluxio.
Speakers:
Leonardo Militano is a senior researcher at the Service Engineering lab at the Zurich University of Applied Sciences (ZHAW), Switzerland, where he leads the cloud storage initiative. He received his Ph.D in Telecommunications Engineering in 2010 from the University of Reggio Calabria, Italy. Before joining ZHAW he was an Assistant Professor at the Mediterranea University in Italy, with interests in wireless and mobile networking.
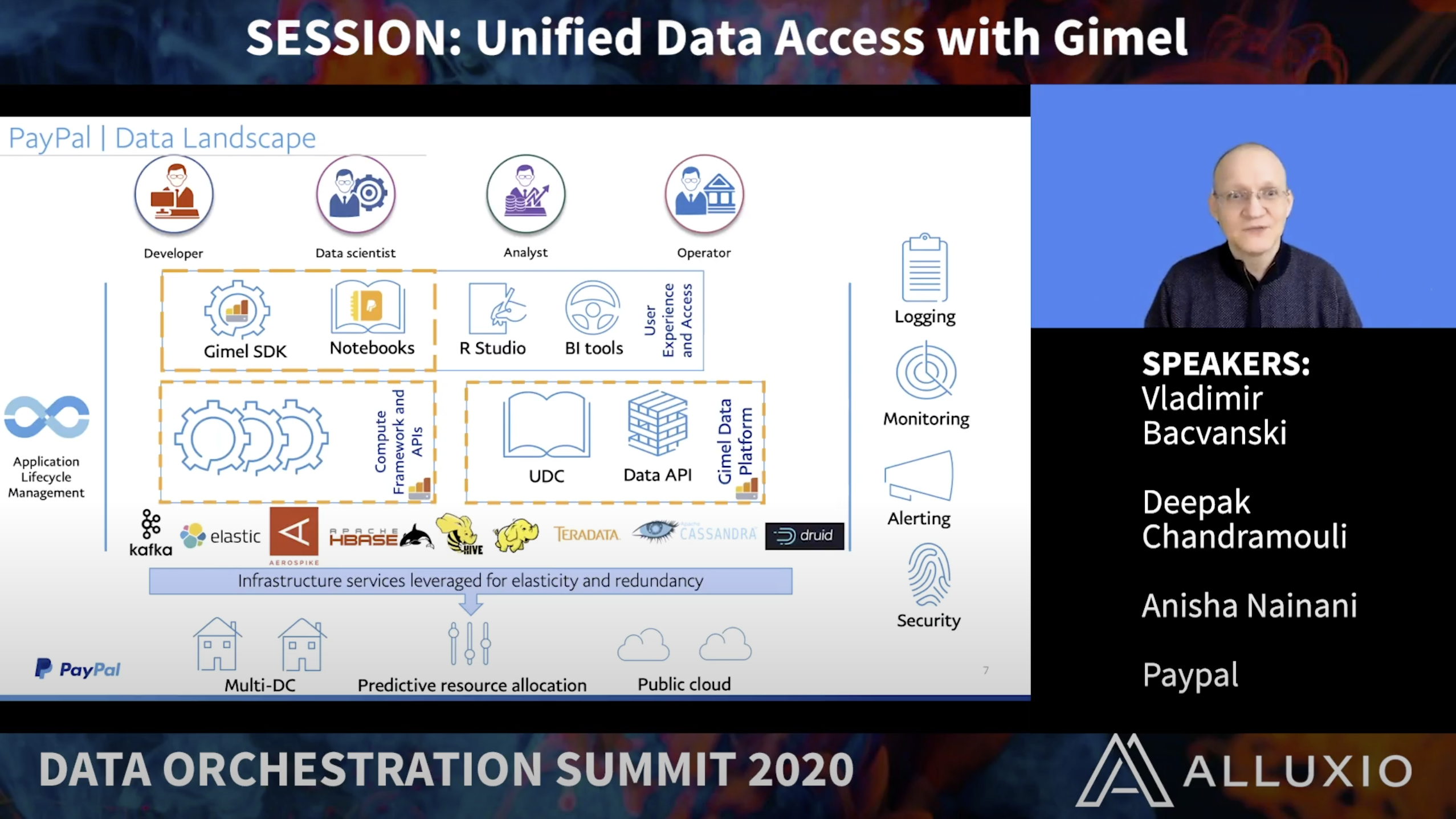
At PayPal & any other data driven enterprise – data users & applications work with a variety of data sources (RDBMS, NoSQL, Messaging, Documents, Big Data, Time Series Databases), compute engines (Spark, Flink, Beam, Hive), languages (Scala, Python, SQL) and execution models (stream, batch, interactive) to process petabytes of data. Due to this complex matrix of technologies and thousands of datasets, engineers spend considerable time learning about different data sources, formats, programming models, APIs, optimizations, etc. which impacts time-to-market (TTM).
To solve this problem and to make product development more effective, PayPal Data Platforms developed “Gimel”, an open source, unified analytics data platform which provides access to any storage through a single unified data API and SQL, which are powered by a centralized data catalog.
Speakers:
Deepak Chandramouli is an Engineering Lead in PayPal’s Enterprise Data Platforms Organization. Deepak currently manages the engineering for products – UDC (Unified Data Catalog) and Gimel.io (Apache Spark based Data Abstraction Layer). Deepak incubated Gimel and helped open source it. More recently, Deepak is focusing on building scalable Data Catalog in the context of emerging Data Governance & Regulatory demands. Deepak is a frequent speaker at industry leading data events.
Anisha Nainani is a Senior Software Engineer focusing on building Big Data platforms. She has been a core contributor of PayPal’s Unified Analytics Platform – Gimel which provides access to any storage through a single unified data API and SQL, that are powered by a centralized data catalog. Anisha also worked on Data Governance initiatives addressing the linking technical with business metadata to determine Data Lineage for Core Data Elements (CDE), an area of great impact for PayPal’s business data analytics. She received her Master’s degree in Computer Science from University of Texas at Dallas in 2016 with a focus on Data Engineering.
Dr. Vladimir Bacvanski is a Principal Architect with Strategic Architecture at PayPal. He is the lead architect for Privacy and the lead architect for Developer Experience, which includes variety of tools in the DevOps arena. Before joining PayPal, Vladimir was the CTO and founder of a custom development and consulting firm and has advised and worked with clients ranging from high-tech startups to financial and government organizations. Vladimir is the author of the popular O’Reilly course “Introduction to Big Data” and a coauthor of the O’Reilly course on Kafka. Vladimir received a PhD degree in Computer Science from Aachen University of Technology in Germany.
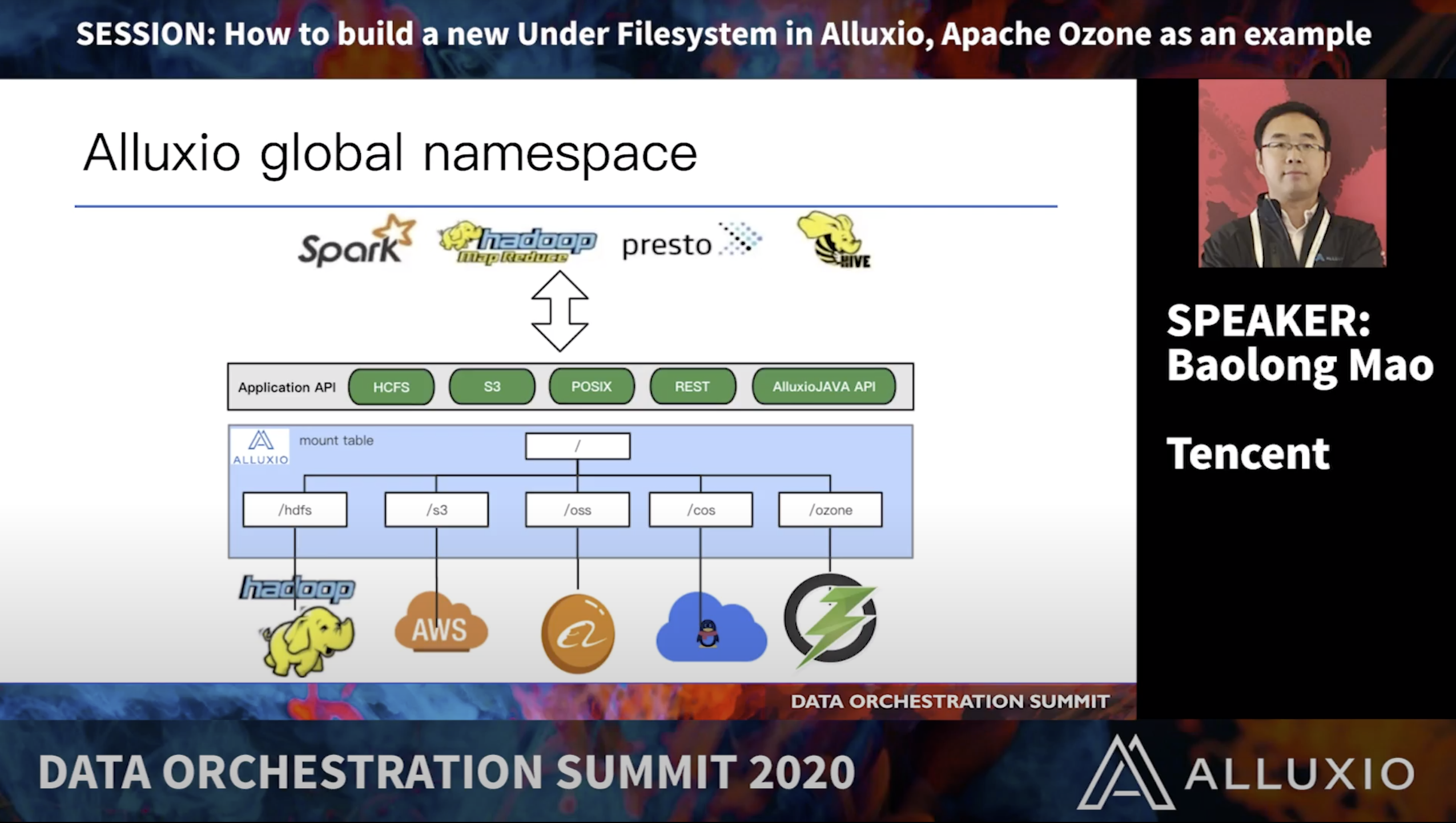
In this talk, Baolong Mao from Tencent will share his experience in developing Apache Ozone under file system, showing how to create a new Under File System in a few steps with minimal lines of code.
Speakers:
Davy Wang is the Chief Solutions Architect at Tencent Cloud International, providing technical leadership and strategy for Tencent Cloud’s global division. Previously, he was the regional director of Amazon AWS Greater China Region where under his direction, his team helped many of China’s top Internet companies design and optimize their architecture. Prior to that, he served as Director and Senior Technical Expert at Alibaba Cloud, and Senior Architect Manager at IBM Global Services.
Baolong Mao is a Sr. System Engineer at Tencent Data Lake R&D. He is also a PMC member of Alluxio Open Source Community. At Tencent, Baolong is currently developing Apache Ozone, which is the next-generation distributed object store, aiming to build a data lake by Ozone. Prior to Tencent, he worked for Alibaba and JD.com to build a big data distributed storage system by HDFS and Alluxio.
JD.com is one of the largest e-commerce corporations. In big data platform of JD.com, there are tens of thousands of nodes and tens of petabytes off-line data which require millions of spark and MapReduce jobs to process everyday. As the main query engine, thousands of machines work as Presto nodes and Presto plays an import role in the field of In-place analysis and BI tools. Meanwhile, Alluxio is deployed to improve the performance of Presto. The practice of Presto & Alluxio in JD.com benefits a lot of engineers and analysts.
Speakers:
Wenjun Tao, Senior Software Engineer @ JD.com, core member of Presto Team. Graduated from the School of Computer Science, Beijing Institute of Technology. The main research interest during the master’s degree is distributed and parallel systems.
Thank you for joining us virtually this year!
SPONSORS



Sponsorship anchor
