In this blog, we discuss the data access challenges in AI and why commonly used NAS/NFS may not be a good option for your organization.
1. Early Architecture of AI/ML
According to Gartner, although LLMs are on the hype, most organizations are in the early stages, with some in production.
In the early stages of building AI platforms, organizations focus on getting systems up and running to pilot projects and proofs of concept. These early architectures, or pre-production architectures, aim to cover the basic capabilities needed for model training and deployment. Many organizations already have such early AI architectures in production today.
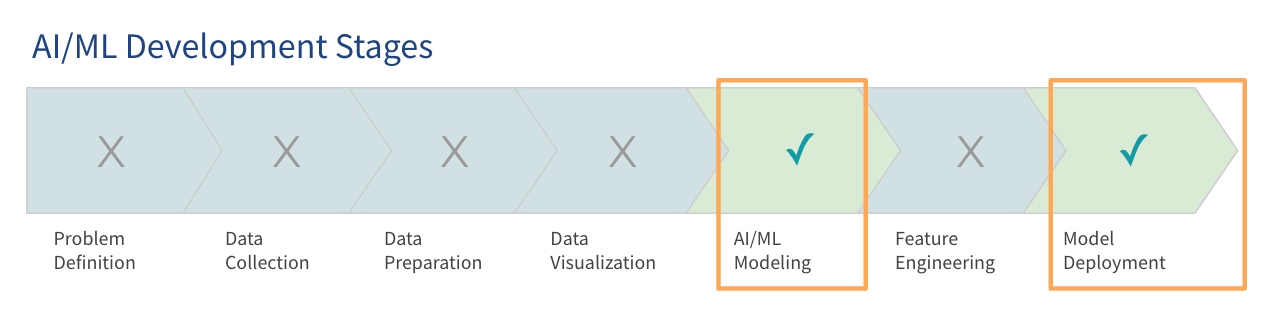
These early AI architectures often turn inefficient over time as data and models grow. Organizations are training models in the cloud and expect their data and cloud usage to rise substantially over the next 12 months as projects scale up. Many start with data sizes that fit in memory today but know they will need to prepare for much larger workloads soon.
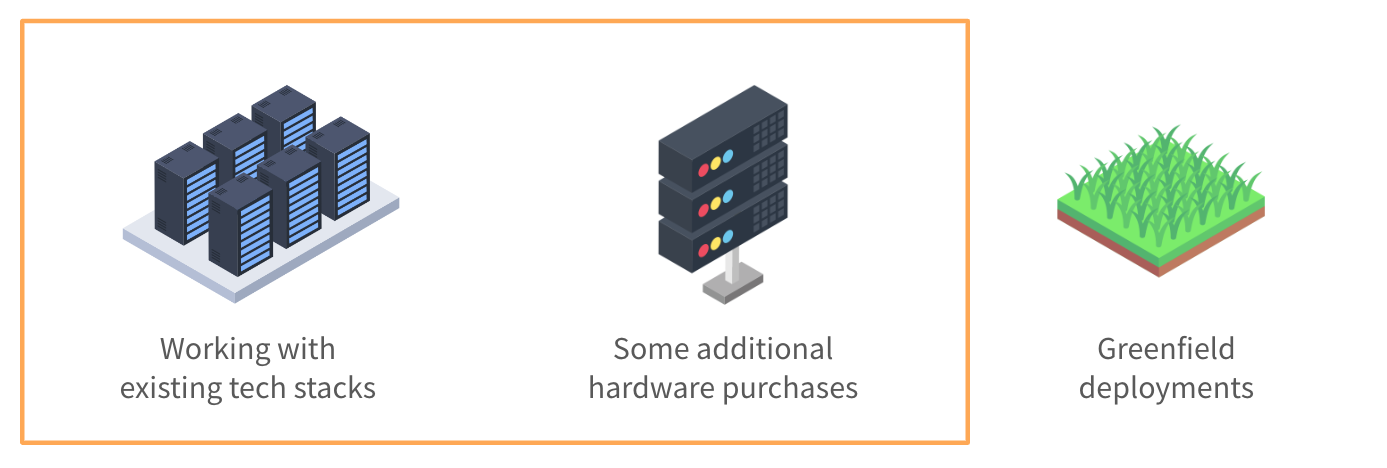
Organizations may choose to work with existing tech stacks or greenfield deployments. In this blog, we focus on designing stacks that are more scalable, agile, and performant with existing stacks or some additional hardware purchases.
2. Data Access Challenges
2.1 Data Access is a Critical Component in AI/ML
As AI/ML architectures advance, GPUs are rapidly improving in power and scale while datasets for model training continue to massively grow in size. Alongside compute, storage and networking, we propose that data access is another critical component of future-proof AI platforms.

Data access refers to technologies like data serving, backing stores (NFS, NAS), and high-performance caches such as Alluxio that facilitate getting data into compute for model training and deployment.
The goals of data access are throughput and data loading efficiency, which are becoming more important in AI/ML architecture today as GPUs are scarce – optimizing data loading can greatly reduce GPU idle time and increase GPU utilization. As such, high-performance data access needs to be a first-class architectural concern.
2.2 Data Access Challenges in Pre-production Architectures
As organizations scale their model training workloads on early AI architectures, several common data access challenges emerge:
- Model Training Efficiency is Below Expectations: Due to data access bottlenecks, training times are longer than expected based on compute provisioning. Slow data flows fail to feed GPUs adequately.
- Bottlenecks Around Data Synchronization: Manually copying or syncing data from storage to local GPU servers creates delays while building a queue for data to be staged.
- Concurrency and Metadata Issues: Shared storage sees contention when large jobs start in parallel. Slow metadata operations on storage backends add latency.
- Slow Performance or Low GPU Utilization: Despite significant investments in high-performance GPU infrastructure, inefficient data access results in idle and underutilized GPUs.
Teams are managing a mix of issues that exacerbate these problems further. Those issues include slow I/O storage that cannot keep up with the demands of high-performance GPU clusters. Manual data replication workflows and synchronization add delays while teams wait for data delivery to GPU servers. Architectural complexity from multiple data silos across hybrid infrastructure or multi-cloud environments also increases data wrangling headaches.
As a result, the end-to-end efficiency of the architecture falls short of expectations.
2.3 Existing Solutions
Challenges related to data access can be addressed by two common solutions.
Purchasing faster storage. Many organizations attempt to address slow data access issues by deploying faster storage options. Cloud providers offer high-performance storage, while specialized hardware vendors sell HPC storage to accelerate performance.
Adding NAS/NFS for object storage. Adding centralized NAS or NFS as backing stores for object stores like S3, MinIO, or Ceph is also a common approach. This approach helps teams consolidate data in a shared file system for simplified collaboration and sharing across users and workloads. It also allows leveraging data management capabilities around consistency, availability, replication, and scaling from proven NAS vendors.
However, these two common solutions may not solve your problems.
2.4 The Problems with Existing Solutions
While faster storage and centralized NFS/NAS provide incremental improvements, several downsides remain.
1. Faster Storage Means Data Migration, Even If Hidden
To benefit from the performance provided by the specialized storage, data must migrate from existing storage into new high-performance tiers. This leads to data movement behind the scenes. Migrating massive datasets can cause transfer times and reliability concerns around data corruption or loss during migration. Operational downtime interrupts services and slows project timelines while teams wait for data to sync.
2. NFS/NAS: Maintenance and Bottlenecks
As an additional storage tier, the maintenance, stability, and scalability challenges of NFS/NAS remain. Manual data copying from NFS/NAS to local GPU servers adds delay and resource duplication. Bursts in read demand from parallel jobs can overload NFS/NAS servers and cluster interconnects. Data syncing issues from remote NFS/NAS GPU clusters remain.
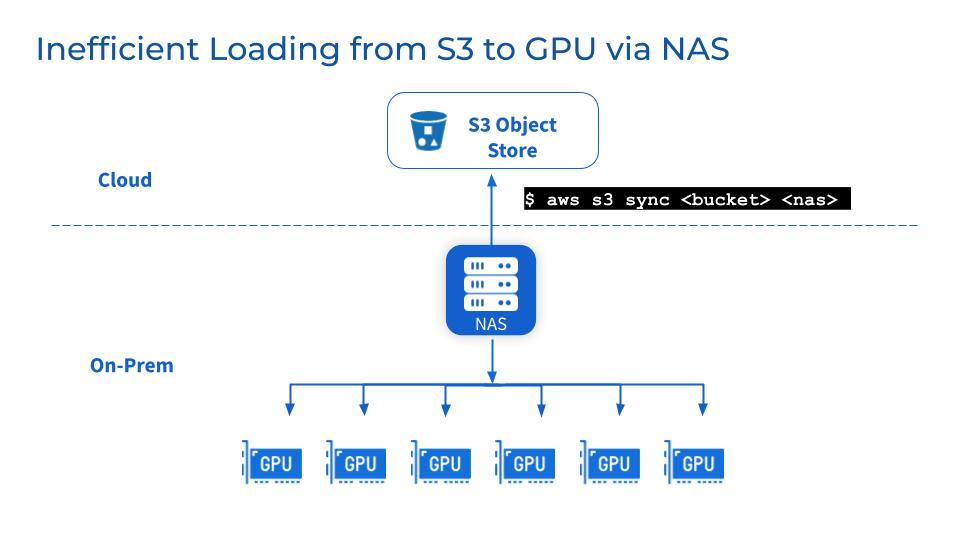
3. What If Vendor Changes are Required for Business Reasons?
Organizations may shift vendors because of cost optimization or contractual reasons. Multi-cloud flexibility requires easily porting massive datasets without vendor lock-in. However, moving petabyte-scale data stores risks significant downtime and interruptions to model development.
In short, while helpful in the short term, existing solutions fail to offer a scalable and optimized data access architecture tailored to AI/ML’s exponential appetite for data.
3. Alluxio as the Solution
3.1 Introducing Alluxio: High-performance Data Access
Alluxio can be added between compute and data sources. Alluxio provides data abstraction and distributed caching to make AI/ML architecture more performant and scalable.
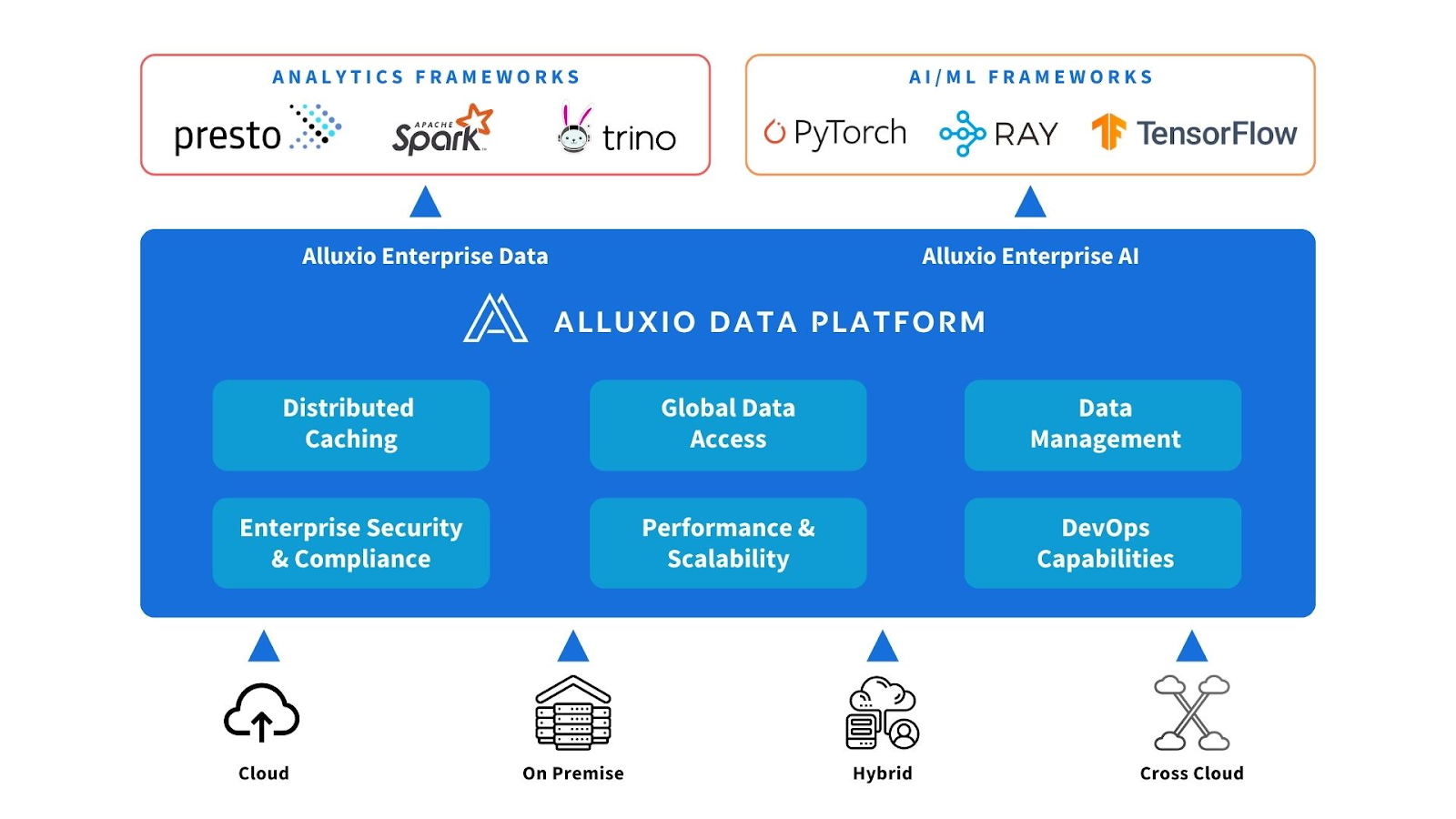
3.2 What Problems Are Addressed by Alluxio
Alluxio helps solve scalability, performance, and data management challenges faced by early AI architectures as data volume, model complexity, and GPU clusters expand.
1. Increasing Capacity
Alluxio scales beyond single node limits to serve training data sizes too large to fit in cluster memory or local SSDs. It connects disparate storage systems to present a unified data access layer for mounting petabyte-scale data lakes. Alluxio intelligently caches actively used files and metadata in memory and SSD tiers close to compute while avoiding full duplication of entire datasets.
2. Reducing Data Management
Alluxio streamlines data movement and placement across GPU clusters with automatic distributed caching. Teams avoid manual data copying or syncing to stage files locally. Alluxio handles propagating hot files across jobs with cluster awareness. This simplifies workflows even with 50 million or more objects per node.
3. Improving Performance
Purpose-built for accelerated workloads, Alluxio eliminates I/O bottlenecks from traditional storage that throttle throughput to GPUs. Distributed caching increases access speed to data by orders of magnitude. Alluxio serves local data access at memory and SSD speeds for greater GPU utilization instead of remote requests to network storage.
To summarize, Alluxio gives a performant and scalable data access layer to maximize the utilization of GPU resources as AI/ML data scales to the next level.
3.3 How Alluxio Works With Your Architecture
There are three ways Alluxio can work with existing architecture.
- Co-located with NAS: Alluxio deploys alongside existing NAS as a transparent caching tier to turbocharge I/O performance. Alluxio caches active data from the NAS in local SSDs across GPU nodes. Jobs redirect read requests to Alluxio’s SSD cache to bypass the NAS, removing the NAS bottleneck. Writes go through Alluxio for low-latency writes to SSD before being persisted asynchronously to the NAS.
- Stand-alone data access layer: As a dedicated high performance data access layer, Alluxio federates data from multiple sources like S3, HDFS, NFS or on-prem data lakes, to serve GPU nodes. Alluxio unifies disparate silos of data together under a single namespace and mounts storage backends as under stores. Frequently accessed data is distributed across Alluxio workers in SSD for local acceleration to GPUs.
- Virtual caching across GPU storage: Alluxio serves as virtual caching across local GPU storage. Data from S3 is synced to virtual Alluxio storage and shared between GPU nodes. No manual data copying between nodes is needed.
3.4 Alluxio on AWS – Reference Architecture and Benchmark Results
1. Reference Architecture
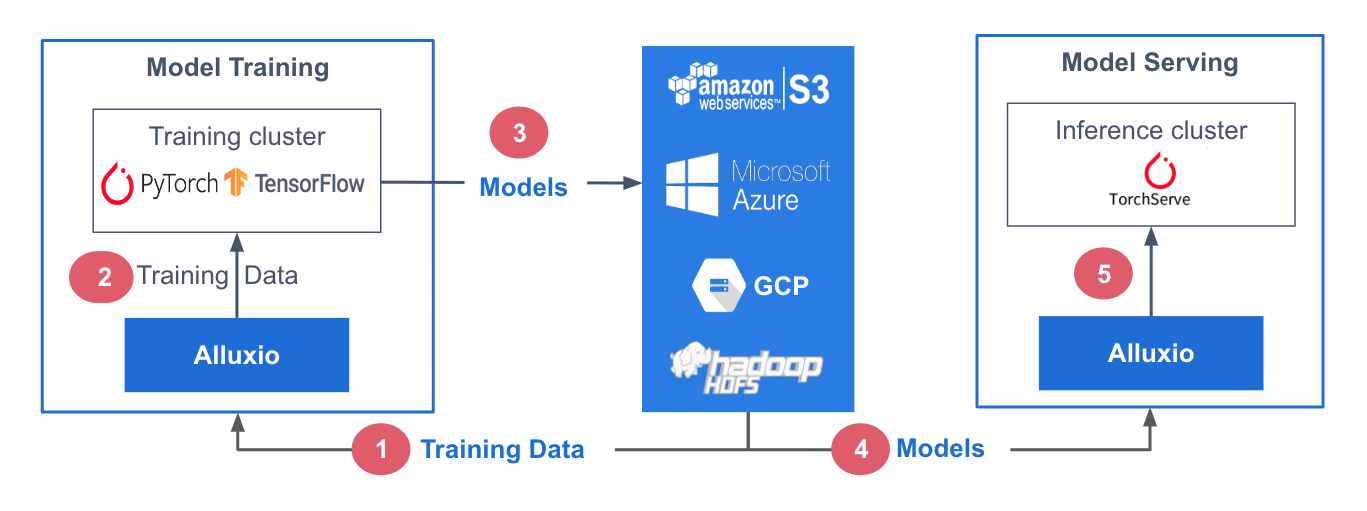
In this reference architecture, the training data is stored within a centralized data storage platform, AWS S3. Alluxio is employed to facilitate seamless provisioning of the training data to the model training cluster. ML training frameworks, including PyTorch, TensorFlow, scikit-learn, and XGBoost, are executed on CPU/GPU/TPU clusters. These frameworks utilize the training data to generate ML models, which are subsequently stored in a centralized model storage repository.
For the model serving stage, dedicated serving/inference clusters are utilized, employing frameworks such as TorchServe, TensorFlow Serving, Triton, and KFServing. These serving clusters leverage Alluxio to retrieve the models from the model storage repository. Once loaded, the serving clusters handle incoming queries, execute the necessary inference jobs, and return the computed results.
Both the training and serving environments are based on Kubernetes, which facilitates easier scalability and reproducibility of the infrastructure.
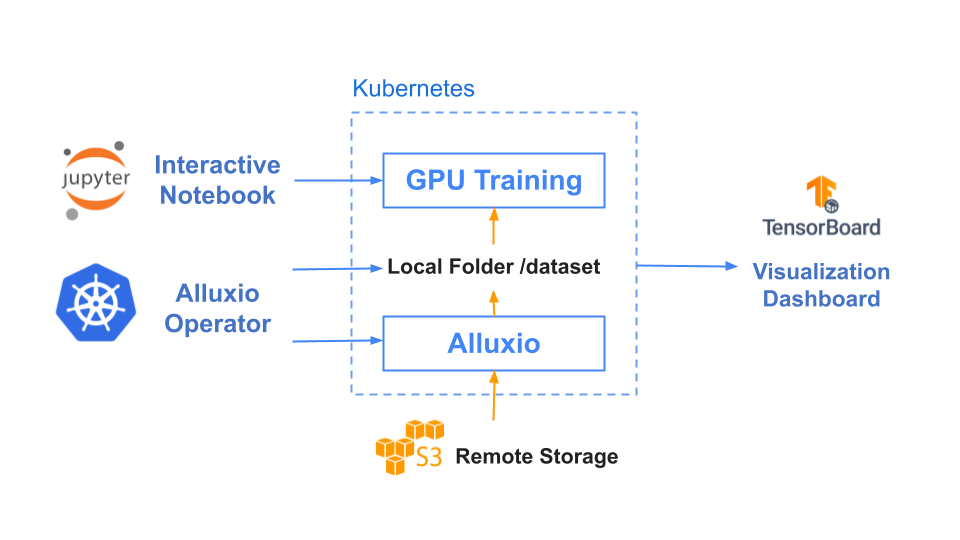
2. Benchmark Results
In the benchmark test, we employ ResNet in conjunction with the ImageNet dataset for image classification tasks, serving as an example use case in the computer vision domain.
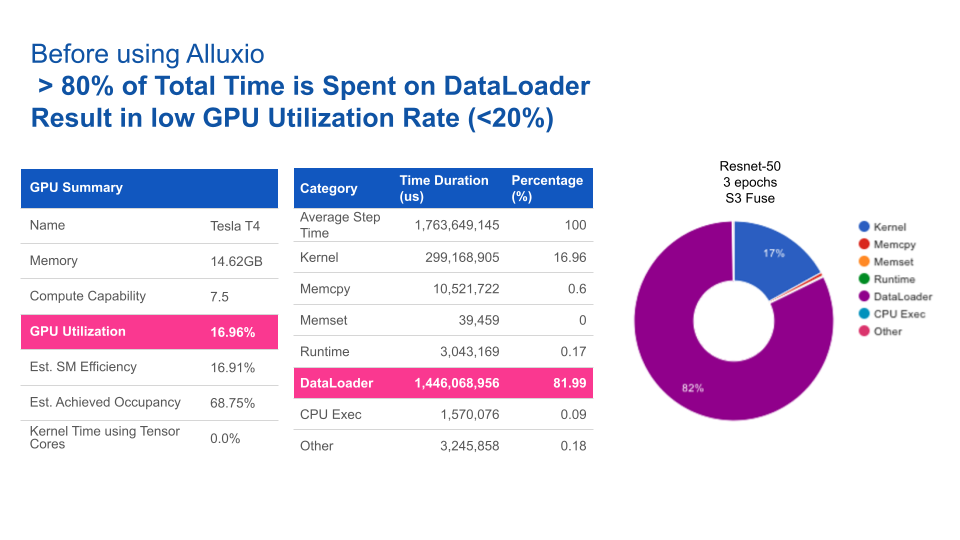
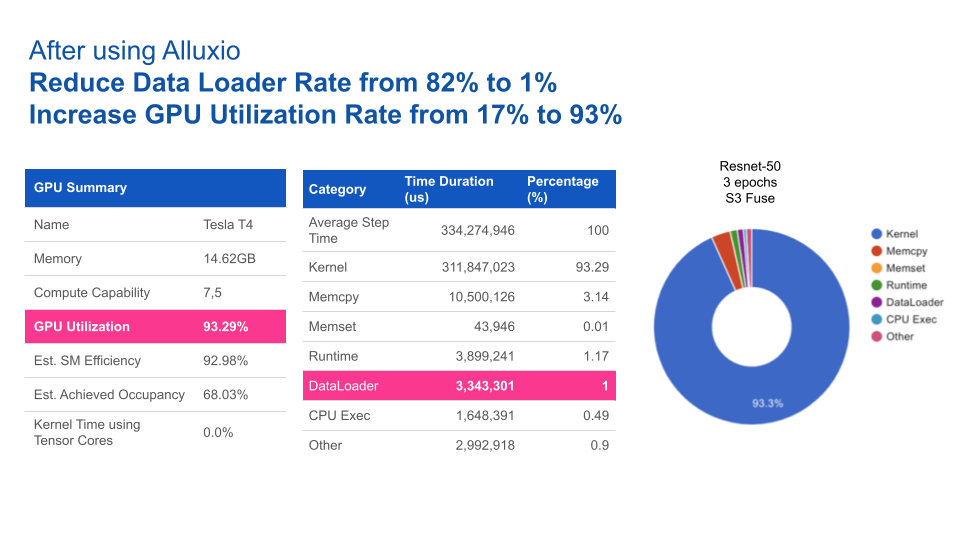
Based on the results performance benchmark, Alluxio is 8 times faster than S3-FUSE. In general, increased data access performance reduces the overall time for model training. See this demo video below, which shows how Alluxio Fuse can help you gain significant performance improvement for accessing remote data in S3 compared to S3FS Fuse.
GPU utilization has also been improved significantly after deploying Alluxio. Alluxio has reduced data loading time from 82% to 1%, resulting in GPU utilization increasing from 17% to 93%.
4. Conclusion
As AI/ML architectures evolve from early pre-production towards scaling out architecture, data access consistently surfaces as a bottleneck. Simply adding faster storage hardware or centralized NAS/NFS fails to fully eliminate the performance gaps and management burdens holding back operationalization.
Alluxio provides a software-based solution purpose-built to optimize data pipelines for AI/ML workloads. The benefits over traditional storage approaches include:
- Optimized Data Loading: Alluxio intelligently accelerates data access for both training workloads and model serving to maximize GPU utilization.
- Less Maintenance: No need for manual data copying between nodes or clusters. Alluxio handles propagating hot files across its distributed cache tier.
- Support for Scaling: Alluxio sustains performance as data requirements expand across more nodes. It serves files of any size by extending memory with SSD and avoiding duplicate full copies.
- Faster Switchovers: Alluxio abstracts the underlying storage topology, allowing teams to painlessly migrate data across vendors, on-prem, or multi-cloud. No invasive hardware replacements or downtime from data migrations.
With a data-centric architecture optimized for data access, organizations can finally build performant, scalable platforms ready to accelerate model development as data needs grow.
Talk to our expert if you encounter data access challenges while building your AI infrastructure. Book the consultation meeting now: https://calendly.com/alluxio-team.