This article shares the data platform practice at Expedia to federate cross-region data lakes spanning multiple geographic regions in the cloud.
1. Background
Expedia Group (NASDAQ: EXPE) is an American online travel shopping company for consumer and small business travel. Expedia powers travel for everyone, everywhere through our global platform, with industry-leading technology solutions to fuel partner growth and success while facilitating memorable experiences for travelers.

As the data platform team, we are tasked with developing a reliable, trustworthy, scalable data infrastructure that allows Expedia Group to make better business decisions and maintain a competitive advantage.
We build petabyte-scale data platforms used by different teams in the “brand world.” We manage data in the cloud and provide analytics platforms to data scientists and ETL developers around the world. To support the varying needs of our application teams, we leverage a number of open-source tools to build a data stack that offers customization, control and flexibility.
The top priority of our team is providing end-users with data availability, performance, consistency, stability, and reliability. As the business grows, data-driven applications keep expanding. We keep enhancing the tools and systems to meet the needs of our users, streamline operations, and be cost-effective at the same time.
2. Challenges
2.1 Data Silo Challenges
In the “brand world” of Expedia Group, we have a family of brands such as hotels.com, VRBO and other acquired brands that operate independently, creating data silos. With the rise of data-driven applications, the data platform needs to support applications that generate and consume data across geographical regions as well as across brands. That is why we are building a data platform that aims to break those silos.
To tackle the data silo challenge, we established a data lake on AWS, called the “main data lake” as the end-point for different teams to submit their analytics jobs, backed by data-processing engines like Trino/Spark/Hive and machine learning on Databricks.
Meanwhile, brands/teams run applications with their own AWS accounts in their local regions, which are where they started. These teams continue accessing legacy data outside of the main data lake, becoming silos.
To avoid creating new silos, we make sure that new data is only being produced in the same AWS region as the main data lake. However, when analytics need legacy brand data, we need to provide them with a way to access cross-region data lakes.
2.2 Previous Solution – Data Replication
Circus Train is an open source tool developed by Hotels.com for migrating and replicating very large Apache Hive datasets between clusters and clouds. The tool is used for enabling off-premises migrations, hybrid cloud architectures, and disaster recovery strategies.

Circus Train replicates Hive tables between clusters on request. It replicates both the table’s data and metadata. Unlike many other solutions, it has a light touch, requiring no direct integration with Hive’s core services. It can copy either entire unpartitioned tables or user-defined sets of partitions on partitioned tables.


The above diagrams show the architecture of the data replication with Circus Train. We have a main data lake in the us-east-1 region. Each brand/team has historical data in their own data lakes. New data is being ingested in us-east-1. We used Circus Train to replicate petabytes of data from various regions on a daily basis, between us-east-1 and us-west-2 so that we could share the data between teams. The data access pattern with Circus Train is as below.

We came across the following challenges with this data replication solution.
2.3 Issues with Data Replication
Poor Performance
Having a replica means data is not immediately available, and it is not easy to extract value from data at scale. Analytics teams had to wait for the validated data sets until they were ready for ongoing analytics. This can delay the availability of the data by a few hours or even a whole day, especially when the size of the table is at the TB level. Moreover, end-users are often unaware of the data readiness, resulting in poor user experience and complaints. The data unavailability will result in inconsistent results and significantly slow down the time to insight.
In addition, cross-region read performance is significantly slower than accessing the same region. Teams/brands accessing geographically distributed S3 buckets experience latency. End-users may need low latency data access for business-critical decisions, which cannot be met.
Error-Prone
Replication is error-prone, because data synchronization and validation are all manual. To minimize the risk of data loss and keep data integrity, we have to monitor to ensure the completion of the transfer continuously. Moreover, data validation is complex when multiple data sources are copied to the main data lake region. These have increased the management burden on the data platform team.
High S3 Egress Costs
Because data is located in various regions, we have to copy the entire tables to the main data lake in order to have the corresponding data available and up to date. Most of the data is in Hive format, which does not support update/merge methods. Therefore, when there is a restatement or historical backfill on the source, we have to copy the entire table over to the main data lake, especially when the data is very large (100+ TB). This is very costly and also delays the data availability SLA for end-users. Analytics teams constantly need to retrieve data across regions, resulting in high egress costs. This significantly increased long-term TCO with both operational costs and cloud service costs when using the data replication method.
We have figured out that using replication is not sustainable. As a result, we are forced to rethink a long-term solution to improving latency, reducing costs for cross-region data access of decentralized data lakes.
3. Solution – Cross-region Data Lake Federation
3.1 Solution Overview
A long-term solution for us should be a solution without data replication or, at least, avoid replicating data when it is not needed. We would like to have unified access to cross-region data.
Alluxio
We looked into a number of open source solutions and found that Alluxio can eliminate data replications for cross-geo data lakes. Alluxio provides abstraction to under storage and allows applications to run regardless of the location of data.
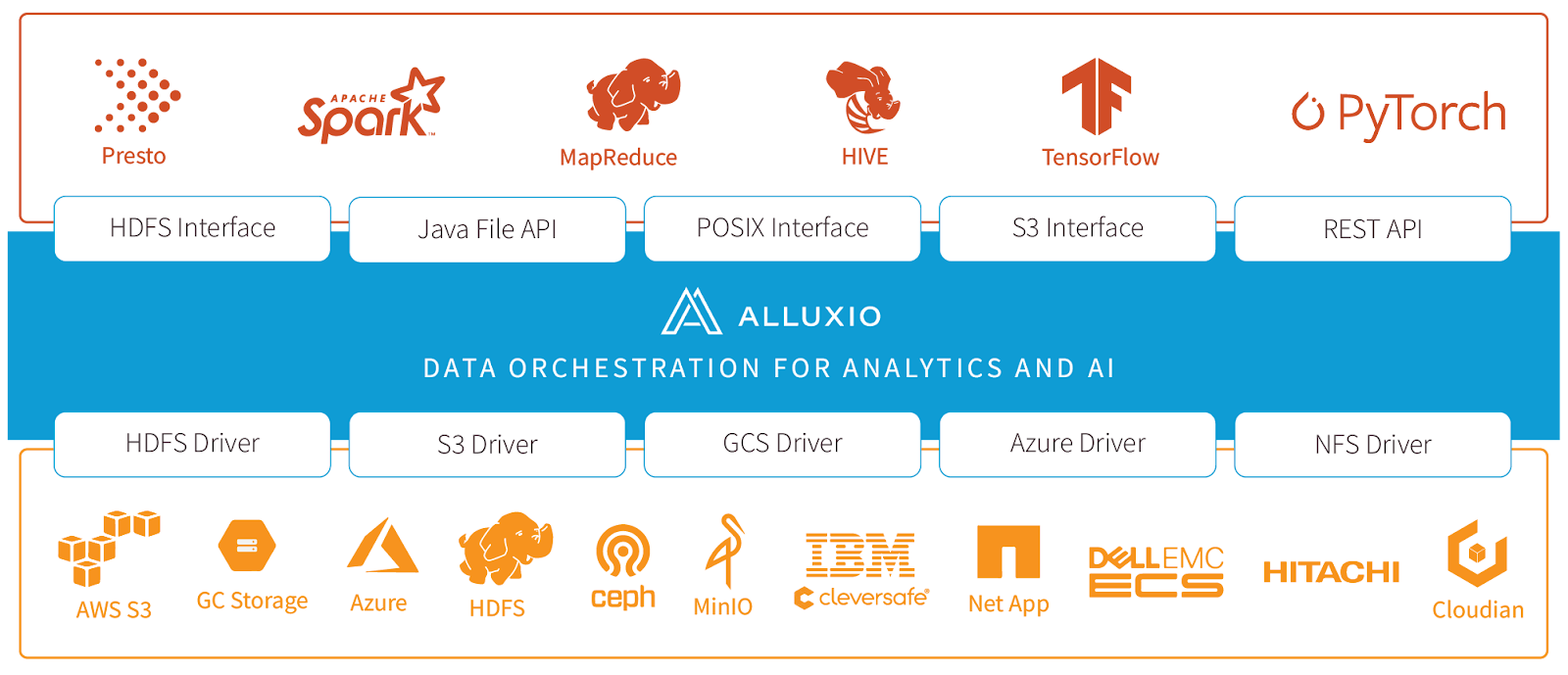
As you can see in the above diagram, Alluxio is a middle layer between compute engines and storage systems. It can serve data to any data-driven application (Spark, Hive, Trino) from underlying storage in any location, eliminating copies across multi-geo data lakes. By abstracting data lakes, the existing low performance, overheads, and S3 egress costs will be greatly reduced, which fits our needs.
Waggle Dance

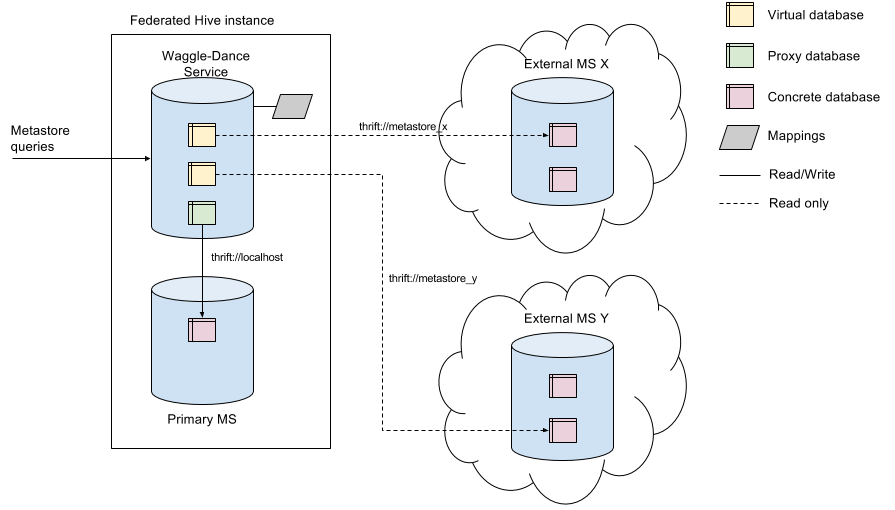
We also need to tailor the catalog and provide the Hive metastore with federation. We choose to use Waggle Dance, an open source tool which enables disparate tables to be concurrently accessed across multiple Hive deployments. At its core, Waggle Dance is a request routing proxy that allows datasets to be concurrently accessed across multiple Hive deployments. It was created to tackle the appearance of dataset silos that arose as our large organization gradually migrated from monolithic on-premises big data clusters to cloud-based platforms.
3.2 Architecture and Deployment
The diagram below depicts how Alluxio serves as an abstraction layer between compute and storage and achieves cross-region data access without data replication. As of now, we have deployed four Alluxio clusters in our environments, which run 60 nodes.
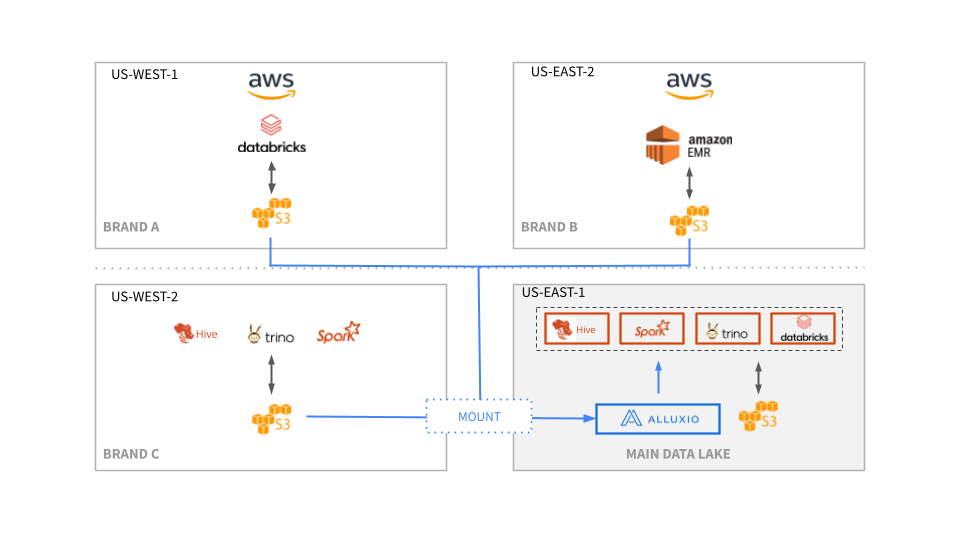
From the storage side, Alluxio provides a single global namespace, consolidating remote data lakes. All remote region data lakes are mounted to the Alluxio namespace, enabling on-demand access in AWS and eliminating the need to replicate data from multiple storage silos to the main data lake. Alluxio asynchronously fetches the metadata from other regions to make data available quickly.
For compute engines, we have integrated Alluxio with Qubole, Querybook, JupyterHub, Apache Hue, Databricks, Rstudio, etc., on our data platforms. Therefore, all of these compute engines only need to talk to Alluxio instead of fetching data from remote region data lakes. All of the data platforms are sharing data with Alluxio as a regional cache.
3.3 Integration
To ensure that cross-region data access is achieved by Alluxio, we have used Waggle Dance as a catalog service with metastore conversion.
The diagram below shows how the catalog works. If the table data is stored remotely, then Waggle Dance will convert the table path to Alluxio URI. SQL queries, performed by Hive, Spark, Trino or Databricks, all point to the same catalog pointing to designated locations. This significantly simplifies data access, and avoids direct access to cross-region S3, thus reducing S3 egress costs.

Using Alluxio as the cross-region federation layer, the new data access pattern looks like below.

4. Results
With the solution of federating cross-region data access, we have recognized the following benefits.
Greatly Enhanced Query Performance
Data is now immediately available to users without the need to wait for the long process of manual replication and data validation. (Note that, the very first time when data is accessed, it will take some time to cache the cross-region dataset into Alluxio). Performance is significantly increased because the latest data from different regions can be queried from the Alluxio namespace (with the latest version), and the hot working set will be cached. As a result, we are able to provide end-users with consistently high performance, leading to a shorter time to value.
Ease of Management
By integrating Alluxio, we can now combine data lakes from data in S3 in different regions without the need to manually replicate or move data anymore. Alluxio also simplifies the process of setting up fine-grained access controls at the cluster level. We no longer have to manage user-level authentication.
Significant Cost Savings
Alluxio minimizes network egress costs by caching data, eliminating the need to fetch data from cross-region data lakes repeatedly. The cost per query is significantly reduced. For frequently accessed tables, approximately 50% cost reduction is estimated. Also, our team’s operation cost is reduced when there is less manual management.
With the introduction of Alluxio, we are seeing better performance, increased manageability, and lowered costs. We plan to implement Alluxio as the default cross-region data access in all clusters in the main data lake.
5. Data Mesh Vision and Next Steps
Managing data platforms with modern architecture in the cloud is a long-running project. Our vision is to achieve data mesh. Data mesh is a decentralized approach to data management in which domain-specific teams manage data independently.
To achieve data mesh, we plan to adopt the domain-driven architecture in the main data lake. Our architecture will be decomposed by business domains, and each domain will have its own data lake on the same data platform, using separate AWS accounts. We will have the main data lake on top of the domain data lakes to handle federation and governance.
Having unified cross-region access paves the way for data mesh, making it easy to share data regardless of which teams produce and consume it, ensuring that they have the most comprehensive and up-to-date data. As a result, different brands are self-served and gain new capabilities to scale advanced data analytics and machine learning use cases.
To summarize, this blog talks about the challenges Expedia had in tackling data silos when managing data lakes for cross-region data applications. With a set of open source tools, we have supported a modern, scalable data platform in the cloud with better performance and lower costs.
References
- https://github.com/ExpediaGroup/waggle-dance
- https://github.com/ExpediaGroup/circus-train
- https://github.com/ExpediaGroup/apiary-data-lake
- https://github.com/ExpediaGroup/apiary-federation
- https://medium.com/hotels-com-technology/replicating-big-datasets-in-the-cloud-c0db388f6ba2
- https://martinfowler.com/articles/data-mesh-principles.html
About the Author
Jian Li, Senior Software Engineer at Expedia
Jian focuses on Data Lake / Data warehousing, cloud infrastructure, distributed ecosystem, also interested in CI/CD and automation solutions.