This article introduces how to read and write Delta lake tables on Alluxio. You can build multi-cloud data lake using Delta Lake and Alluxio, reducing your data storage costs and increasing flexibility
1. Overview
1.1 About Delta Lake
Delta Lake is an open source storage framework that enables building a Lakehouse architecture and brings reliability to data lakes. Delta Lake provides multiple features such as ACID properties, time travel, and efficient metadata operation for large table format datasets to build the Lakehouse. Delta Lake runs on top of the existing data lake and is compatible with Apache Spark APIs.
As mentioned above, Delta Lake offers multiple features:
- Time travel: Delta Lake can roll back user data and have full historical audit trails.
- ACID transaction: Delta Lake ensures the consistency of the data written to storage and committed for users. Users will see consistent data all the time.
- Scalable metadata handling: Delta Lake uses Spark to scale the petabytes, which can easily process all metadata for petabyte-scale tables with billions of files.
- Efficient and batch unification: Delta Lake improves performance by having streaming jobs write small objects to tables with low latency and then transactionally merge them into larger objects. Delta Lake also provides streaming data ingest, batch historic backfill and interactive queries.
- Schema enforcement and schema evolution: Schema changes are automatically handled to prevent the insertion of bad records during ingestion. Furthermore, Delta Lake allows you to continue reading old Parquet files without rewriting them if the table’s schema changes.
- Support MERGE, DELETE and UPDATE operations: Delta Lake supports these operations to help complex use cases like streaming upserts.
- Caching: Objects in the Delta table and its log are unchangeable and can safely cache them on local storage.
1.2 About Alluxio
Alluxio is a new data layer between storage and compute engines for a variety of data-driven applications, such as large-scale analytics and machine learning.

Alluxio completely virtualizes all data sources, breaks down data silos, and enables all data-driven applications to access data regardless of where the data is sitting. The solution is environment agnostic, whether in the cloud or on-premises, bare metal, or containerized.
1.3 Why Delta Lake + Alluxio
Delta Lake can run on top of Alluxio, which acts as a virtual unification layer across all the data lakes, serving a wide range of analytics and AI applications, including Spark, Presto, Trino, and more. The below diagram shows how Alluxio fits into the Lakehouse stack.
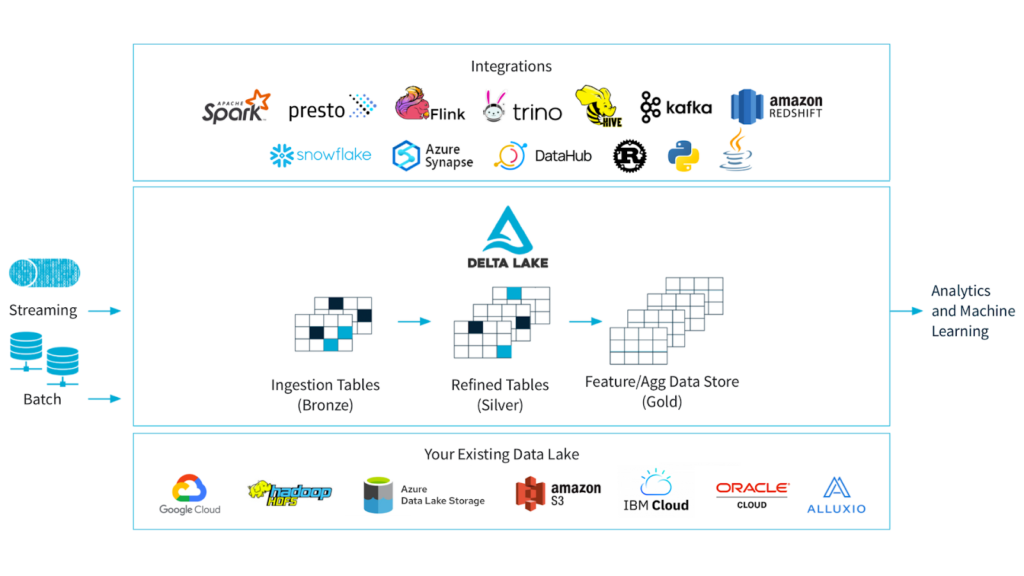
Delta Lake and Alluxio bring together two benefits.
Alluxio serves as the cache to accelerate the I/O for data-driven applications using Delta Lake. Alluxio can be co-located with computing engines, such as Spark, Presto, or Trino to accelerate reading and writing on the data lakes.
Alluxio provides a Lakehouse with multi-cloud capabilities. Delta tables can be cached distributedly in Alluxio for availability and performance, and are portable across any environment. Using Alluxio and Delta Lake together, organizations can create a multi-cloud data lake that serves as a consolidated source of truth across multiple clouds.
2. How to Deploy Delta Lake on Alluxio
This section explains how to quickly start reading and writing Delta tables on Alluxio.
2.1 Prerequisites
- Download and install Apache Spark
- Download and install Alluxio. For more detail about how to set up Alluxio, click here.
- Set up Apache Spark and Alluxio to allow Spark to run on Alluxio. The below steps are just for this quick-start tutorial. Please check here for more detail about running Spark on Alluxio.
- Make sure there is a jar file named
alluxio-2.8.1-client.jarunder the/<PATH_TO_ALLUXIO>/client - The Alluxio client jar must be in the classpath of all Spark drivers and executors for Spark applications to access Alluxio. Add the following line to
/<PATH_TO_SPARK>/conf/spark-defaults.confon every node running Spark. Also, ensure the client jar is copied to every node running Spark.
- Make sure there is a jar file named
/**
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.8.1-client.jar
**/- Please add the following content to
${SPARK_HOME}/conf/core-site.xml:
/**
<configuration>
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.alluxio.impl</name>
<value>alluxio.hadoop.AlluxioFileSystem</value>
</property>
</configuration>
**/2.2 Set up alluxio and create a directory
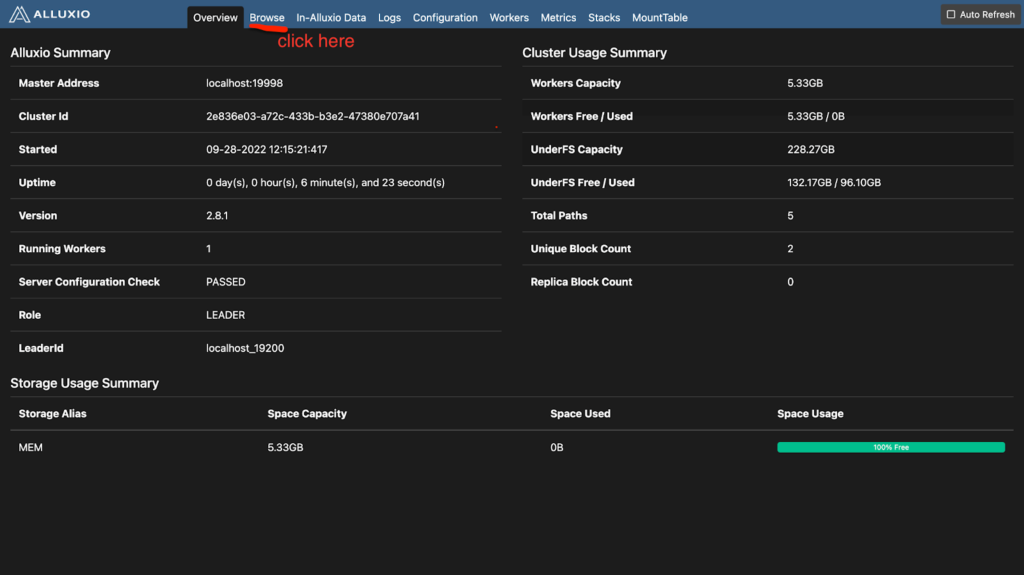
- Start Alluxio on the terminal. Click here for more detail about how to start Alluxio.
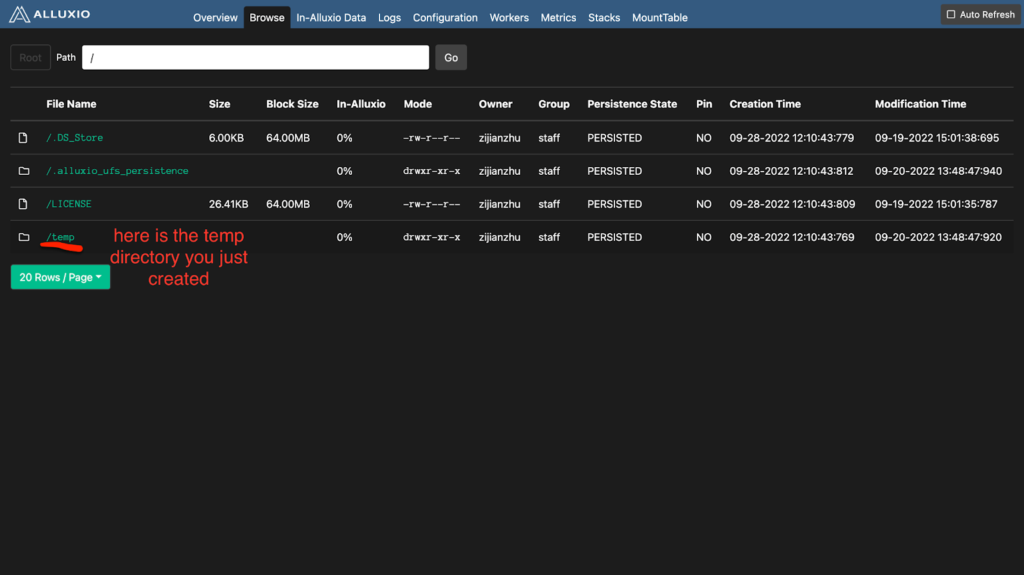
- Use the Alluxio shell to create a directory name temp.
/**
./bin/alluxio fs mkdir /temp
**/You should receive this output Successfully created directory /temp on your terminal. You can also go to the http://localhost:19999 and click Browse to see the /temp directory.
2.3 Set up Apache Spark with Delta Lake
- Open your terminal
- Go to Apache Spark directory
- Start the Spark shell (Scala or Python) with Delta Lake and run code snippets interactively.
- In scala
/**
bin/spark-shell --packages io.delta:delta-core_2.12:2.1.0 --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" --conf "spark.driver.extraClassPath=/Users/zijianzhu/Desktop/alluxio/client/alluxio-2.8.1-client.jar" --conf "spark.executor.extraClassPath=/Users/zijianzhu/Desktop/alluxio/client/alluxio-2.8.1-client.jar"
**/You should get this output after you input the above script in the terminal.
2.4 Create a test Delta Lake table on Alluxio
- Try it out and create a simple Delta lake table using scala:
/**
// create a delta table on Alluxio
spark.range(5).write.format("delta").save("alluxio://localhost:19998/temp")
**/You will see some output indicating that Spark wrote the table successfully.
- You can see the Delta Lake table using Alluxio shell
/**
$./bin/alluxio fs ls /temp
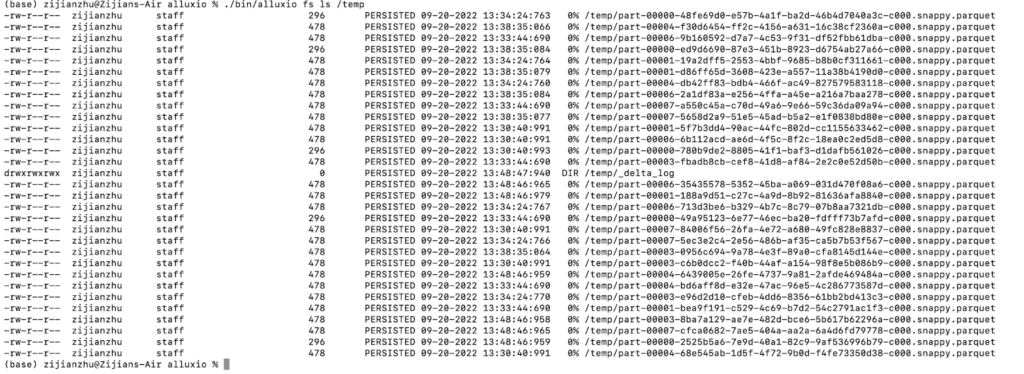
**/The terminal will give an output of the Delta lake table in the /temp directory
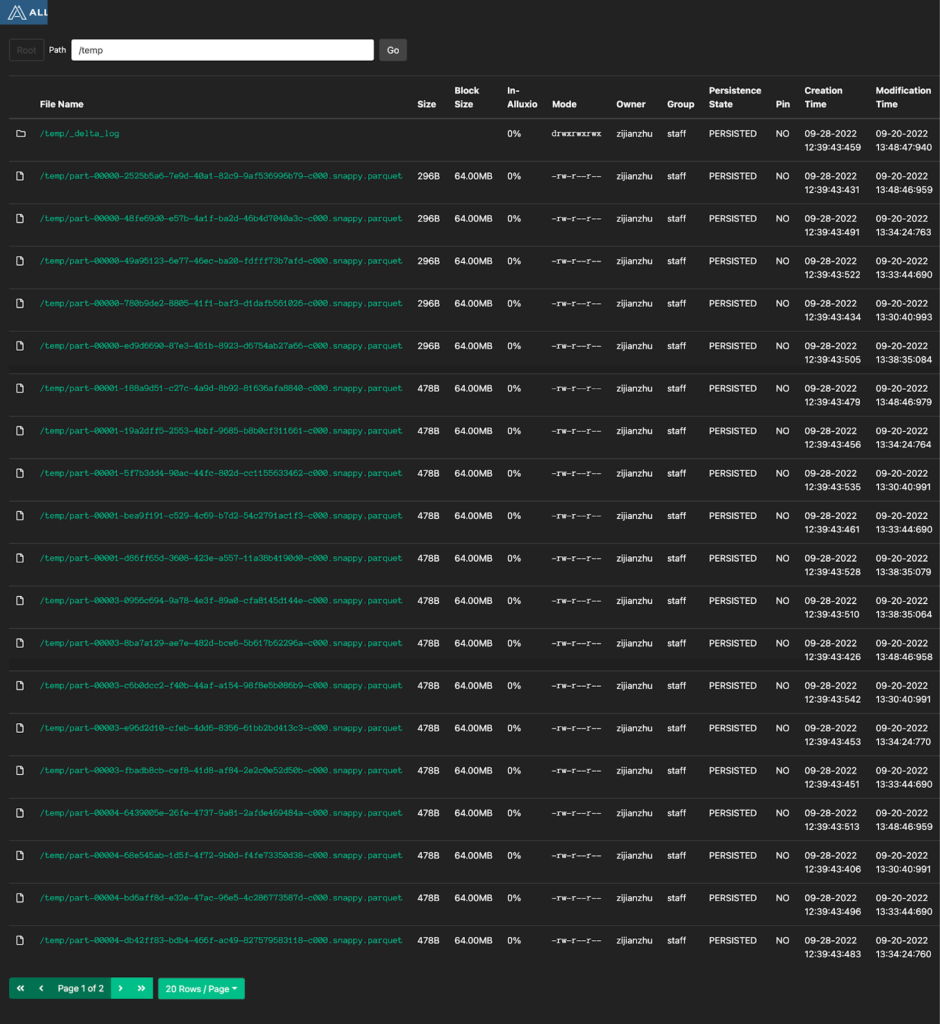
You can also go to the http://localhost:19999 on your browser to see the Delta lake table in the /temp directory
3. What is Next?
Want to learn more? Join 9800+ members in our community slack channel to ask questions and provide your feedback.