Get the latest and greatest tips to accelerate your PyTorch model training for machine learning and deep learning.

PyTorch, an open-source machine learning framework, has become the de facto choice for many organizations to develop and deploy deep learning models.
Model training is the most compute-intensive phase of the machine learning pipeline. It requires continuous performance optimization. It can be challenging and time-consuming to fine-tune the training performance because many factors, such as I/O, data operations, GPU, and CPU processing, can make training slow.
In this blog, you will learn seven tuning tips to accelerate PyTorch model training. These tips can be implemented by changing only a few lines of code and can be applied to o various model types (CNNs, RNNs, GANs, Transformers) and domains (CV, NLP).
Tip 1: Identify Bottlenecks Using Monitoring Tools
The bottleneck can vary depending on several factors, such as the size of the dataset, the complexity of the model, and the hardware that is being used. By identifying the bottleneck, you can focus your optimization efforts on the areas with the biggest impact on performance.
For example, if the dataset is large, the bottleneck may be the data loading step. The bottleneck may be the model training step if the model is very complex. In PyTorch, the bottleneck can also vary depending on the specific code used. For example, if the code is not using GPU acceleration, the bottleneck may be the CPU. However, if the code uses GPU acceleration, the bottleneck may be the GPU memory or the bandwidth between the CPU and the GPU.
Here is a list of the most commonly used command-line tools for monitoring resource usage:
- nvidia-smi: This tool provides information about GPU utilization, memory usage, and other metrics related to the NVIDIA GPU.
- htop: It is a command-line tool that hierarchically displays system processes and provides insights into CPU and memory usage.
- iotop: With this tool, you can monitor I/O usage by displaying I/O statistics of processes running on your system.
- gpustat: It is a Python-based user-friendly command-line tool for monitoring NVIDIA GPU status.
- nvtop: Similar to nvidia-smi, nvtop displays real-time GPU usage and other metrics in a user-friendly interface.
- py-spy: It is a sampling profiler for Python that helps identify performance bottlenecks in your code.
- strace: This tool allows you to trace system calls made by a program, providing insights into its behavior and resource usage.
Besides these command-line tools, TensorBoard is a visualization tool that can monitor PyTorch training and identify bottlenecks. It is easy to use and can be accessed from any web browser. TensorBoard can monitor various metrics, including data loading time, memory copy time, CPU usage, and GPU usage. You will get the monitoring results from TensorBoard like below.
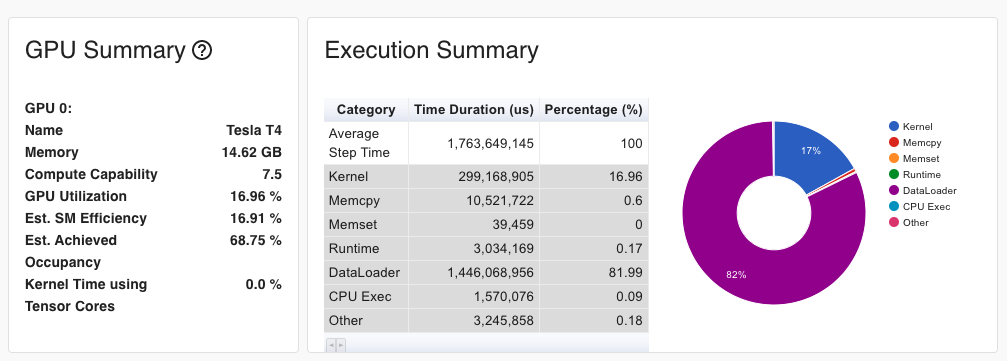
Tip 2: Follow A Systematic Tuning Process
Here is a process for tuning PyTorch training based on key metrics such as GPU utilization, CPU execution, data loader time, and memory copy (memcpy). This flow is presented in a decision tree:
- Start
- Is Data Loader Time High?
- If Yes:
- Copy data to local NVMe (SSD)
- Use Alluxio as the data access layer
- Enable asynchronous data loading
- If No:
- Continue to the next step.
- If Yes:
- Is MemCpy High?
- If Yes:
- Create the Tensors at the right device
- Use torch.as_tensor
- Set non_blocking to True
- If No:
- Continue to the next step.
- If Yes:
- Is GPU Utilization High?
- If Yes:
- Choose a better GPU
- Compile your model (PyTorch 2.0 feature)
- Use DistributedDataParallel
- Use lower precision data types
- If Yes:
- If No:
- Continue to the next step.
- Is CPU Execution High?
- If Yes:
- Use a more efficient file format for structural data
- Enable SIMD
- Use a more efficient memory allocator
- If No:
- Continue to the next step.
- If Yes:
- Other Metrics or Bottlenecks
- If there are other specific metrics or identified bottlenecks affecting performance, address them accordingly. Some potential steps include:
- Optimize network architecture or model complexity
- Apply regularization techniques (e.g., dropout, weight decay) to improve generalization
- Adjust learning rate and optimizer settings
- Profile and optimize critical sections of the code
- If there are other specific metrics or identified bottlenecks affecting performance, address them accordingly. Some potential steps include:
- Monitor and Re-evaluate
- After applying these optimizations, monitor the metrics again to evaluate the impact of the changes
- Iterate and re-evaluate the optimizations as necessary
- Finalize and Evaluate
- After tuning and monitoring, evaluate the overall performance
- Consider factors such as training speed, convergence, and GPU utilization
- Analyze the trade-offs between performance, accuracy, and resource constraints
- End
This tuning process provides a structured approach to address performance bottlenecks in PyTorch based on key metrics. By following this decision tree, you can systematically identify the relevant bottlenecks and apply appropriate optimization techniques to improve the efficiency and performance of your PyTorch training pipeline.

Tip 3: Optimize I/O Performance
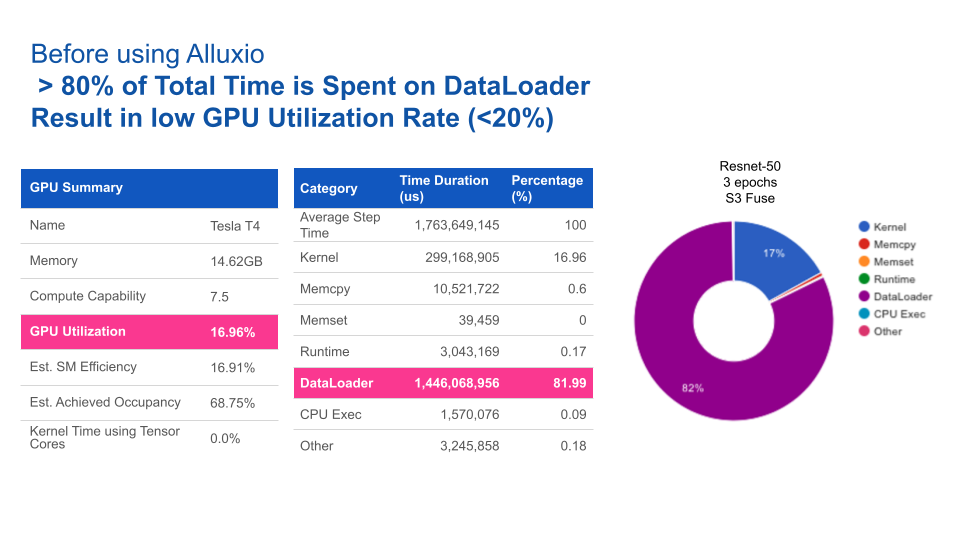
I/O is a major bottleneck in slowing the training process because data must be loaded from storage to GPU for processing. This process can be very time-consuming, especially when your datasets are large or remote. In our experience working with top tech companies, such as Uber, Shopee, and AliPay, data loading can account for nearly 80% of end-to-end training time. You can typically see performance improvements up to 10x by just optimizing I/O.
Moreover, slow I/O leads to underutilized GPUs. Given the scarcity and high cost of GPUs, you want to fully utilize them during training. You need to ensure that the data is fed to the GPU at the rate that matches its computations. If I/O is slow, the GPUs remain idle until the data is ready, wasting expensive resources. We typically observe GPU utilization of less than 50% because of slow I/O.
There are three common ways to optimize I/O:
- Copy your data to a faster local storage device before loading, such as a solid-state drive (SSD).
- Deploy a high-performance data access layer, such as Alluxio, between compute engine and your storage.
- Parallelize the data loading process, such as using multiple PyTorch workers to load the data.
Let’s take a look at how a high-performance data access layer can help:
- Automatically load / unload / update data from your existing data lake.
- Faster access to training data with optimized I/O.
- Increase the productivity of the data engineering team by eliminating the need to manage data copies.
- Reduce cloud storage API and egress costs, such as the cost of S3 GET requests, data transfer costs, etc.
- Maintain an optimal I/O with high data throughput to keep the GPU fully utilized.
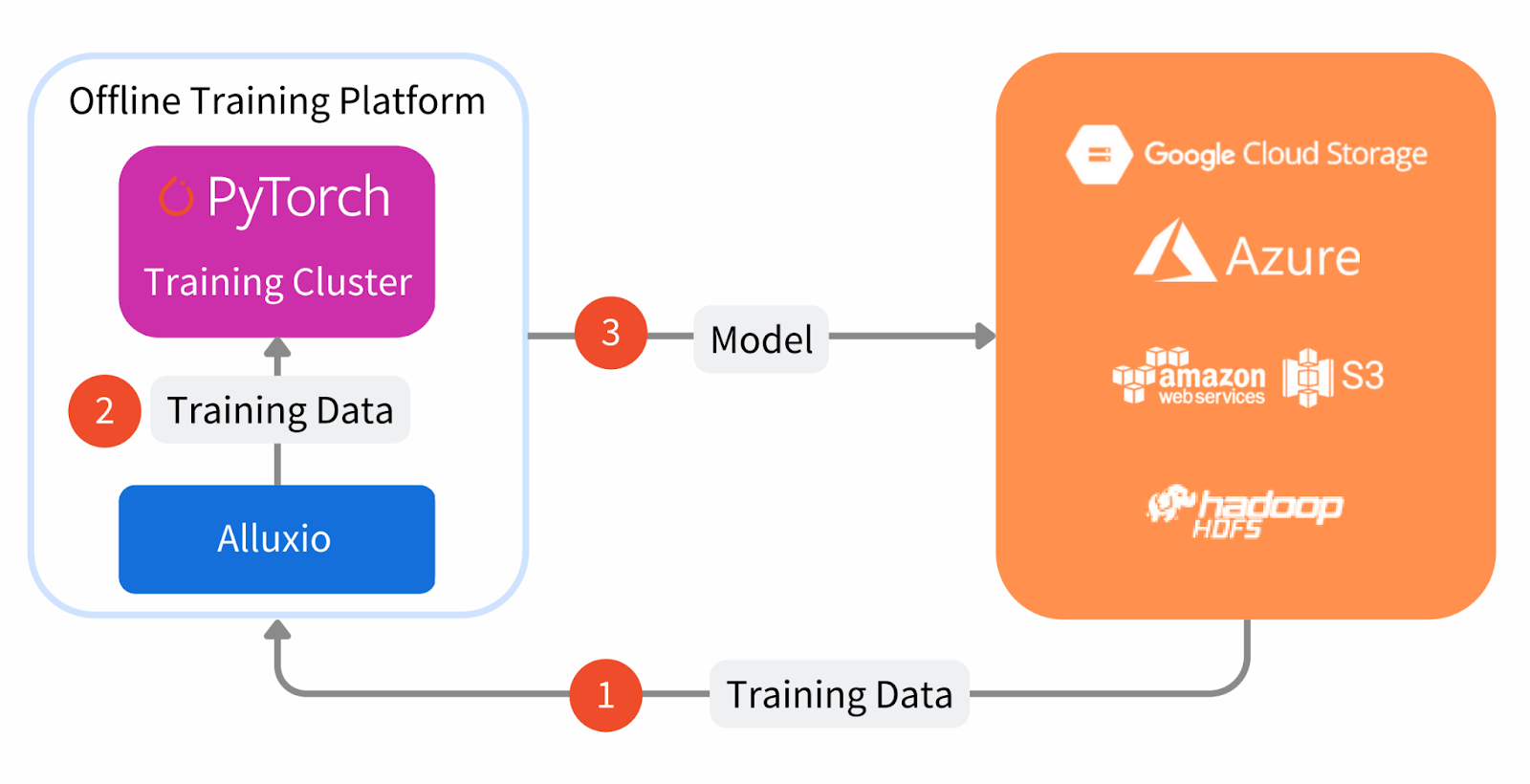
Below is an architecture diagram of Alluxio with PyTorch. You can deploy Alluxio co-located with the training cluster for maximum performance. Alluxio’s distributed caching leverages the local NVMe (SSD) disk to cache remote data to overcome the I/O bottleneck.
Below are the results from the experiment on ResNet50 (in comparison to S3-fuse).

Tip 4: Data Operations Optimization
We highly recommend directly creating tensors on the device where you intend to perform operations. Consider the code below, where a tensor is initially created in CPU memory and then moved to GPU memory. This approach typically involves allocating CPU RAM and using the cudaMemcpy function to transfer data between the GPU and CPU.
We also recommend using torch.as_tensor() provides several benefits. Unlike torch.tensor(), it avoids unnecessary data copying. It converts data into a tensor while sharing the underlying data and preserving the autograd history, if possible. torch.as_tensor() efficiently converts data into a tensor, allowing for memory sharing and preserving the autograd history. It provides a faster alternative to torch.tensor() when working with NumPy arrays. By using torch.as_tensor(), unnecessary data copying can be avoided, resulting in improved performance and efficient tensor creation.
Another tip in data operations is to set non_blocking to True. Using non_blocking=True is particularly beneficial when there is a need for overlapping data transfer and computation. It helps to avoid unnecessary synchronization between CPU and GPU, improving the overall performance and efficiency of PyTorch computations.

Get the code snippets of the above optimizations: PyTorch Model Training Performance Tuning: A Comprehensive Guide.
Tip 5: How to Choose the Right GPU
The choice of GPU is crucial to the quality of your deep learning experience. Here are some tips for selecting the most suitable GPUs for your needs:
- Compute Capability and Memory: Take into account the compute capability and memory capacity of the GPUs. Higher compute capabilities enable advanced deep learning features and algorithms, while larger memory capacities handle bigger models and datasets. Ensure that the chosen GPUs meet the requirements of your deep learning tasks.
- Performance vs. Cost: Assess the performance-to-cost ratio of the GPUs. Seek GPUs that strike a balance between performance and cost based on your budget and specific deep learning requirements. Factors such as the number of CUDA cores, memory bandwidth, and pricing should be considered to make an informed decision.
- Compatibility with Deep Learning Frameworks: Verify that the chosen GPUs are compatible with popular deep learning frameworks like PyTorch or TensorFlow. Consult the frameworks’ documentation or official resources for a list of supported GPUs and recommended configurations.
Here is a diagram illustrating the compute capabilities of different GPU models.

To accelerate PyTorch code with the greatest speedup, you should consider modern NVIDIA GPUs such as A100, H100, and V100. These GPUs offer exceptional performance, particularly for the “torch.compile” feature we will discuss in the upcoming section.
Tip 6: Use DistributedDataParallel (DDP)
Using DistributedDataParallel (DDP) in PyTorch enables distributed training across multiple GPUs or machines, significantly boosting compute power and reducing training time. When your model exceeds the capacity of a single GPU, DDP becomes essential.
For basic use cases, DDP only requires a few more codes to set up the process group. Compared with the well-known DataParallel, the pros of using DDP are:
- Model is replicated only once
- Supports scaling to multiple machines
- Faster because it uses multiprocessing
Overall, DistributedDataParallel (DDP) in PyTorch provides efficient multi-GPU training, improved scalability, and a simplified implementation process. However, it also introduces communication overhead, increased memory consumption, complex debugging scenarios, and dependencies on hardware and network configurations. Carefully consider these factors when deciding to use DDP for distributed training in PyTorch.
Tip 7: Use More Efficient File Format For Structural Data
Parquet and Arrow are complementary technologies with different design tradeoffs. Parquet is a storage format focused on maximizing space efficiency, while Arrow is an in-memory format optimized for vectorized computational kernels.
The main distinction between the two is that Arrow enables O(1) random access lookups to any array index, whereas Parquet does not. Parquet achieves space efficiency through techniques like dremel record shredding, variable length encoding schemes, and block compression. However, these techniques come at the cost of performant random access lookups.
A common approach that leverages both technologies’ strengths is to stream data in thousand-row batches from a compressed representation like Parquet into the Arrow format. These batches can then be processed individually, allowing for efficient computations on the Arrow data while managing memory requirements. The results can be accumulated in a more compressed representation. This approach ensures that the computation kernels are agnostic to the encodings of the source and destination data.
Based on the identified bottleneck in tip 1, if the CPU is the bottleneck, it is recommended to use Arrow to save CPU resources. Arrow’s efficient computation capabilities make it a suitable choice in this scenario. On the other hand, if the bottleneck is I/O, using Parquet can help reduce the number of bytes loaded from the disk or transmitted over the network, optimizing I/O performance.
Want to Learn More?
For more detailed tuning tips with code snippets and real-world use cases, download the eBook: PyTorch Model Training Performance Tuning: A Comprehensive Guide.