Presto is an open-source distributed SQL engine widely recognized for its low-latency queries, high concurrency, and native ability to query multiple data sources. Alluxio is an open-source distributed file system that provides a unified data access layer at in-memory speed.
The combination of Presto and Alluxio is getting more popular in many companies like JD, NetEase to leverage Alluxio as distributed caching tier on top of slow or remote storage for the hot data to query, avoiding reading data repeatedly from the cloud. In general, Presto doesn’t include a distributed caching tier and Alluxio enables caching of files and objects that the Presto query engine needs.
A Note on Data Locality for Caching data for presto
When Presto is reading from a remote data source (e.g., AWS S3), by default, its task scheduling will not take data locations into account since the data source is remote anyway. However, when Presto is running on collocated Alluxio service, it is possible that Alluxio can cache the input data local to Presto workers and serve it at memory-speed for the next retrieve.
In this case, Presto can leverage Alluxio to read from the local Alluxio worker storage (termed as short-circuit read) without any additional network transfer. As a result, to maximize input throughput, users should make sure task locality and Alluxio short circuit read are achieved.
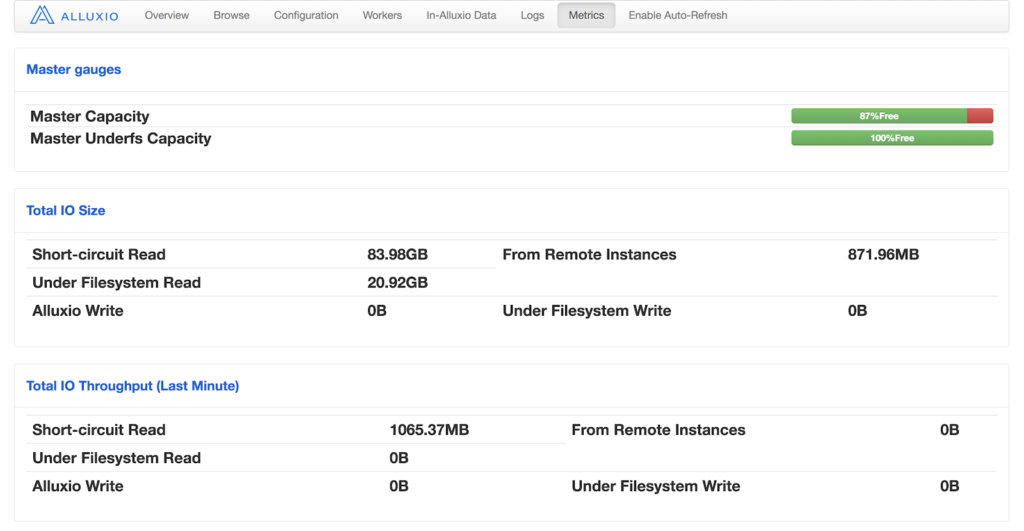
To check whether locality and short circuit read work as expected, one can monitor Short-circuit Read and From Remote Instances in Alluxio metrics UI page:
If the percentage of short circuit reads is low, then use dstat to monitor network traffic pattern on Alluxio workers.
1. Locality-aware Scheduling
For Presto to leverage data locality, one can enable locality-aware scheduling so the Presto coordinator can schedule tasks on Presto workers with splits or blocks cached locally. Set node-scheduler.network-topology=flat in config.properties and set hive.force-local-scheduling=true in catalog/hive.properties if you are using hive connector to read from Alluxio.
2. Ensure Hostname Matching
The locality-aware task scheduling is based on the string matching between the Alluxio worker addresses of file blocks and Presto worker addresses. Even when Presto workers and Alluxio workers are collocated, if you specify Presto workers in IP addresses while Alluxio workers in machine hostnames, the addresses will not match. To avoid this, configure alluxio.worker.hostname and alluxio.user.hostname properties to match the hostname of Presto worker addresses. Set these properties in alluxio-site.properties, and specify its path in -Xbootclasspath/p:<path to alluxio-site.properties> in Presto’s etc/jvm.config.
Balance I/O and CPU with Higher Parallelism
With locality-aware scheduling enabled and once input data is already cached in Alluxio, Presto can read directly and efficiently from local Alluxio storage (e.g., Ramdisk up to Alluxio worker configuration). In this case, the performance bottleneck for a query may shift from I/O bandwidth to CPU resource. Check CPU usage on Presto workers: if their CPUs are not fully saturated, it might indicate the number of Presto worker threads can be higher, or the number of splits in a batch is not large enough.
3. More worker Threads
One can tune the number of worker threads by setting task.max-worker-threads in config.properties, typically the number of CPU cores multiplied by the hyper-threads per core on a Presto worker node. You may also need to tune task.concurrency to adjust the local concurrency for certain parallel operators such as joins and aggregations.
4. Number of Splits in a Batch
Presto schedules and assigns splits into batches periodically. The pause of scheduling between each batch of splits wastes CPU cycles that can be used for query processing. Splits can be in two states: “pending” and “running”. When a split is assigned to a Presto worker, it is in the pending state, then when it starts to be processed by a Presto worker thread and transitioning to the running state.
Property node-scheduler.max-splits-per-node controls the limit of the total number of pending and running splits on a Presto node, while node-scheduler.max-pending-splits-per-taskcontrols the number of pending splits. Increase the value of these two properties to prevent thread starvation of Presto worker and reduce scheduling overhead. Note that, if the values of these two properties are too high, splits may be assigned to only a small subset of workers causing imbalanced load across all workers.
Others
5. Prevent Alluxio Client Timeout
Under I/O intensive workloads bottlenecked by network bandwidth, one may encounter exceptions caused by a Netty timeout in Alluxio 1.8 like
Caused by: alluxio.exception.status.DeadlineExceededException: Timeout to read 158007820288 from [id: 0x73ce9e77, /10.11.29.28:59071 => /10.11.29.28:29999].
at alluxio.client.block.stream.NettyPacketReader.readPacket(NettyPacketReader.java:156)
at alluxio.client.block.stream.BlockInStream.positionedRead(BlockInStream.java:210)
at alluxio.client.file.FileInStream.positionedReadInternal(FileInStream.java:284)
at alluxio.client.file.FileInStream.positionedRead(FileInStream.java:254)
at alluxio.hadoop.HdfsFileInputStream.read(HdfsFileInputStream.java:142)
at alluxio.hadoop.HdfsFileInputStream.readFully(HdfsFileInputStream.java:158)
at org.apache.hadoop.fs.FSDataInputStream.readFully(FSDataInputStream.java:107)
at com.facebook.presto.hive.orc.HdfsOrcDataSource.readInternal(HdfsOrcDataSource.java:63)
This is because the Alluxio client inside Presto is unable to fetch data from Alluxio workers before the predefined timeout value. In this case, one can increase alluxio.user.network.netty.timeout to a larger value (e.g., 10min).
Conclusion
Through this article, we summarized the performance tuning tips to run the stack of Presto and Alluxio. We found achieving high data locality and sufficient parallelism is the key to get the best performance. If you are interested to speed up slow I/O in your Presto workloads, you can follow this documentation and try it out!