Today I’m thrilled to announce the strategic OEM partnership with Starburst Data, the company behind Presto, the fastest growing SQL query engine in a disaggregated world. Through this partnership, Starburst Data will be offering a bundled solution that will bring our two open source technologies together and provide exceptional performance and multi-cloud capabilities for interactive analytic workloads. But before I get to the details of the Alluxio + Starburst solution, let’s take a step back and see why these technologies themselves are foundational elements of a modern data stack.
Let’s travel back 45 years to 1974, System R was being built at the IBM lab – the first implementation of a SEQUEL (Structured English Query Language) now known as SQL. The architecture included a parser, compiler, basic optimizer, system buffer pool and RSS – research storage system. Overtime this stack came to be known as the relational database.

While a lot has changed in the data world since 1974, from systems becoming more distributed to hardware becoming a gazillion times faster and a ton more data needing to be managed, the core concepts designed to manage data really haven’t. Historically databases were tightly integrated with all core components built together. Hadoop changed that. Compute and storage were still co-located but the entire system was highly distributed instead of being in a single or a few boxes.
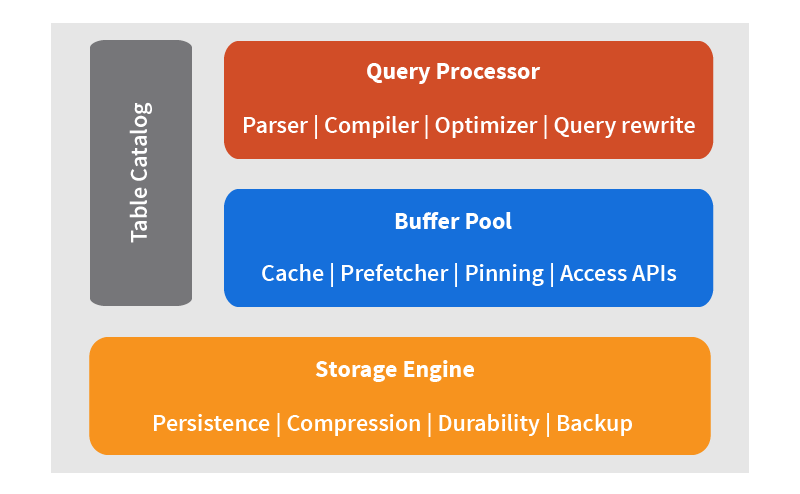
Cloud changed that. Today, the data stack that the most innovative companies like Uber, Twitter, JD.com and others are building is a fully disaggregated stack. Each core element of the original relational database management system is now a standalone layer. Storage engine options range widely from HDFS to cloud object stores to on premises object stores. Table catalog choices range from Hive Metastore on premises to AWS Glue on AWS. More will emerge. For the buffer pool increasingly called data orchestration, Alluxio is the primary contender and for the query engine Presto is the fastest growing option.
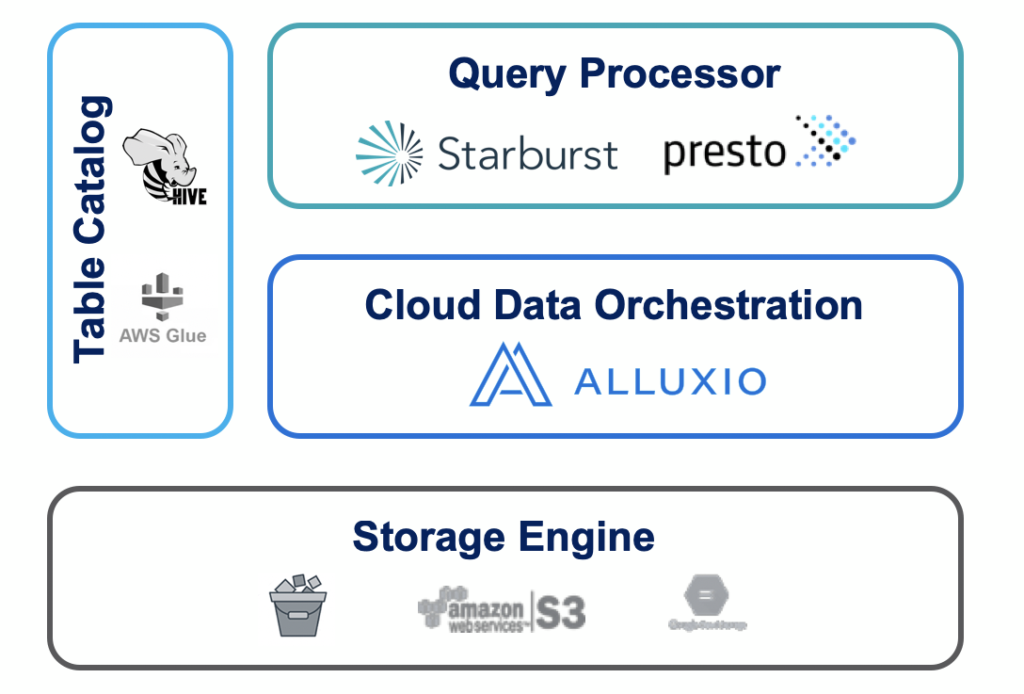
Separate layers of compute, data orchestration and storage
that scale horizontally & leverage cloud
This brings me back to what I am excited about: the Starburst Data and Alluxio partnership. Alluxio’s data orchestration layer when deployed with Presto, optimizes the stack with tighter data locality on a per worker basis. To start with, users can use Alluxio for Presto caching. This means that the compute drives the data needs to be pulled from the underlying data silos and storage systems. Data gets stored into the buffer based on query behaviors which in turn means end user behavior which in turn means the hottest data. I/O is offloaded from the underlying slow storage system to a very fast data access layer in Alluxio.
To expand beyond presto caching, users can leverage data orchestration to move data from anywhere (on premises, across data centers, from cloud object store) closer to the query processing tier. Technically, this isn’t restricted to query engines, the compute could be ETL frameworks or Python-based machine learning frameworks to deep learning frameworks like Tensorflow.
Starburst + Alluxio = better together
Starburst Presto with Alluxio is a truly separated stack, enabling interactive big data analytics on any file or object store. Together, Starburst Presto and Alluxio helps jobs run up to 10x faster, makes important data local, and connects to a variety of storage systems and clouds.
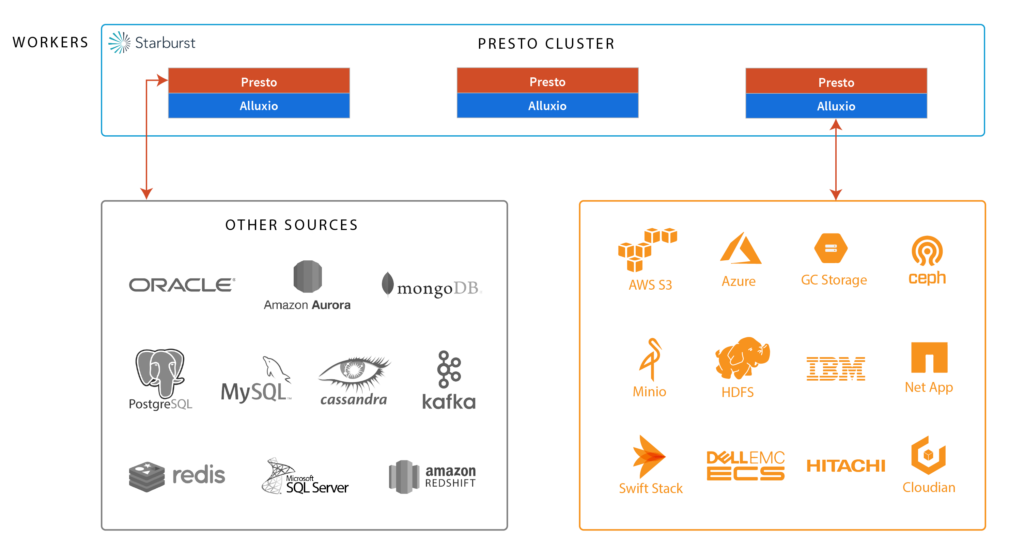
With this partnership, users can directly buy Alluxio from Starburst Data. This even includes support. We’re excited to bring this partnership to our communities and look forward to seeing what you do! And we certainly hope you are excited too!
Users can now transform their legacy data warehouse approach to build adopt a modern cloud data stack, with a truly disaggregated data stack built on Presto, Alluxio and any file or object storage. Today it’s data orchestration bundled with Presto, tomorrow it will be data orchestration bundled yet another framework. Data orchestration has only just begun!
More resources
Webpage: Starburst Data and Alluxio
Webpage: Interactive Analytics with Presto and Alluxio
Announcement Press Release
Presto + Alluxio Datasheet
Contact us for more information