Reduce HDFS Latency with Alluxio Managed SSD Cache and Presto Consistent Hashing-Based Soft Affinity Scheduling
This article shares how Uber and Alluxio collaborated to design and implement Presto local cache to reduce HDFS latency.
Background

At Uber, data informs every decision. Presto is one of the very core engines that powers all sorts of data analytics at Uber. For example, the operations team makes heavy use of Presto for services such as dashboarding; The Uber Eats and marketing teams rely on the results of these queries to make decisions on prices. In addition, Presto is also used in Uber’s compliance department, growth marketing department, and ad-hoc data analytics.

The scale of Presto at Uber is large. Currently, Presto has 7K weekly active users, processing 500K queries per day and handling over 50PB of data. Uber has two data centers with 5000 nodes and 15 Presto clusters across 2 regions in terms of infrastructure.
Uber’s Presto Deployment
Current Architecture
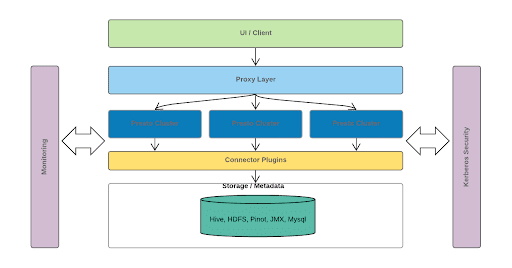
Uber’s Presto architecture is shown in the diagram above.
- The UI/Client layer. This includes internal dashboarding, Google Data Studio, Tableau, and other tools. In addition, we have some backend services that use JDBC or query parsing to communicate with Presto.
- The proxy layer. This layer is responsible for pulling stats from each Presto coordinator, including the number of queries and tasks, CPU and Memory usage, and so on. We determine which cluster each query should be scheduled to based on these stats. In other words, it is doing the load-balancing and query-gating services.
- Presto clusters. At the bottom, multiple Presto clusters communicate with the underlying Hive, HDFS, Pinot, and others. Join operations can be performed between different plugins or different datasets.
In addition, for each layer of the above architecture, we have
- Internal monitoring
- Support for using Kerberos security
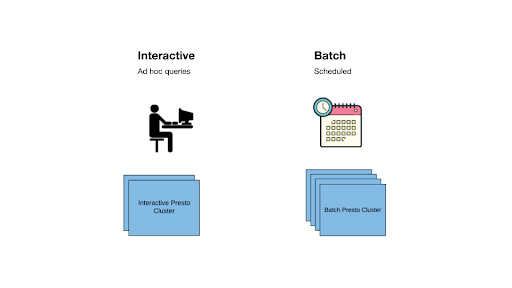
The Presto workloads are divided into two categories.
- Interactive: Query sent by data scientists and engineers
- Scheduled: mainly Batch query, which is scheduled and recurring, including Dashboard query, ETL query, etc.
The Journey to the Cloud
Over the past few years, the Uber team has been thinking about how and when to go to the cloud and what the layout should be to interact with the cloud. We are using the “what-why-how” model.
What: we have a variety of application layers, such as BI applications. On the computation engine side, we have Spark, Presto, and so on. In the cloud, there are many cloud-native options. On the storage side, we can choose from GCS, S3, HDFS in the cloud, and many other options.
Why: One of the most important motivations is to improve cost efficiency and achieve elastic scaling of hardware resources. Also, we want to achieve high usability, scalability, and reliability.
How: On the one hand, because cloud provides many native features, we need to consider features compatibility with open source components. On the other hand, we need to figure out how performance works at different scales. Uber holds a huge data lake, so performance is crucial for the customers and us. Additionally, we are looking into the cloud’s ability to enforce security and compliance requirements. The native cloud-provided services can also be used to reduce “tech debt.”
Future State – Hybrid Cloud
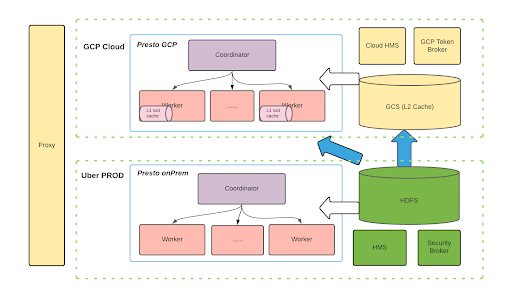
The diagram above shows the long-term plan. The solution can be extended to different cloud service vendors based on such an architecture. Now, we are still in the very early stages of implementation.
We want to run a hybrid model with PROD clusters (on-prem) and cloud clusters (GCP).
As shown in the bottom right corner of the figure, we expect most of the data to still be on-prem HDFS. The blue arrows represent some pre-tests we did where we ran some experiments without any caching on top of HDFS. The results showed high network traffic and cost, which is a huge overhead.
Therefore, we are exploring public cloud services, such as GCS or S3, to serve as an L2 Cache. We want to put some important data or frequently used data sets in the “L2 Cache on the cloud”. For each Presto cluster in the cloud, we plan to leverage local SSDs to cache some data to improve performance. This solution can be scaled into different cloud providers using the same architecture, which is our vision in the long term.
Using Alluxio for Local Caching
Recently, we deployed Alluxio in our product environment in three clusters, each with more than 200 nodes. Alluxio is plugged in as a local library and it leverages the Presto workers’ local NVMe disks. We’re not caching all the data, but a selective subset of data called selective caching.
Below is a diagram of Alluxio as a local cache. The Alluxio Cache Library is a local cache that runs inside the Presto worker. We have implemented a layer on top of the default HDFS client implementation.
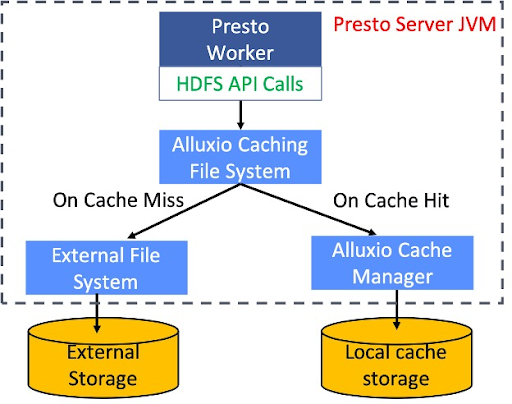
When any external API reads from an HDFS call, the system first looks at the inventory of the cache to see if it is a cache hit or miss. If it’s a cache hit, it will directly read the data from the local SSD. Otherwise, it will read from the remote HDFS and cache the data locally for the next read. In this process, the cache hit rate has a significant impact on the overall performance.
We will discuss the detailed design and improvement of the Alluxio local cache in part 2 of this blog series.
Key Challenges and Solution
Challenge 1: Real Time Partition Updates
The first challenge we encountered was the real time partition updates. At Uber, a lot of tables/partitions are constantly changing because we upsert queries constantly into Hudi tables.
The challenge is that the partition id alone as a caching key is not sufficient. The same partition may have changed in Hive, while Alluxio still caches the outdated version. In this case, partitions in cache are outdated so the users will get outdated results while running a query if the data is served from caching, resulting in inconsistent experience.
Solution: Add Hive latest modification time to caching key
Our solution is adding the latest modification time to the caching key as below:
- Previous caching key: hdfs://<path>
- New caching key: hdfs://<path><mod time>
Through this solution, the new partition with the latest modification gets cached, ensuring that users always get a consistent view of their data. Note that, there’s a trade-off – outdated partitions still present in cache, wasting caching space until evicted. Currently, we are working to improve the caching eviction strategy.
Challenge 2: Cluster Membership Change
In Presto, Soft Affinity Scheduling is implemented by the simple mod-based algorithm. This algorithm has the disadvantage that if a node is added or deleted, the whole ring is messed up with a different cache key. Therefore, if a node joins or leaves a cluster, it can hurt the cache efficiency of all the nodes, which is problematic.
Presto locates the same set of nodes for a given partition key for this reason. As a result, we always hit the same set of nodes both for caching and queries. While this is good, the problem is that Presto previously used a simple hash function that can break when the cluster changes.
As shown below, currently, simple hash mod based node lookup : key 4 % 3 nodes = worker # 1. Now node#3 goes down, new lookup: key 4 % 2 nodes = 0, but worker#0 does not have the bytes.
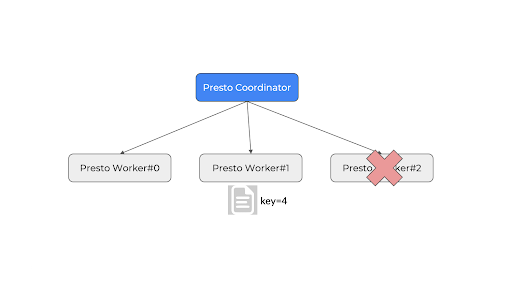
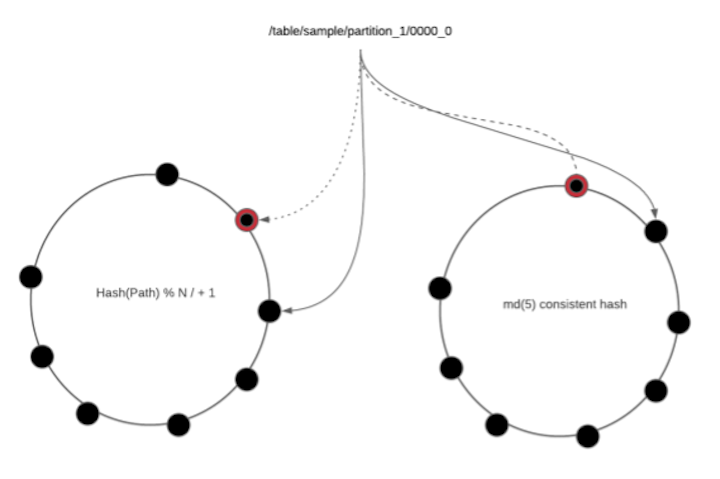
Solution: Node id based consistent hashing
Consistent hashing is the solution. Instead of the mod based function, all nodes are placed on a virtual ring. Relative ordering of nodes on the ring doesn’t change, regardless of joining or leaving. Instead of using mode based hash, we always look up the key on the ring. We can ensure that no matter how many changes are made, they are always based on the same set of nodes. Additionally, we use replication to improve robustness. This is the solution to the cluster membership issue.
Challenge 3: Cache Size Restriction
Uber’s data lake is at large scale, with 50PB of data accumulated per day. However, our local disk space is only 500 GB per node. The amount of data accessed by Presto queries is much larger than the disk space available on Worker nodes. Although it is possible to put everything in the cache, heavy eviction can hurt overall cache performance.
Solution: Cache Filter
The idea is to only cache a selected subset of data, which includes certain tables and a certain number of partitions. The solution is to develop a cache filter, a mechanism that decides whether to cache a table and how many partitions. Below is a sample configuration:
{
"databases": [{
"name": "database_foo",
"tables": [{
"name" : "table_bar",
"maxCachedPartitions": 100}]}]
}Having a cache filter has greatly increased cache hit rate from ~65% to >90%. The following are the areas to pay attention to when it comes to Cache Filter.
- Manual, static configuration
- Should be based on traffic pattern, e.g.:
- Most frequently accessed tables
- Most common # of partitions being accessed
- Tables that do not change too frequently
- Ideally, should be based on shadow caching numbers and table level metrics
We’ve also achieved observability through monitoring/dashboarding, which is integrated with Uber’s internal metrics platform using Jmx metrics emitted to Grafana based dashboard.


Current Status and Future Work
Current Status
We have deployed 3 clusters of 200+ nodes each to our production cluster, with all nodes on NVMe disks, and 500GB cache space per node. We used a cache filter to cache about 20 most frequently accessed tables.
We are still in the early stage of deployment and monitoring results. The initial measurement shows great improvement with about 1/3 of wall time for input scan (TableScanOperator and ScanFilterProjectOperator) vs. no cache. We are very encouraged by these results. Alluxio has shown great query acceleration and provides consistent performance in our big data processing use cases.
Next Steps
First, we would like to onboard more tables and improve the process of table onboarding with automation, in which Alluxio Shadow Cache (SC) will be helpful. Second, we want to have better support for the changing partitions/Hoodie tables. Lastly, load balancing is another optimization we can implement. There’s still a long way to go along our journey.
As compute-storage separation continues to be the trend along with containerization in big data, we believe a unified layer that bridges the compute and storage like Alluxio will continue to play a key role.
Read part 2 of the blog series for detailed design and improvement of the Alluxio local cache.
About the Authors
Chen Liang
Chen Liang is a senior software engineer at Uber’s interactive analytics team, focusing on Presto. Before joining Uber, Chen was a staff software engineer at LinkedIn’s Big Data platform. Chen is also a committer and PMC member of Apache Hadoop. Chen holds two master’s degrees from Duke University and Brown University.
Beinan Wang
Dr. Beinan Wang is a software engineer from Alluxio and is the committer of PrestoDB. Before Alluxio, he was the Tech Lead of the Presto team in Twitter, and he built large-scale distributed SQL systems for Twitter’s data platform. He has twelve-year experience working on performance optimization, distributed caching, and volume data processing. He received his Ph.D. in computer engineering from Syracuse University on the symbolic model checking and runtime verification of distributed systems.