Overview
Offline inference, or batch inference, is an approach to run machine learning (ML) inference in a batch mode when processing a large dataset, as opposed to generating predictions in real-time given the input. The offline inference jobs are typically built on top of big data platforms to scale horizontally, and are running on fixed schedules (e.g. hourly, daily).
Running inference at scale is challenging. In this blog, we will share our observations and the practice to use Alluxio to speed up the I/O performance for large-scale ML/DL offline inference at Microsoft Bing.
1. I/O Challenges of Running Offline Inference Jobs at Scale
To understand our challenges, let us first introduce our offline inference jobs in this scale, data access pattern and architecture:
- Large Scale in Input and Output:: each job has more than 400 tasks and each task reads a different data set and generates its own output. There is no interaction between tasks. Each task reads about 2-3GB of data and generates about 7-8GB of data, which makes the total input and output data very large. For each job, the input data is about 1TB, and the output data is 3.5TB. The task is time-consuming and takes about 2-4 hours to complete.
- Read-once Data Access Pattern: Offline inference jobs have a simple access pattern. It only needs to read the input data once sequentially and output the results to Azure Blob while the job is running. Unlike the training job, which reads all the input data over and over again for each output, the offline inference job only reads it once.
- Cloud-native Infrastructure: Our architecture uses Azure Blob for storage, the open-source project OpenPAI as AI training platform, and the open-source project Hived as the scheduler to schedule each job to its own node.
When processing a large amount of ingress and egress data, I/O failures can easily occur. Tools like Blob-FUSE will download data before running the task, and upload the results to Azure Block cloud storage after the job is finished. In our case, each job contains about 400 tasks.
As these tasks begin almost at the same time, the data downloading starts at the same time as well, so it is likely to cause high IOPS and easily exceed the Azure Blob bandwidth limit. Due to the similarity of these tasks, they finish around the same time, therefore will upload the output to the Azure storage system at the same time. This makes it easy to hit the bandwidth limit of Azure Blob.
Once the bandwidth limit is reached, the job becomes invalid, and all tasks in the job must be re-executed, which can be very time-consuming. Re-execution delays increase the cost as GPUs remain idle waiting for I/O to complete.
2. Architecture and Optimization
Prod Bed Environment
- VM: About 200 Azure low-priority virtual machines (VMs), each with 4 GPUs. The VMs are low-priority and can be preempted by Azure at any time, which makes the environment unstable. It is necessary that we take steps to make the training platform more robust.
- Alluxio: Alluxio 2.3.0
- Kubernetes: Kubernetes 1.15.x
- Time spent in production: We have been running Alluxio smoothly for more than 6 months
Architecture with Alluxio
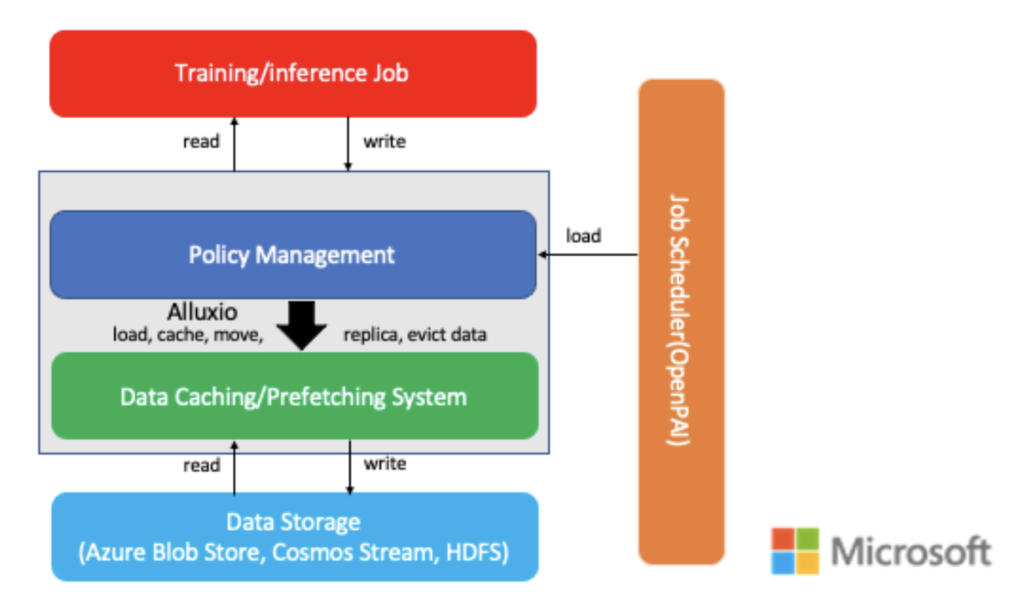
The architecture consists of four parts: the job scheduler (OpenPAI, hived), training/inference job, data storage (Azure Blob Store, Cosmos Stream, HDFS), and Alluxio. Alluxio is the cache layer of the entire system.
When a user submits a job, it first enters the job scheduler. Before the job starts running, it will send a command to Alluxio to prefetch part of the data into the cache. After that, the job scheduler will schedule the job to its own node. Jobs can directly read or write data to Alluxio without interacting with the data storage system. For Alluxio, we want to customize its replacement policies to make the inference job more efficient.
CSI Based on Deployment
We have learned that Alluxio has multiple deployment methods. The most basic one is to deploy a FUSE daemon on each node. All jobs communicate with the FUSE daemon deployed on these nodes to read or write data. This type of deployment, however, cannot satisfy the various demands of inference jobs for data read and write.
For the inference job, all tasks need to read the model files while performing task reading. In addition to caching the model files, Alluxio also caches the model files’ metadata for improved performance. Therefore, we turn on the metadata cache, enable the kernel cache, and set a relatively long timeout period. In addition, we need to output the data to its own folder, so we have to turn off the cache metadata, and also customize the Alluxio configuration file to avoid data loss.
To meet various demands of data read and write, we adopted a CSI-based deployment method.
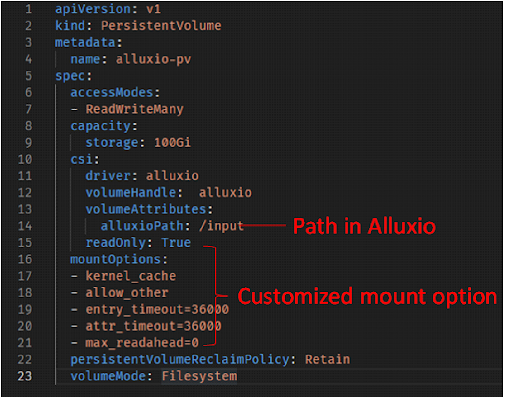
Here is an example of how to use CSI. For each CSI mount point, a configuration file can be provided to customize the mount option as well as Alluxio configuration, such as setting the mount folder in Alluxio, which is very convenient. At the same time, we can also customize several mounting options.
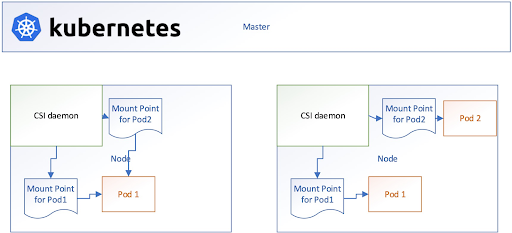
For each inference task, we provide two mount points, one for data read and one for data write. Each mount point has its own FUSE daemon.
CSI-based deployment has the following benefits:
- The system can be configured separately for different read and write scenarios to make task execution more efficient.
- For each pod, there will be a separate FUSE daemon. If a FUSE daemon fails, it will only affect the corresponding workload, and will not affect other workloads running on the same node, which improves the robustness of the system.
- Each job can be mounted to a different path, and each path can be controlled by the admin, therefore, the admin can provide several configuration sets to the CSI persistent volume. Only one of the volumes can be selected for each job. If the admin does not provide the configuration of the corresponding path, jobs scheduled to the node cannot use the path or modify the corresponding files, in this way the security of the system and the access control can be ensured.
Optimization in Alluxio FUSE Client
In our case, we mainly process the offline inference job, which will generate a lot of output data. These data are very important for us and data scientists. We have optimized the FUSE client to create a safer, more reliable result.
The first optimization is the flush enhancement. We have received feedback from our users that they have lost the output results after the job was finished. After investigating this issue, we finally solved it by implementing the flush function in the FUSE daemon. When a job is finished, the system will automatically call the flush function. By optimizing the flush function, we have prevented the loss of output data.
The second optimization is the release enhancement. Some users want to further process the output data for other experiments, but only to find that the output data file cannot be opened during subsequent experiments. Alluxio log shows that the previous job is not completed.
We investigated this issue and found that Alluxio’s release function is asynchronous, which may give the impression that the task is complete but it is not, since the function to close the file may not have been completed. Because the client regards the job as finished, it closes the job. However, the grpc communication between the client and the server is dropped, making it impossible to close the server. After the optimization, logic is added to the release function and unmount function to ensure that all operations requested by the client are processed by the Alluxio server before unmounting.
By optimizing the two aspects, we made the system more stable and robust.
Prefetch Feature
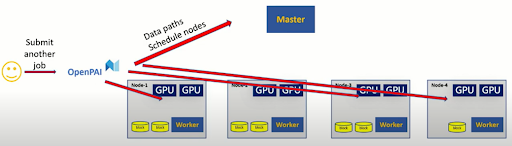
We cache the data in the cache layer through Alluxio before the job actually starts running. Through this operation, the job can be executed immediately without waiting for the data to be retrieved.
When a user submits a job to OpenPAI, the job scheduler will schedule it. In the case of running tasks in the cluster, these will have to wait a period of time. Meanwhile, OpenPAI can send a prefetch command to Alluxio master, which will cache the data. Therefore, the workload has already been cached before the job runs. As a result, OpenPAI will schedule the job to run directly on its own node.
3. Performance Benchmarking
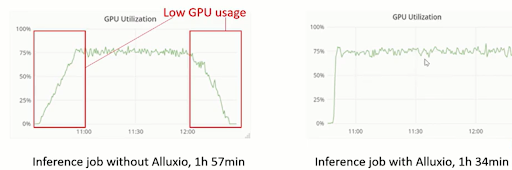
According to the test results, Alluxio’s optimization greatly improves the job’s running speed. The figure above on the left shows the change in GPU utilization without Alluxio, while the right figure shows the GPU utilization with Alluxio. Without Alluxio, the job needs to download the data first, and after the job is finished, it will take some time to upload the data to Azure Blob.
With Alluxio, although it still takes time to download the data, it becomes less time-consuming since not all the data needs to be downloaded. As the inference job will output and upload data even while it is running, there is no need to wait until the job is completed. Since the job takes more than two hours to complete, this method relieves the job’s pressure on the I/O system, which also smooths the I/O requests.
Alluxio also brings some other advantages, such as read retry. If the read fails, it will automatically re-read, thereby reducing the failure rate of the job run.
By implementing Alluxio, we are able to speed up the inference job, reduce I/O stall, and improve performance by about 18%.
4. Future Work
We plan to add the write retry feature in case of write operation failure. Alluxio provides retry logic only for read operations, but not for writes. When the client wants to write data, it will first send a request to the worker node, then the worker will process the relevant data. If the worker node fails, the write operation will fail, which will cause the job to fail as well. We adopt Azure Low Priority VM, so the worker node may be reclaimed by Azure at any time. A problem with the worker node will result in the failure of our task. We hope to enhance the reliability of our system by adding the write retry feature.
We will adopt Alluxio in training jobs. Training jobs have a special data access pattern, which allows them to read the same input data once each time. To make the training process more efficient, we will need to develop new data replacement policies.
About the Authors
Binyang Li is a Software Engineer from Bing, with a focus on AI infrastructure.
Qianxi Zhang is Sr. Research Software Engineer from MSRA (Microsoft Research Asia), with a focus on next-generation storage systems.
References