This article introduces Structured Data Management available in the latest Alluxio 2.2.0 release, a new effort to provide further benefits to SQL and structured data workloads using Alluxio.
Motivation
Today, many users deploy Alluxio in analytics or AI platforms to provide unified data access while transparently caching the relevant data for accelerated data IO. No matter the computation framework being used, Alluxio can provide the abstraction on files, directories, and objects in a logical “Alluxio File System”.
Files and directories are the standard means for a filesystem to arrange and access data, but this format is not always compatible with various analytics engines. For compute frameworks such as Presto, Apache Spark SQL, or Apache Hive, the desired data format is represented as a table, consisting of rows and columns. This disparity is analogous to a conversation between two people who speak different languages; in order for one to understand the other, there must always be a translator present. This inefficiency grows as the data scale increases since each piece of information retrieved must first be converted before it is consumable and vice versa when storing computed information.
Our goal is to deliver physical data independence, where the logical access of data by the SQL engines is independent from the physical format of the stored data. Since Alluxio is the ecosystem layer between compute and storage, Alluxio is in a great position to bridge the gap between SQL engines and file or object-based storage systems to enable physical data independence.
What’s Alluxio Structured Data Management
Alluxio Structured Data Management is a new set of services that enables structured data applications to interact with data more efficiently. With Structured Data Management, Alluxio can expose the data to be effectively accessed by the SQL engines, independent of how and where the data is stored.
There are two major points of focus that drive the direction of Alluxio Structured Data Management:
- Provide structured data APIs which focuses on how SQL engines interact with data。 This will introduce new APIs relevant to structured data concepts, like tables, schemas, rows, and columns.
- Cache Logical Data Access which focuses on caching what SQL engines want. In other words, Alluxio will cache compute-optimized data.
To achieve these goals, there are several major requirements to build in Alluxio Structured Data Management:
- Structured Data Client: the client is the gateway for SQL engines to interact with the various components of Alluxio Structured Data Management.
- Structured Data Caching and Metadata: this component stores and caches compute-optimized data for SQL engines, and manges the metadata for the cached data. This enables Alluxio to be aware of the structure of data, for schema-aware optimizations.
Transformation Service: the Transformation service is responsible for transforming existing data into a compute-optimized representation. This enables the physical data independence of compute-optimized data from storage-optimized data.
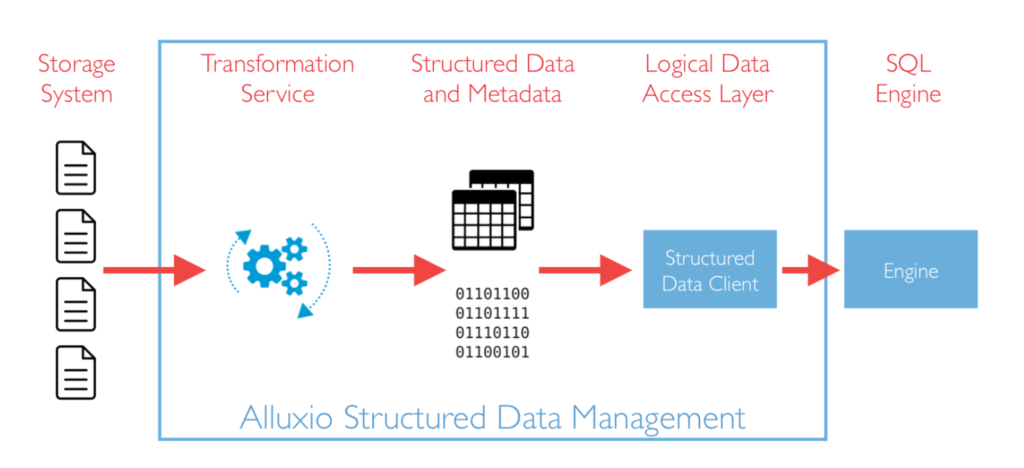
The Alluxio 2.2.0 release brings the implementations of these components with an initial developer preview. The primary use case for the develoer preview is a cluster with Presto using the Hive Metastore via the hive connector. Alluxio Structured Data Management introduces several new components in the ecosystem.
- Structured Data Client for Presto, a Presto Connector for Alluxio
- Catalog Service
- Basic Transformation Service
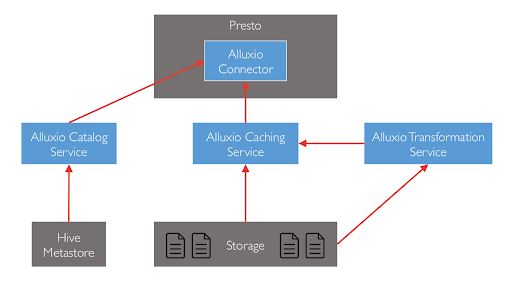
Presto Connector for Alluxio
A new connector is provided to allow for easy integration and configuration of Alluxio with Presto. Interactions with existing Alluxio components communicate through this connector.
Catalog Service
The new Alluxio Catalog Service manages the metadata of structured data in the system. It is responsible for all the database, table, and schema information, as well as the location of all the stored data.
The major new concept in the catalog service is the UnderDatabase. Similar to how the UnderFilesystem abstracts different filesystems for Alluxio to connect to, the UnderDatabase is the equivalent abstraction for external catalogs and databases. The developer preview includes a Hive Metastore implementation of the UnderDatabase.
The main way the user interacts with the catalog service is to attach a database which associates it to a catalog. Attaching an existing database to the catalog service is equivalent to mounting an existing filesystem to the Alluxio filesystem. For example, if a hive database is attached to an Alluxio catalog database called “alluxio_db”, calls to “alluxio_db” access the underlying hive database.
The Alluxio Catalog Service provides several benefits for the Presto with Alluxio environment. Note that the deployment does not require any changes whatsoever to Presto or its Hive Metastore. Once connected, the catalog service will automatically mount the appropriate table locations and serve the table metadata from Alluxio.
Transformation Service
The transformation service is responsible for transforming data into a compute-optimized representation of the data. This enables physical data independence from the storage-optimized format.
The developer preview includes 2 types of transformations available for tables: coalesce and format conversion.
- Coalesce: The coalesce transformation enables the data to be combined into fewer files, which is desirable because a large number of files in a table are inefficient for SQL engines to process.
- Format Conversion: Columnar and binary formats such as parquet and ORC are usually more efficient to process than raw text files. In this developer preview, the available format conversion is a CSV to Parquet conversion.
Summary
Structured Data Management enables physical data independence by bridging the gap between SQL engines and file or object-based storage systems. We are excited to introduce the Developer Preview of Alluxio Structured Data Management in the Alluxio 2.2.0 release! The initial implementations of the major components are available with this developer preview. In the next article, I will go through a simple example step-by-step to illustrate how to use Structured Data Management in Alluxio.
If you are not sure about your use case, feel free to ask questions in our Alluxio community slack channel.