I. Introduction
Previous works
There have been numerous articles and online webinars dealing with the benefits of using Alluxio as an intermediate storage layer between the S3 data storage and the data processing system used for ingestion or retrieval of data (i.e. Spark, Presto), as depicted in the picture below:
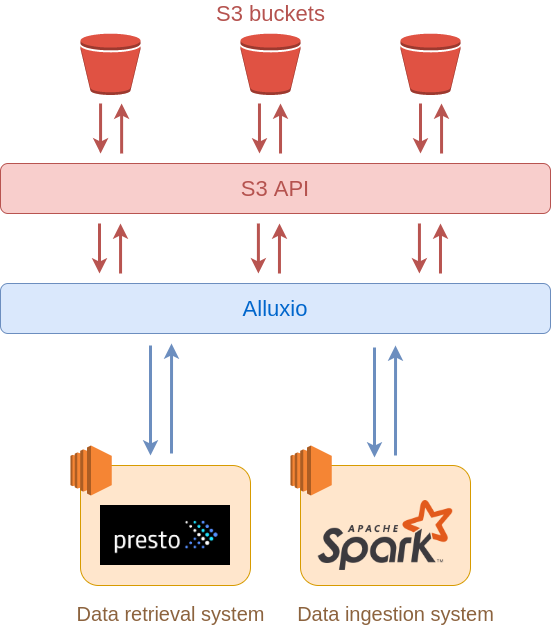
To name a few use cases:
- Alluxio-Presto use cases:
- Alluxio-Spark use cases:
The main conclusion from these use cases is that using Alluxio as a data orchestration layer has the following benefits:
- lower latency in data processing pipelines:
- Co-locating data and computation reduces network traffic
- horizontal scalability for usage concurrency:
- S3 API has limitations on the request rate for a given prefix
All these benefits are critical when deciding a production-grade data processing architecture, however one important benefit has so far not been sufficiently highlighted when choosing such architecture – cost reduction on the usage of the S3 API. This will be the focus of this article.
datasapiens
datasapiens is an international startup, based in Prague, that focuses primarily on helping companies to transform their business through data. We offer 3 key products:
- Business insights
- our business intelligence platform with an embedded insights framework to help clients to become data-driven companies.
- Brands insights
- commercialize clients’ data assets by driving cooperation with their suppliers.
- Personalized offers
- increase customer engagement, sales and margin through a simple plan-do-review process that continuously measures and improves the loyalty lifecycle of clients’ customers.
Our infrastructure journey
The first generation of our infrastructure used AWS Redshift as the main data warehouse. However, when we started to acquire clients with larger data volumes (i.e. billions of records per year) we started to struggle with the following:
- storage-compute coupled architecture
- large infrastructure costs
- long query compilation times
- vendor-locking
It was at this point that we decided to move to the Hadoop ecosystem.
The first version of our second generation was the common software stack for cloud-based data lake architectures:
- S3 for data persistence
- Spark for ETL
- Hive for data warehousing
- Presto as a distributed query engine
With this storage-compute separated architecture, we achieved faster performance and reduced compilation times. However, the infrastructure costs were above expectations due to S3 API cost increases, making up a large proportion of the overall cost (described in detail below).
The second version of our second generation includes Alluxio as a data orchestration layer. We co-locate our data with our compute for in-memory data access. This architecture achieves even faster performance more consistently. In addition, we saw a drop in infrastructure costs due to S3 API costs dropping to a negligible level.
II. Our observations
A drastic increase in S3 API costs
During the fine-tuning of our first Presto cluster, we conducted several performance tests of the cluster under various levels of user concurrency.
The setup of the performance tests was the following:
- dataset setup:
- internal client data (1 billion rows of retail transactional data)
- persisted in Parquet
- workload setup:
- 23 different queries used in client’s reports
- concurrency levels from 1 to 150
- cluster hardware setup:
- worker nodes:
- count: 10
- type: c5.4xlarge
- master nodes:
- count: 1
- type: c5.4xlarge
- worker nodes:
- cluster software deployment setup:
- PrestoDB 0.227
- Apache Hive v2.3.5
For the design of our DWH, we wanted to avoid using the traditional star/snowflake schemas. Instead, we could pre-join the table entities in our ETL into a few OLAP cubes to avoid expensive table joins in Presto.
Towards the end of the testing phase, we detected a dramatic increase in costs for the S3 API service. The following image depicts the incurred S3 API costs for each day of the performance tests:
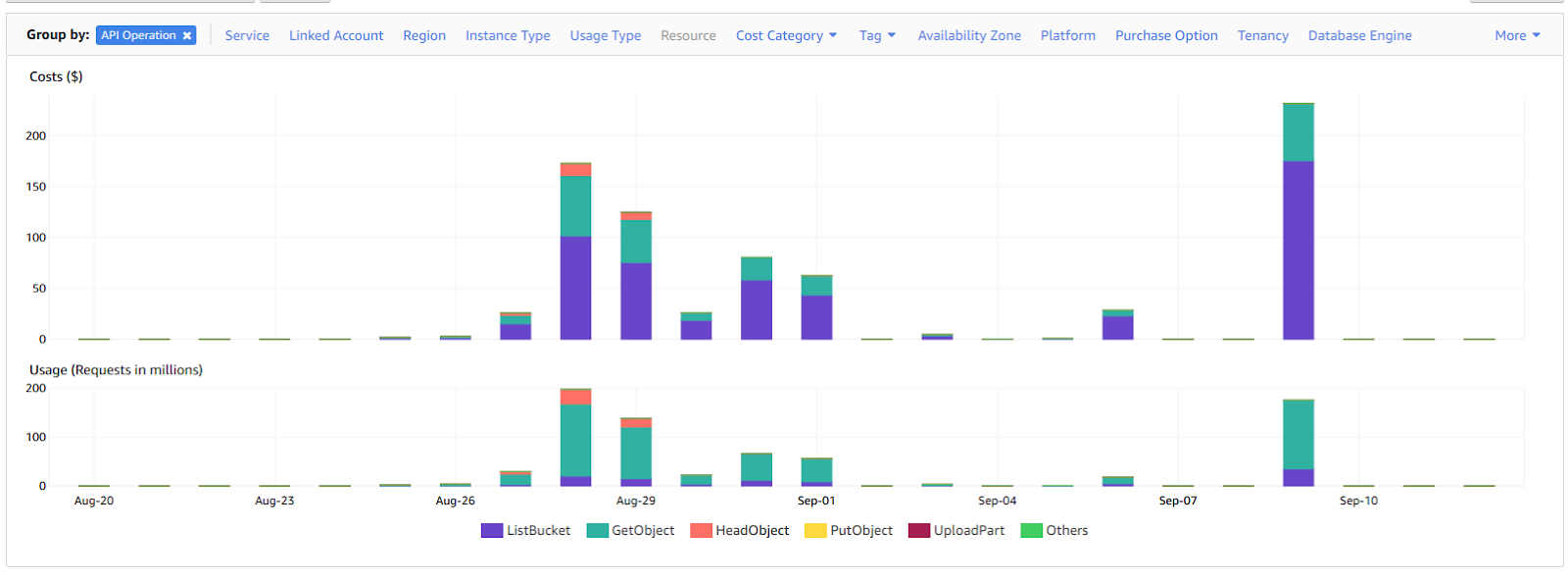
The following table summarizes the total number of executed queries with the S3 API costs and S3 API request counts per each day of performance tests:
| Date | Total query count | Total S3 costs ($) | Total S3 request count | Avg. costs per query ($) | Avg. S3 requests per query |
| 2019-08-28 | 15,086 | 172.73 | 197,549,860 | 0.01145 | 13,095 |
| 2019-08-29 | 29,997 | 124.87 | 138,210,969 | 0.00416 | 4,607 |
| 2019-08-30 | 6,394 | 26.27 | 22,638,580 | 0.00411 | 3,541 |
| 2019-08-31 | 36,815 | 80.47 | 66,406,798 | 0.00219 | 1,804 |
| 2019-09-01 | 13,939 | 62.54 | 56,195,976 | 0.00449 | 4,032 |
| 2019-09-03 | 752 | 4.72 | 3,331,228 | 0.00628 | 4,430 |
| 2019-09-06 | 6,806 | 28.59 | 18,005,207 | 0.00420 | 2,645 |
| 2019-09-09 | 75,687 | 231.74 | 175,443,269 | 0.00306 | 2,318 |
| Total | 185,476 | 731.93 | 677,781,887 | 0.00395 | 3,654 |
The next table shows the percentage of the S3 API costs out of the total costs:
| Date | Total S3 costs ($) | Total EC2 costs ($) | S3 API costs – % of total costs |
| 2019-08-28 | 172.73 | 45.25 | 79.24% |
| 2019-08-29 | 124.87 | 107.21 | 53.80% |
| 2019-08-30 | 26.27 | 27.18 | 49.15% |
| 2019-08-31 | 80.47 | 29.42 | 73.23% |
| 2019-09-01 | 62.54 | 23.69 | 72.53% |
| 2019-09-03 | 4.72 | 11.47 | 29.15% |
| 2019-09-06 | 28.59 | 73.05 | 28.13% |
| 2019-09-09 | 231.74 | 102.97 | 69.24% |
| Total | 731.94 | 420.24 | 63.53% |
During this testing period, we tested several configuration variations of the Presto cluster in order to achieve a satisfying query speed at a specific concurrency level. In the first table above, we can observe the variance in the S3 API costs/requests per day. We attribute this variance to the varying Presto cluster deployments for each day in the testing period.
After reviewing the incurred S3 API costs under the given workloads, we came to the conclusion that running a Presto cluster that read directly from S3 was not feasible, as it would impact our profit margin.
Alluxio as a remedy
We considered deploying Hadoop as an intermediate layer between Presto and S3 and synchronizing through simple jobs.
We also looked at Alluxio, which provided similar functionality without the need for manual synchronization. Furthermore, Alluxio has additional benefits such as connections to various cloud providers & storage devices and having tiered storage functionality which we thought would improve query speed.
After deploying a co-located Alluxio-Presto cluster, the performance of queries improved (especially for those with a higher number of execution stages), and the S3 API costs dropped to below $1/day. We have since implemented co-located Alluxio-Presto clusters in production. The infrastructure is successfully serving hundreds of users per client.
We also learned that although manual synchronization is not needed. To prevent any performance degradation of the Presto clusters during startup and after ETL jobs it’s best to “hydrate” the cluster using “warm-up” jobs.
III. A reproducible example using TPC-DS
To get a better quantitative understanding of the S3 API costs and the cost reduction when using Alluxio, we conducted a simple experiment by querying data from S3 in two separate clusters:
- a co-located Alluxio-Presto cluster using PrestoSQL deployed in a Docker Swarm cluster
- an EMR cluster with PrestoDB without Alluxio
In both clusters, we measured the API request count to Alluxio per each query.
The following are the setup schemas for each cluster:
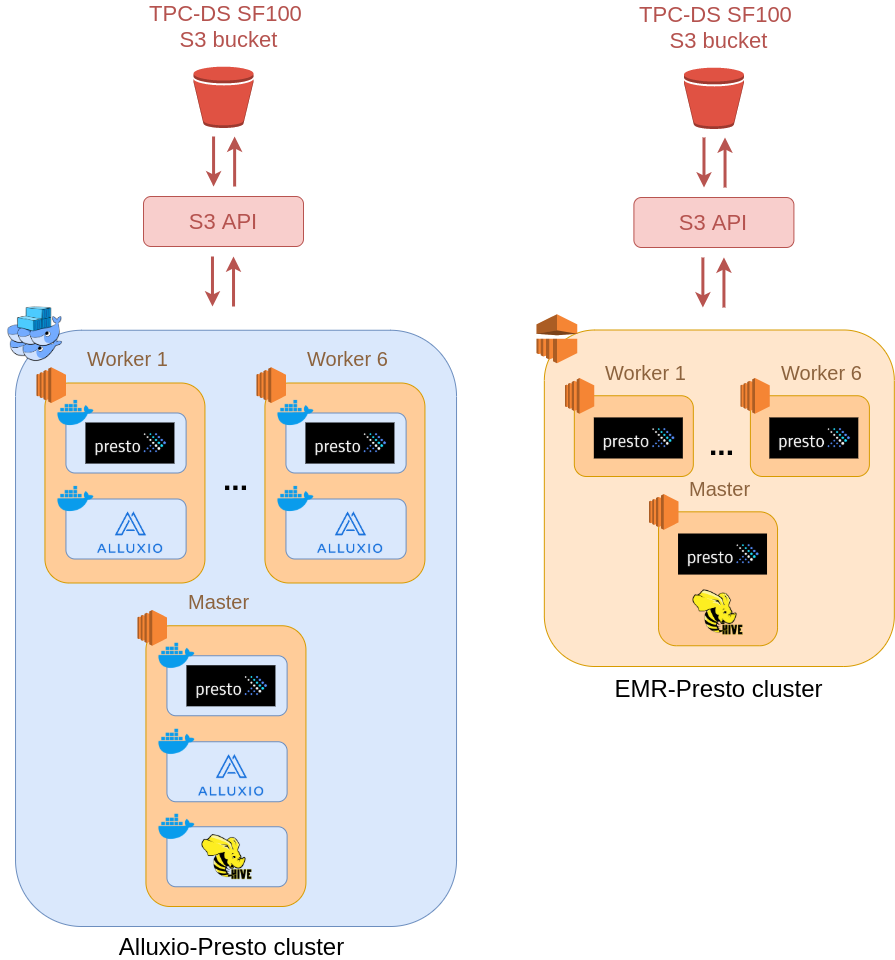
Dataset setup:
- TPC-DS dataset with scale factor 100
- stored in a S3 bucket
Alluxio-Presto cluster setup:
- hardware setup:
- worker nodes:
- count: 6
- type: c5.4xlarge
- master nodes:
- count: 1
- type: m5.2xlarge
- software deployment setup:
- versions of used systems:
- Alluxio 2.2.0
- PrestoSQL 337
- versions of used systems:
EMR-Presto cluster setup:
- hardware setup:
- worker nodes:
- count: 6
- type: c5.4xlarge
- master nodes:
- count: 1
- type: m5.2xlarge
- software deployment setup:
- PrestoDB 0.227
Query execution setup:
- set of queries:
- TPC-DS suite excluding Query no. 72 (due to longer query times)
- query executions:
- number of repeats: 10
- concurrency level: 1 (no parallel executions)
Measurements setup:
- Alluxio:
- logical Operations: ‘File Infos Got’
- RPC Invocations: ‘GetFileInfo Operations’
- S3:
- total request counts per request type
- total request costs per request type
The deployment configuration for each of the clusters, as well as the complete test results, can be found in our GitHub repository.
Here are the results from the conducted tests on the Alluxio-Presto cluster:
- 10 most API request-expensive queries:
| Query name | File Infos Got – avg | GetFileInfo Operations – avg |
| q14_1 | 159,200.1 | 127,576.9 |
| q09 | 137,031.0 | 109,669.0 |
| q14_2 | 110,933.8 | 88,732.6 |
| q75 | 101,468.4 | 81,166.3 |
| q64 | 75,148.3 | 60,099.4 |
| q88 | 73,224.0 | 58,584.0 |
| q23_1 | 61,313.6 | 49,054.3 |
| q23_2 | 60,566.2 | 48,457.6 |
| q95 | 56,518.0 | 45,212.0 |
| q28 | 54,810.0 | 43,866.0 |
- cumulative request counts:
| Operation type | Cumulative count |
| File Infos Got | 24,089,740 |
| GetFileInfo Operations | 19,287,627 |
- S3 API costs for caching the dataset into Alluxio:
| Request type | Cumulative count | Cumulative cost ($) |
| ListBucket | 28,324 | 0.14 |
| GetObject | 24,033 | 0.01 |
| HeadObject | 44,581 | 0.02 |
| Total | 96,938 | 0.17 |
Here are the results from the conducted tests on the EMR-Presto cluster:
| Request type | Cumulative count | Cumulative cost ($) |
| ListBucket | 5,771,219 | 28.86 |
| GetObject | 29,254,280 | 11.70 |
| HeadObject | 133,888 | 0.05 |
| Total | 35,159,387 | 40.61 |
As we can observe, the cumulative count for the `GetObject` request type and the `File Infos Got` request type are more-less compatible. The different values for the storage API calls in both cases can be attributed to:
- different nature of the Alluxio and S3 file system API
- different versions of used Presto clusters (PrestoSQL 337 vs PrestoDB 0.227)
In the case of the S3 API, we also have an additional cost for the `ListBucket` request type which is more costly then the `GetObject` type.
Now, we will try to estimate the per-query S3 API costs for the EMR-Presto cluster. We are limited by the following facts:
- we cannot tag individual requests to S3
- we do not know the exact number of each API request type incurred by individual query
To estimate the per-query S3 API costs, we will take a naïve approach and redistribute the costs to each query proportionally to the number of requests sent to Alluxio.
This gives us the following table with the top 10 request-expensive queries:
| Query name | S3 API cost ($) |
| q14_1 | 0.2684 |
| q09 | 0.2310 |
| q14_2 | 0.1870 |
| q75 | 0.1711 |
| q64 | 0.1267 |
| q88 | 0.1234 |
| q23_1 | 0.1034 |
| q23_2 | 0.1021 |
| q95 | 0.0953 |
| q28 | 0.0924 |
As can be seen, we can have quite significant costs for a single executed query. Let’s do a simple comparison of the cluster infrastructure and S3 API costs for both cases with and without Alluxio:
| Cluster | Infrastructure costs ($) | S3 API costs ($) |
| Alluxio+Presto cluster | 29.02 | 0.17 |
| EMR+Presto cluster | 42.55 | 40.61 |
It is apparent that the S3 API costs for the cluster with Alluxio form a negligible (0.58%) part of the total costs, whereas for the cluster without Alluxio, they form almost half (48.83%) of the total costs in our simple test case.
IV. General implications for cloud data lake architectures
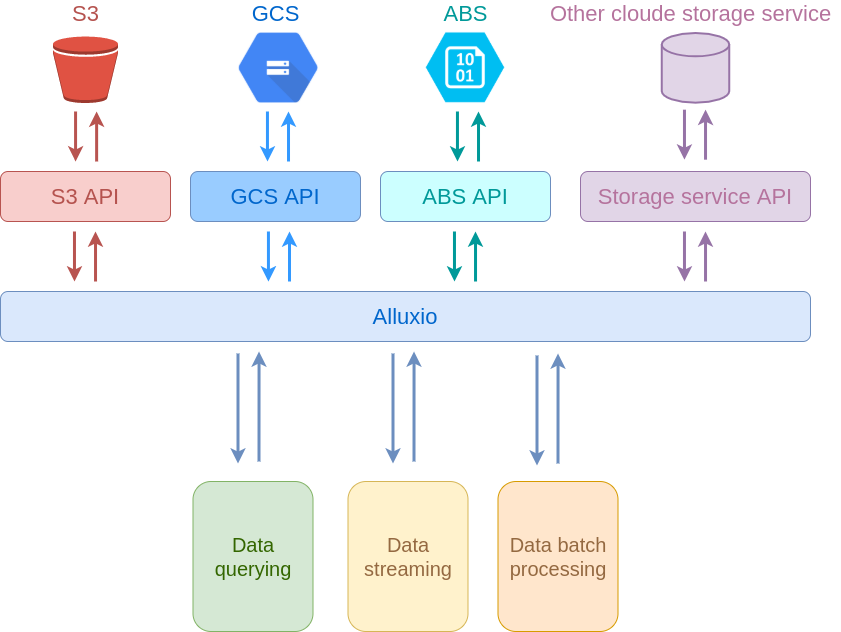
Looking at the pricing models for the storage services of three largest cloud providers (AWS S3, Azure Blob Store, and Google Cloud Storage), we see that they are very similar to each other, hence one can expect similar storage API costs when running analytical workloads with or without Alluxio. However, this claim still needs to be verified.
Our test case was a simple setup of a small cluster to which we were sending queries in a sequential manner. However, real-life production environments cope with workloads with far higher compute and storage demands. Frequently, we have:
- a large number of processes and users frequently and concurrently running queries
- workloads running real-time data streaming, ingesting and retrieving large amounts of data
For these types of cloud-based production environments, using no intermediate data storage layer between the cloud storage service and the data processing system can lead to tremendous costs.
Therefore we would be inclined to recommend that when running analytical workloads in a cloud-based environment, to have a data orchestration layer such as Alluxio.