This blog was originally published on the website of NetApp: https://www.netapp.com/blog/modernize-analytics-workloads-netapp-alluxio/
Imagine as an IT leader having the flexibility to choose any services that are available in public cloud and on premises. And imagine being able to scale your storage for your data lakes with control over data locality and protection for your organization. With these goals in mind, NetApp and Alluxio are joining forces to help our customers adapt to new requirements for modernizing data architecture with low-touch operations for analytics, machine learning, and artificial intelligence workflows.
The challenges of data growth
Data enthusiasts today experience several challenges in creating workloads for data analysis and learning. Data is collected from various sources and various geographic regions, and it’s analyzed by various applications. As a result of this proliferation, challenges continue to grow around data movement and making data available to the applications that need it. Customers want to minimize data movement and have easy access to their data, regardless of what application they’re using to analyze it.
NetApp partners with Alluxio to help customers with a number of use cases. But before we get into the use cases, let’s look at the future of data lakes. Modern data lakes need platforms that can place data at the right location and at the right tier. These platforms need to be resilient, to keep the data available during failure, and to scale easily with low-touch operations. To meet all these needs, object storage is increasingly the platform of choice as it becomes more performant, scalable, and easy to manage.
Alluxio and NetApp StorageGRID
NetApp® StorageGRID® is an enterprise-grade object storage solution that can talk native AWS S3 APIs. The solution’s unique differentiator is its information lifecycle management engine. The engine helps to place the data at the right performance tier in the form of multiple copies or to distribute data across nodes or sites by using erasure coding. In addition to flexible performance, StorageGRID offers the ability to scale easily, which makes it an outstanding solution for data lakes.
Alluxio is an open source data orchestration layer that brings data closer to compute, supporting various endpoints at both the storage and application layers. Alluxio supports drivers such as HDFS, S3, GCS, Azure, and NFS for storage, allowing customers to store data in multiple data stores. As applications access the data for analysis, Alluxio caches that dataset at its layer, making access faster for all subsequent reads. For applications like Spark, Presto, and Hive, this is a huge benefit because the applications can read data from various sources with improved performance.
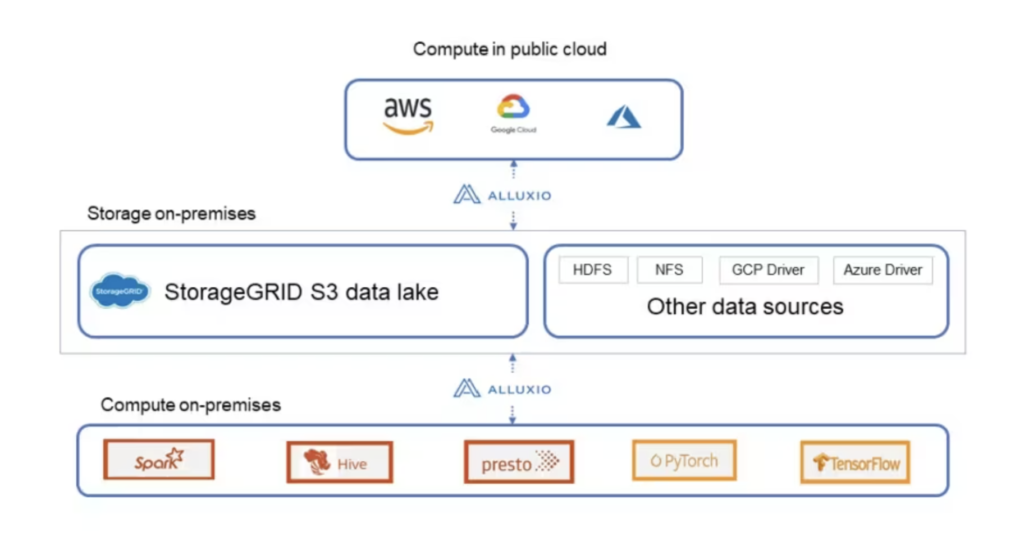
The joint solution: Connecting data to compute
Today, data in organizations is often scattered out to many different clouds, public or private. Alluxio helps you connect your data on any cloud to compute anywhere (public or private cloud). This means that organizations can separate compute and storage, helping them to lower their TCO by using their resources efficiently and unlocking the ability to scale compute and storage independently.
In addition to bringing storage closer to compute, customers are also looking for ways to move away from HDFS because of its storage overhead, inability to scale, and difficulty in managing the infrastructure. Because Alluxio supports multiple drivers, you can either cap your HDFS and scale within your S3 platform or create rules in Alluxio to slowly migrate your data to StorageGRID object storage.
Check out our solution brief and watch the webinar to see how Alluxio and NetApp can help modernize your organization’s data architecture.
Learn more about Alluxio and StorageGRID.

Joseph Kandatilparambil
Joseph Kandatilparambil is Technical Marketing Engineer for StorageGRID, with over 7 years of experience in the storage industry. Joseph helps with customer driven innovation by empowering customers with solutions that help them focus on driving their product forward and expand their horizons. Outside of work, Joseph enjoys kite-surfing, rock climbing and hiking.