GPU utilization or GPU usage, is the percentage of GPUs’ processing power being used at a particular time. As GPUs are expensive resources, optimizing their utilization and reducing idle time is essential for enterprise AI infrastructure. This blog explores bottlenecks hindering GPU utilization during model training and provides solutions to maximize GPU utilization.
1. Why Should You Care About GPU Utilization?
GPUs are blazingly fast and generally much faster than the storage that feeds them, and many organizations struggle to keep them running at their full potential. According to a recent survey on AI infrastructure, optimizing GPU utilization is a major concern. Another report from wandb shows that nearly a third are under 15% utilization, which is quite low.
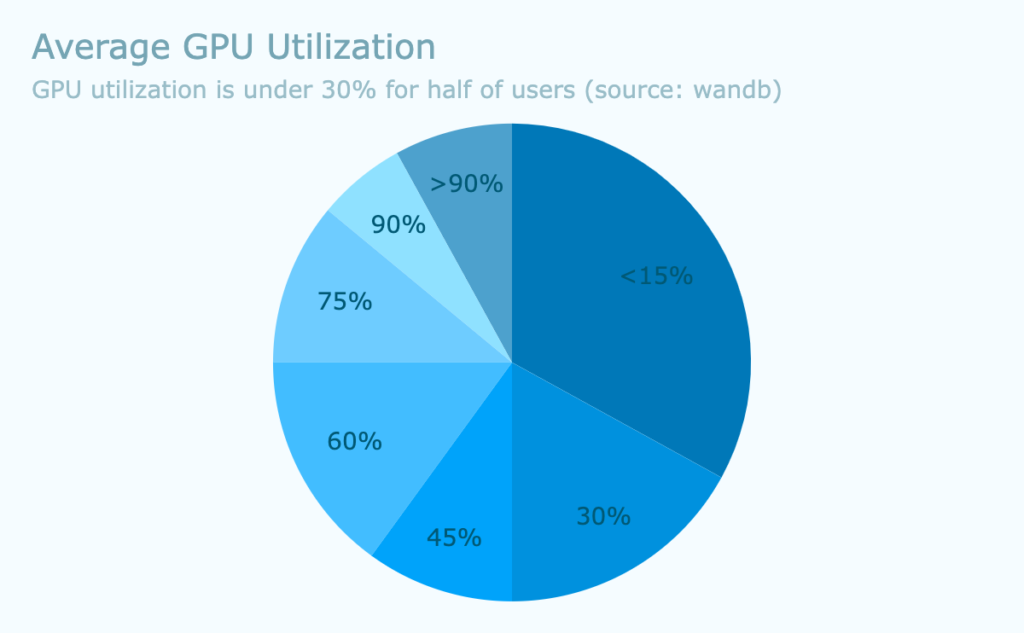
Maximizing GPU utilization is crucial for several reasons:
- Cost Optimization: GPUs are costly investments, so data platform engineers need to identify underused resources to ensure the platform runs efficiently.
- Cloud Training Efficiency: Cloud-based training has become the norm, and you are billed for computation resources by the hour or minute. Ensuring efficient use of expensive resources like AWS’s EC2 P4 instances requires reducing idle times.
- ROI for AI Infrastructure: Models require many experiments to determine optimal parameters to yield business outcomes. Optimizing GPU utilization is crucial for better returns on expensive infrastructure investment.
- Sustainability: Idle GPUs burn enormous amounts of energy and emit needless carbon while AI business initiatives and research projects stall. Maximizing GPU utilization contributes to sustainability efforts.
2. Slow Data Access Bottlenecks GPU Utilization
As the size of training data continues to grow, the time spent accessing data begins to impact workload performance and GPU utilization.
Let’s look at the typical machine learning training process. At the beginning of each training epoch, the data loader of the training framework (such as PyTorch data loader, Ray Data) loads datasets from object storage. Then, the datasets are moved to the local storage of the GPU instance, which is finally processed in the GPU memory. In this entire process, if data cannot make its way to the GPU fast enough to keep up with its computations, GPU cycles are wasted – this is called data stall or I/O stall. Studies from Google, Microsoft and IBM have shown that more than half of model training time is wasted because of waiting for data.
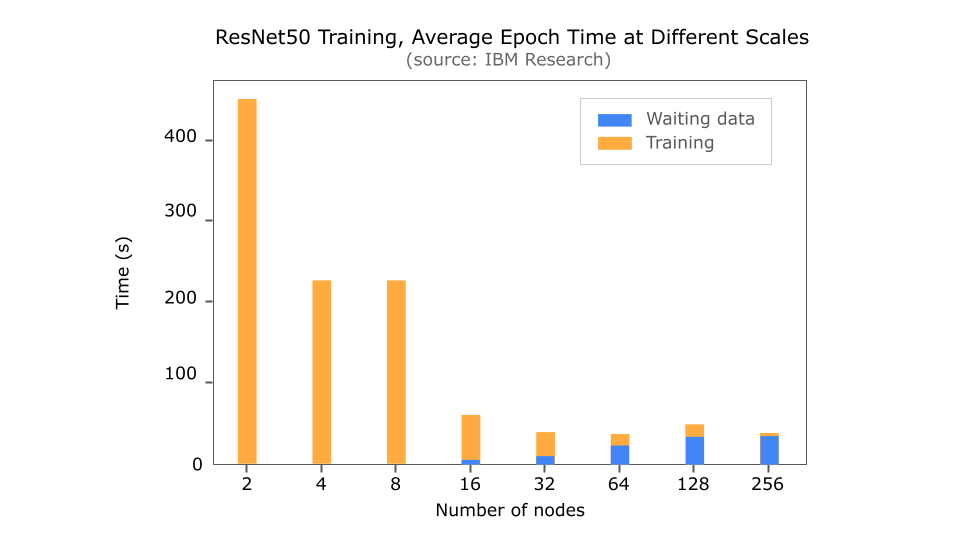
(Figure 2: As training scales across nodes, more time is spent waiting for data for multi-epoch training, source: IBM Research)
Slow data access can be attributed to the following reasons:
- Insufficient throughput provided by object storage: Commodity object storage like S3 does not provide a throughput high enough to saturate GPUs fully.
- The “many small files” problem: Training datasets may include millions of small files, typically for computer vision models. Object storage systems like S3, file systems like HDFS, and NAS/NFS storage are not optimized for handling smaller files, resulting in slow metadata operation and high random read latency.
- Data replication overhead: Copying data from object storage to local storage or copying data from one region to add another extra time waiting for data to be available.
- GPU clusters are remote from where data resides: GPU computation was traditionally co-located with datasets, but compute and storage are now disaggregated in modern data architecture. Also, as GPUs are short in supply, the training happens wherever GPUs are available, in which case, training datasets may be remote from the GPU clusters. These all lead to slow data access.
3. Using Alluxio Enterprise AI to Maximize GPU Utilization in Model Training
3.1 Overview
Alluxio Enterprise AI is a high-performance data platform that enables enterprises to optimize AI-focused workloads on existing data lakes. Alluxio has become a critical component in the AI/ML stack for bringing data closer to compute, accelerating model training and serving, boosting GPU utilization, and reducing costs for AI workloads.
Key features of Alluxio Enterprise AI include
- Performance and scalability: Optimal performance and throughput, informed by data access patterns. Delivers up to 20x training performance compared to commodity storage, 90%+ GPU utilization, and supports 100 billion objects/files
- Fast data loading, no replication/copy: Enables fast and on-demand data loading instead of replicating training data to local storage. This removes data loading as the bottleneck for model training speed. With high-performance, on-demand data access, you can eliminate multiple data copies and improve performance
- Distributed caching: Deploy the Alluxio cluster close to compute nodes for data locality and best performance. Alluxio cluster employs distributed caching that identifies frequently accessed data from under storage (like Amazon S3) and stores multiple replicas of hot data distributedly on Alluxio cluster’s NVMe storage
- Global data access: A single point of access to different storage systems, including storage federation and multi-protocol APIs, including POSIX, REST, and S3 access to data
- Deploy anywhere: Works on both on-premise and cloud, hybrid or multi-cloud. Supported cloud platforms include AWS, GCP, and Azure Cloud
- DevOps: Ease of deployment, including Kubernetes operator and dashboard with metrics
3.2 Architecture
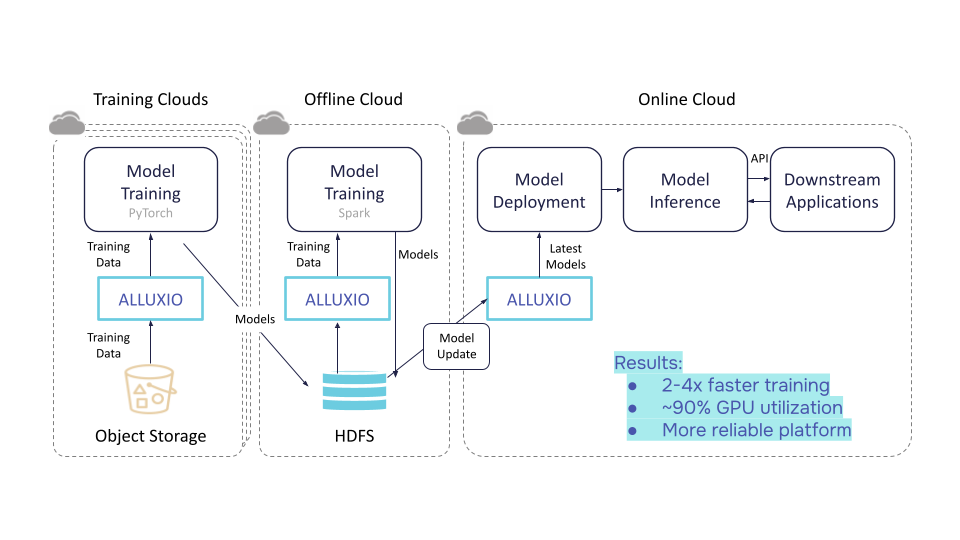
The following is a reference architecture for model training and serving with Alluxio.
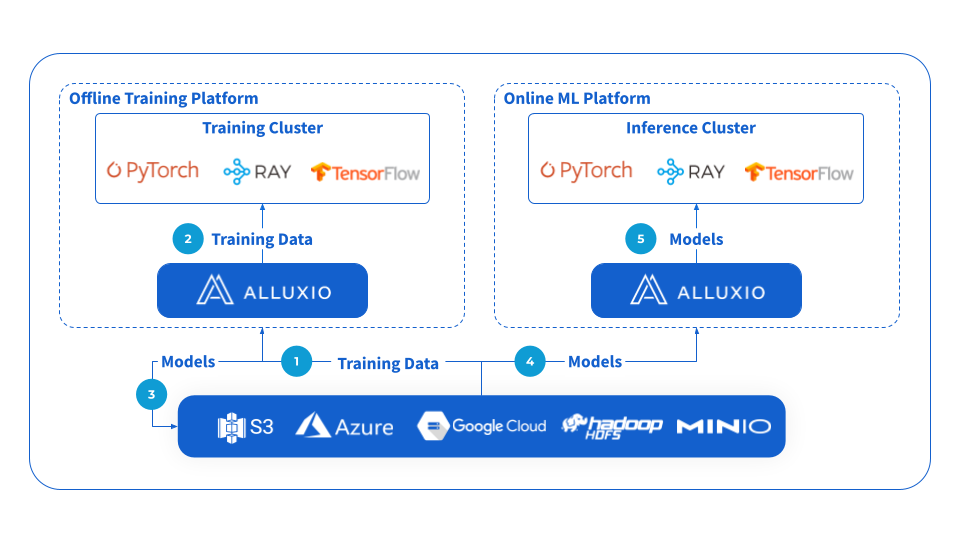
Let’s focus on the offline model training part. We can use PyTorch as the model training framework and Amazon S3 as the object storage for the training datasets. When a data scientist is training models, the PyTorch data loader loads datasets from a virtual local path /mnt/alluxio_fuse/training_datasets. Instead of loading directly from S3, the data loader will load from the Alluxio cache instead. During training, the cached datasets will be used in multiple epochs, so the entire training speed is no longer bottlenecked by retrieving from S3. In this way, Alluxio speeds up training by shortening data loading and eliminates GPU idle time, increasing GPU utilization. After the models are trained, PyTorch writes the model files to S3 through Alluxio.
3.3 GPU Utilization Benchmark Results
The following test is based on the results of Resnet-50 training with three epochs.
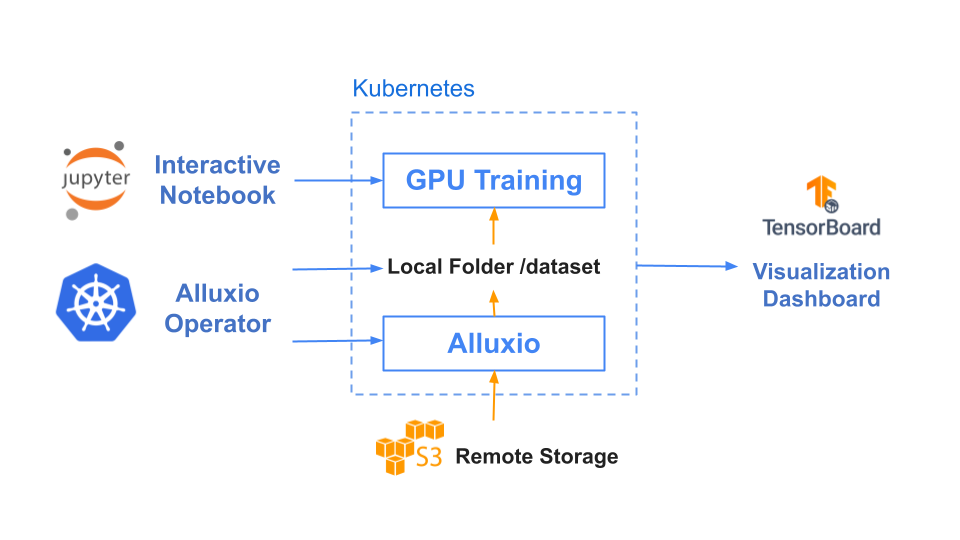
Test Setup:
- Alluxio – Kubernetes
- GPU server – AWS EC2/Kubernetes
- Deep learning algorithm (CV) – ResNet (one of the most popular CV algorithms)
- Deep learning framework – PyTorch
- Dataset – ImageNet (subset – ~35k images, each is ~100kB – 200kB)
- Dataset storage – S3 (single region)
- Mounting – FUSE
- Visualization – TensorBoard
- Code execution – Jupyter notebook
- Baseline – S3FS-FUSE
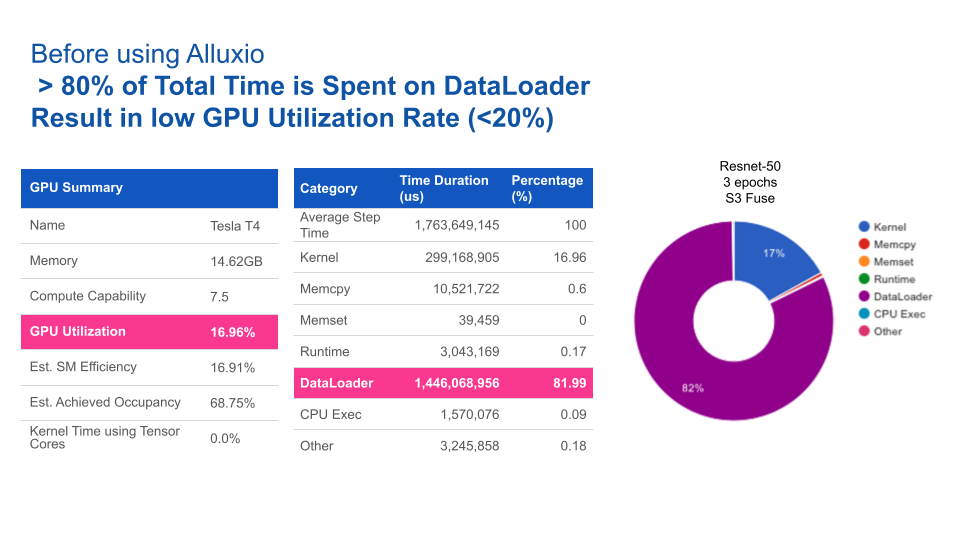
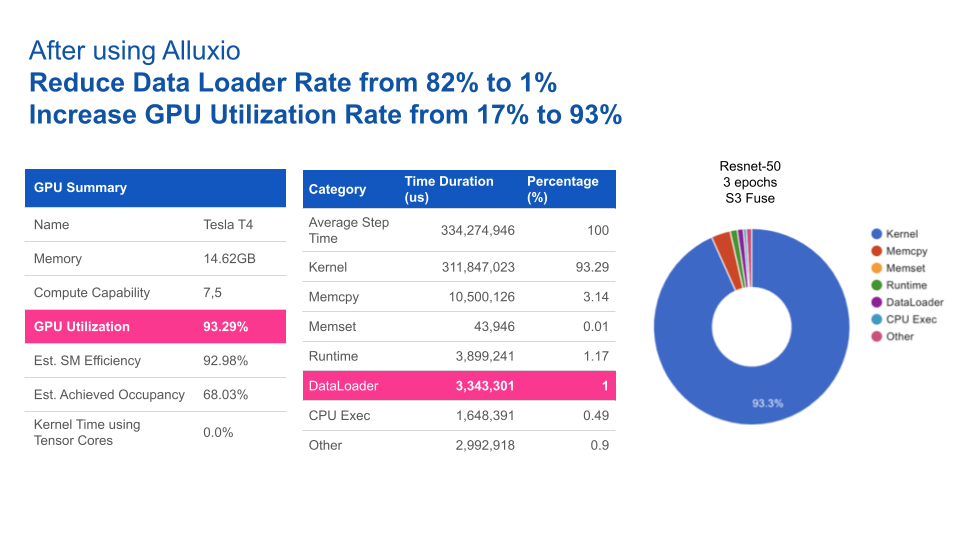
The following figures show the GPU utilization before and after using Alluxio. With Alluxio, GPU utilization improved significantly. Alluxio has reduced data loading time from 82% to 1%, increasing GPU utilization from 17% to 93%.
In production, a top online Q&A community with 400 million users in Asia accelerated LLM training with 90% GPU utilization. Read the blog for details: https://www.alluxio.io/blog/building-high-performance-data-access-layer-for-model-training-and-model-serving-for-llm/
4. Summary
Slow data access has become a significant bottleneck for GPU utilization in modern AI and machine learning workloads. The growing size of datasets, slow object storage, the “many small files” problem, and the geographical separation of computation and storage resources all contribute to sluggish data access, leading to idle GPU cycles and low utilization.
Alluxio Enterprise AI provides a solution to this challenge by enabling organizations to maximize the utilization of their existing GPU environments and accelerate the performance of their AI/ML workloads. With Alluxio, data platform engineers can derive the full benefit from their GPU infrastructures, concentrate on improving their models and applications without being limited by poor storage performance, and ensure that their expensive GPU resources are fully utilized to their full potential.
Our experts understand how to architect the end-to-end machine learning pipeline. Book a meeting to learn more about solutions tailored to your organization’s AI/ML needs.
Check out the following resources:
- Download the trial edition of Alluxio Enterprise AI now: https://www.alluxio.io/download/
- Watch the 3-minute product demo of solving the data loading challenge for machine learning with Alluxio: https://www.alluxio.io/resources/product-demo/solving-the-data-loading-challenge-for-machine-learning-with-alluxio/
- See how the FinTech giant serving 1.3 billion users speeds up large-scale computer vision training on billions of small files: https://www.alluxio.io/blog/optimizing-alluxio-for-efficient-large-scale-training-on-billions-of-files/
- Gain a comprehensive understanding of I/O patterns in each stage of the machine learning pipeline and the solutions that can be used in architecting your data and AI platform: https://www.alluxio.io/resources/whitepapers/efficient-data-access-strategies-for-large-scale-ai/
- Join the latest events and slack community with 8000+ data & AI infra experts: https://linktr.ee/Alluxio