This blog is the first in a series introducing Alluxio’s machine learning solution in model training. Blog 2 compares Alluxio with traditional solutions and explain how Alluxio differs. Blog 3 demonstrates how to set up and benchmark the end-to-end performance of the training process. For more details about the reference architecture and benchmarking results, please refer to the full-length white paper here.
Background: The Unique Requirements of AI/ML Model Training
With artificial intelligence (AI) and machine learning (ML) becoming more pervasive and business-critical, organizations are advancing their AI/ML capabilities and broadening the use and scalability of AI/ML applications. These AI/ML applications require data platforms to meet the following specific requirements:
I/O Efficiency for Frequent Data Access to Massive Number of Small Files
AI/ML pipelines are composed of not only model training and inference but also include data loading and preprocessing steps as a precursor, which have a major impact. In the data loading and preprocessing phase, AI/ML workloads often make more frequent I/O requests to a larger number of smaller files than traditional data analytics applications. Having a better I/O efficiency can dramatically increase the speed of the entire pipeline.
Higher GPU Utilization to Reduce Costs and Increase ROI
Model training is compute-intensive and requires GPUs to enable data to be processed quickly and accurately. Because GPUs are expensive, optimal utilization is critical. However, when utilizing GPUs, I/O becomes the bottleneck – workloads are bound by how fast data can be made available to the GPUs and not how fast the GPUs can perform training calculations. Data platforms need high throughput and low latency to fully saturate the GPU clusters to reduce the cost.
Natively Connect to Diverse Storage Systems
As the volume of data keeps growing, it gets more and more challenging for organizations to only have a single storage system. A variety of storage options are being used across business units, including on-premises distributed storage systems (HDFS, Ceph) and cloud storage (AWS S3, Azure Blob Store, Google Cloud Storage). Having access to all the training data spanning in different environments is necessary to make models more effective.
Support for the Cloud, Hybrid and Multi-Cloud infrastructure
In addition to supporting different storage systems, data platforms also need to support different deployment models. As the volume of data grows, cloud storage has become a popular choice with high scalability, reduced cost, and ease of use. Organizations want flexibility and openness to training models by leveraging available cloud, hybrid, and multi-cloud infrastructure. Also, the growing trend of separating compute resources from storage resources necessitates using remote storage systems. However, when storage systems are remote, data must be fetched over the network, bringing performance challenges. Data platforms need to achieve high performance while accessing data across heterogeneous environments.
In summary, today’s AI/ML workloads demand fast access to expansive amounts of data at a low cost in heterogeneous environments. Organizations need to modernize the data platform to enable those workloads to effectively access data, maintain high throughput and utilize the GPU resources used to train models.
Why Model Training with Alluxio
Alluxio is an open-source data orchestration platform for analytics and machine learning applications. Alluxio not only provides a distributed caching layer between training jobs and underlying storage, but also is responsible for connecting to the under storage, fetching data proactively or on-demand, caching data based on user-specified policy, and feeding data to the training frameworks.
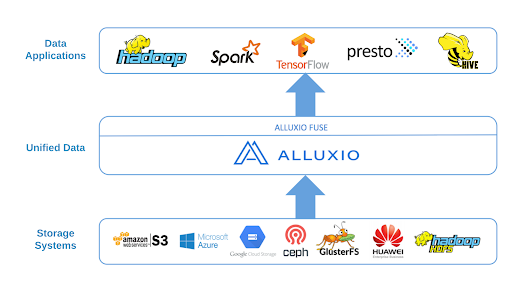
Alluxio provides a proven solution to meet the unique requirements of AI/ML training workloads. Alluxio offers a data orchestration platform, unifying data silos in heterogeneous environments, and allowing applications to fully utilize compute resources without encountering data access and I/O bottlenecks.
Fast Data Access, High Performance, High GPU Utilization
Alluxio provides optimizations for AI/ML workloads on billions of files to reduce latency and training time. By preloading the data and caching data locally or closer to the training jobs, Alluxio mitigates the I/O bottleneck, so the training pipeline maintains high performance and high data throughput. Training benefits from high data throughput when accessing data cached in Alluxio without the need to wait to fully cache the data before training.
With a high data throughput, the GPUs are kept busy without waiting for network I/O as data is cached locally on compute instances across different steps of the training pipeline. You will achieve better performance at a significantly lower cost with full utilization of compute resources.
Flexible Data Access Spanning Cloud, On-Prem, Hybrid, and Multi-cloud Environments
The separation of processing clusters for AI/ML from data storage systems is becoming increasingly attractive as it allows scaling storage independently of compute, to reduce both capital expenditures and operating expenses. Organizations may want to leverage the flexible compute resources on the public cloud and leave the data on-prem, or access the cloud object storage while using the on-prem compute resources. This disaggregated architecture introduces performance loss for certain types of workloads because of network latencies as data is not available locally for computation.
Alluxio enables separation of storage and compute with advanced caching and data tiering to enable faster and lower-cost data access for AI/ML workloads across cloud, on-prem, hybrid, and multi-cloud environments. Alluxio unifies multiple data storage into a logical data access layer that performs the same as local, which eliminates the data access friction.
Accelerate the Entire Data Pipeline
Alluxio is not only an advanced caching solution but also a data orchestration platform that bridges training/compute frameworks and underlying storage systems. Training with Alluxio not only benefits training but also other stages of the data pipeline, spanning ingestion, data preprocessing, and training.
Alluxio’s data orchestration platform spans the data pipeline from data ingestion to ETL to analytics and ML. By using Alluxio, one computation engine can consume the output of another by sharing data and storing intermediate results. The ability to share data between applications leads to further performance gains and fewer data movements. By leveraging Alluxio’s data management capabilities, the end-to-end pipeline of data preprocessing, loading, training, and output is all well supported.
Essentially, Alluxio eliminates the I/O bottleneck for data loading and preprocessing stages of AI/ML training pipelines to reduce end-to-end training times and costs. Alluxio is proven to achieve 9x improved I/O efficiency. For the reference architecture and benchmarking methodologies, refer to the full-length white paper here.
Model Training with Alluxio Solution Overview
Alluxio enables training connecting to remote storages via FUSE API and provides caching ability similar to storage FUSE applications. On top of that, Alluxio provides distributed caching for tasks or nodes to share cached data. Advanced data management policies like distributed data preloading, data pinning can further improve data access performance.
Distributed Caching
Instead of duplicating the entire dataset into each single machine, Alluxio implements a shared distributed caching service, where data can be evenly distributed across the cluster. This can greatly improve storage utilization especially when the training dataset is much larger than the storage capacity of a single node.
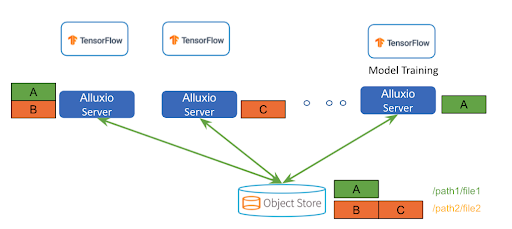
Metadata Operations
Alluxio provides its own metadata service by caching and acting as the proxy of the cloud storage for metadata operations requested by the training. In case the data is modified out of band at the cloud storage, Alluxio has the option to periodically synchronize and make sure the metadata is eventually consistent with the data source.
Advanced Data Management Policies
Alluxio provides a set of built-in data management policies to help manage the storage resource for data cache efficiently. There are different policies for users to leverage, including pluggable and transparent data replacement policies, pin and free working set in the cache, setting TTL (time-to-live) of data in cache, and data replication. By using these data policies, users can further control the data managed in Alluxio.
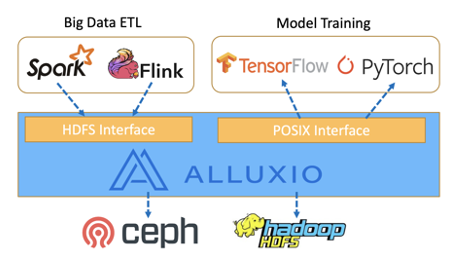
Support for Multiple APIs and Frameworks
Alluxio supports multiple APIs like the HDFS interface that is popular for big data applications e.g. Spark, Presto. The new POSIX interface is popular for training applications like PyTorch, Tensorflow, and Caffe. Users can use big data frameworks to preprocess data, store in alluxio, asynchronously persist to under storage, and at the same time use training frameworks to train models with preprocessed data in Alluxio.
The Evolution and Real-World Use Cases
Alluxio POSIX interface was an experimental feature first introduced in Alluxio v1.0 in February 2016, contributed by researchers from IBM. In the early days, this feature was mostly used by legacy applications that did not support the HDFS interface, evolving slowly in functionalities and performance. In early 2020, the surge of machine learning training workloads started to guide and drive the production-readiness of this feature. Particularly, Alluxio core team has been working closely with our open-source community including engineers from Alibaba, Tencent, Microsoft and researchers from Nanjing University. With the strong and efficient collaboration, hundreds of issues are addressed and major improvements introduced (e.g., JNI-based FUSE connector, Container Storage Interface, performance optimization on many small files).
Today, Alluxio supports the machine learning pipelines in production at the most data-intensive companies in the world. They have gained significant benefits with Alluxio integrated into their machine learning platforms.
Boss Zhipin
Boss Zhipin (NASDAQ: BZ) is the largest online recruitment platform in China. At Boss Zhipin, Alluxio is used as the caching storage for underlying Ceph and HDFS. Spark and Flink read data from Alluxio, preprocess the data, and then write back to Alluxio cache. In the backend, Alluxio persists the preprocessed data back to Ceph under storage and HDFS. Without waiting for writing to Ceph or HDFS to finish, training applications like Tensorflow, PyTorch, and other Python applications can read preprocessed data from Alluxio for training. Watch the talk (in Chinese) here.
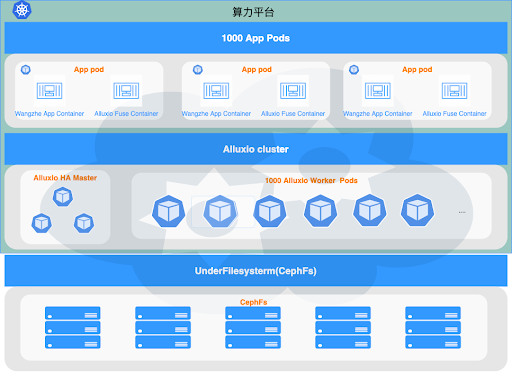
Tencent
Tencent deployed Alluxio in a cluster of 1000 nodes to accelerate the data preprocessing of model training on the game AI platform. The introduction of Alluxio significantly increased the concurrency of AI workloads at a low cost. There is no change to the applications since they are using POSIX API to access Alluxio. Read more here.
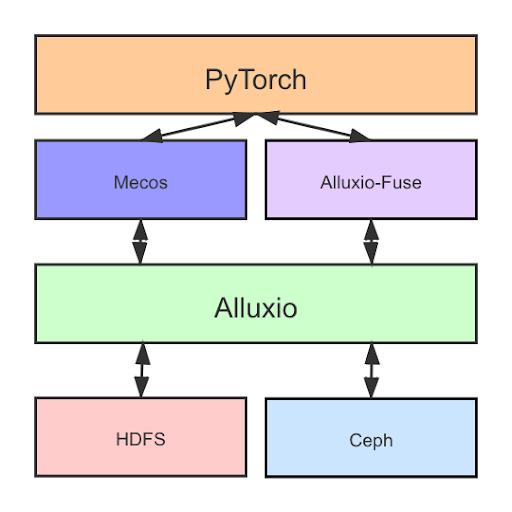
Microsoft Bing
The Microsoft Bing team used Alluxio to speed up large-scale ML/DL offline inference. By implementing Alluxio, they are able to speed up the inference job, reduce I/O stall, and improve performance by about 18%. Check out the presentation here.
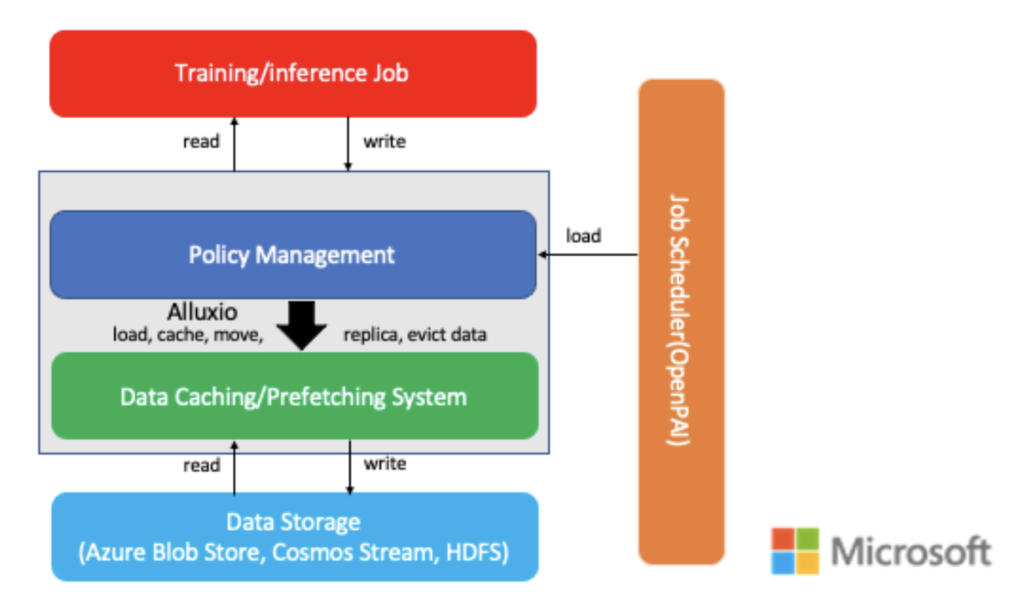
Unisound
Unisound is an AI company focusing on IoT services. Unisound used Alluxio as a cache layer between computing and storage in its GPU/CPU heterogeneous computing and distributed file system. With Alluxio, users can enjoy fast data access because Alluxio brings the underlying storage to memory or local hard drives on each computing node. The entire platform utilizes the resources of both the distributed file system and the local hard disk. Read more here.
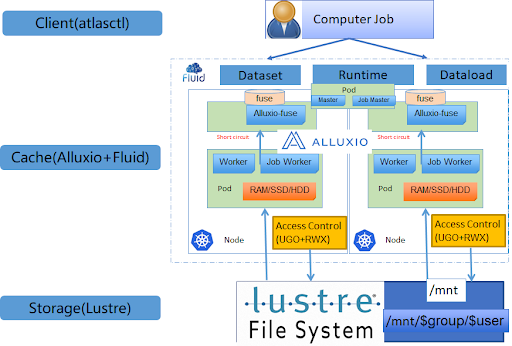
Momo
Momo (NASDAQ: MOMO) is the company that develops the popular mobile application that connects people and facilitates social interactions. Momo has multiple Alluxio clusters in production with thousands of Alluxio nodes. Alluxio has helped Momo to accelerate compute/training tasks and reduce the metadata and data overhead of under storage of billions of image training. Check out the presentation (in Chinese) here.
Ready to Get Started?
In this blog, we outlined Alluxio’s solution to improve training performance and simplify data management. In summary, Alluxio provides the following benefits:
- Distributed caching to enable data sharing between tasks and nodes.
- Unified data access across multiple data sources.
- End-to-end pipeline acceleration spanning ingestion, data preprocessing, and training.
- Advanced data management policies including data preloading and data pinning to further simplify data management and improve performance.
To learn more about the architecture and benchmarking, download the in-depth whitepaper, Accelerating Machine Learning / Deep Learning in the Cloud: Architecture and Benchmark. To get started with model training with Alluxio, visit this documentation for more details. Start using Alluxio by downloading the free Alluxio Community Edition or a trial of the full Alluxio Enterprise Edition here for your own AI/ML use cases.
Feel free to ask questions on our community slack channel. If you want to develop open-source Alluxio for machine learning, we have bi-weekly community development sync, you are welcome to join us.