Author: Shaofeng Shi (shaofeng@kyligence.io), Senior Architect, Kyligence Inc.
OLAP (on-line analytical processing) technology has been widely adopted by enterprises since last century; Enterprises rely on OLAP to analyze their huge amount of data, generate reporting and so to help business people making decisions. Today in the era of big data, OLAP becomes more important and challenging than ever before; and cloud computing makes this further true. This article introduces how Kyligence, a cutting-edge big data intelligence company, leverages Alluxio to boost their performance in the cloud.
Background
Founded in 2016, Kyligence Inc. [1] is a big data intelligence company that offers solutions for big data analytics. Kyligence’s product is based on open source technology of Apache Kylin.
Apache Kylin [2] is an open-source OLAP engine that is built for interactive analytics of petabyte-scale data on Hadoop (Apache Hadoop is an open-source software framework used for distributed storage and processing of big datasets). Apache Kylin builds huge data set into OLAP Cubes with Hadoop’s parallel computing capability, and then provides sub-second low latency response through an ANSI-SQL query interface.
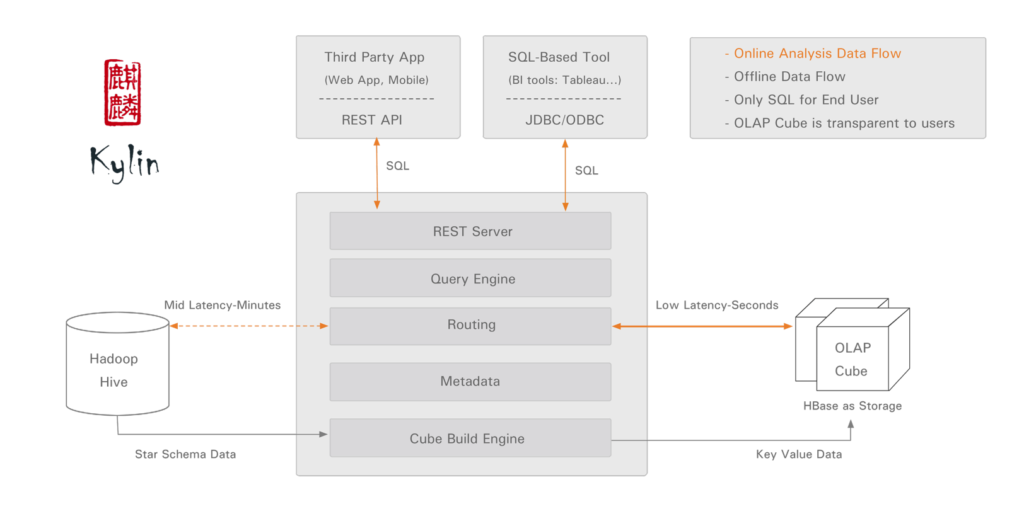
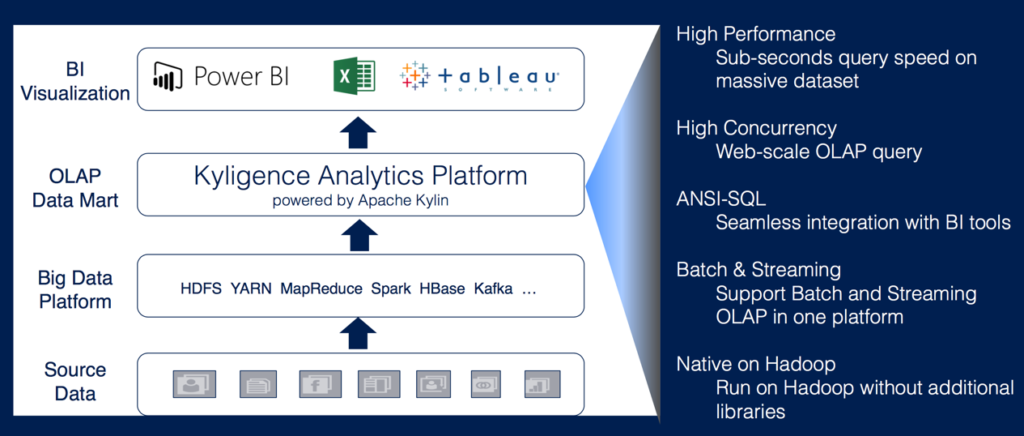
Kyligence’s flagship product is the Kyligence Analytics Platform (KAP), powerd by Apache Kylin with more enterprise-level features. With KAP, users can access business intelligence (BI) capabilities on Hadoop with industry-standard methodologies for data warehouse and BI operations. As part of this, KAP simplifies analytics by providing self-service, seamless interoperability with popular BI tools – no programming is required.
Challenges in the Cloud
KAP leverages Hadoop MapReduce and Spark to build source data into OLAP Cubes; The OLAP Cubes are persisted into KyStorage. KyStorage is an optimized columnar storage format on the distributed file system like HDFS. When SQL query comes, KAP translates it to the execution plan in Spark executors over KyStorage.
In an on-premises cluster, HDFS is the most widely adopted filesystem for Hadoop and Spark. With the data locality and OS file cache, the performance of HDFS is good; and with the file replicate default being 3, the availability is also acceptable.
While on Cloud, HDFS is not the best choice. The cluster is provisioned on demand and can be scaled out and in by workload metrics. The local disks of the virtual machines will be erased when a node is stopped, which may lead to data lost. In this case, cloud storage services like AWS S3 and Azure Blob Store, with nearly unlimited capacity and more than 99.999% SLA, become good alternatives. Hadoop products like AWS EMR and Azure HDInsight have provided native support for these storage services. User can transparently access them from MapReduce, Spark or custom applications just like a normal distributed file system.
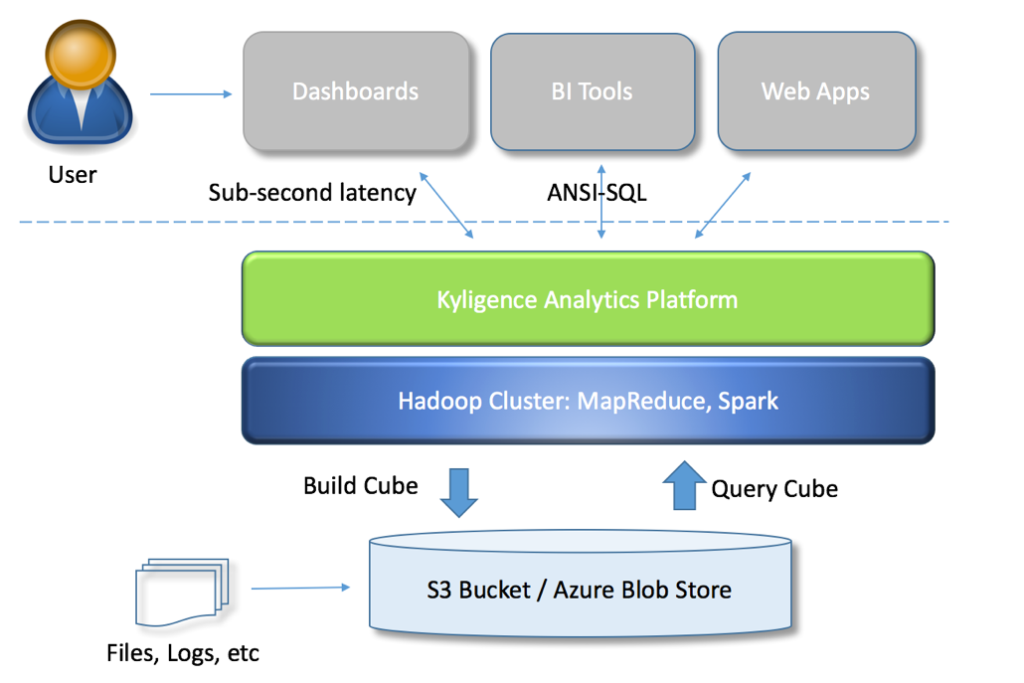
Although cloud storage services provide much better scalability and durability than HDFS, its performance is limited by the network bandwidth of the VMs that you rent. Besides, the cloud storage service like S3 is not a real file system; its meta data operation like ‘list’ is heavy, and ‘rename’ is really a ‘copy’. All these make the overall performance be away from HDFS.
KAP, as an extreme OLAP engine, relies heavily on the performance of the distributed file system. Before introducing Alluxio, we have to endure a performance downgrade when moving to Cloud or need do extra copy between S3 and HDFS to get a balance between performance and durability, which makes the deployment and maintenance complicated and error-prone.
How KAP leverages Alluxio
To overcome the storage limitations on cloud, we were planning to add a cache layer over the storage services for KyStorage. Then we noticed Alluxio.
Alluxio [3], formerly known as Tachyon, is the world’s first memory speed virtual distributed storage system. It unifies data access and bridges computation frameworks and underlying storage systems. Applications only need to connect with Alluxio to access data stored in any underlying storage systems. Additionally, Alluxio’s memory-centric architecture enables data access at speeds that is orders of magnitude faster than existing solutions.
In the big data ecosystem, Alluxio lies between computation frameworks or jobs, such as Apache Spark, Apache MapReduce, Apache HBase, Apache Hive, or Apache Flink, and various kinds of storage systems, such as Amazon S3, Google Cloud Storage, OpenStack Swift, GlusterFS, HDFS, MaprFS, Ceph, NFS, and Alibaba OSS. Alluxio brings significant performance improvement to the ecosystem. Alluxio is Hadoop compatible. Existing data analytics applications, such as Spark and MapReduce programs, can run on top of Alluxio without any code change.
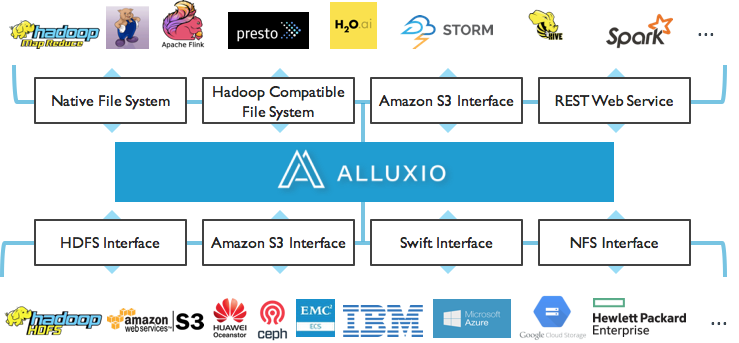
Furthermore, Alluxio provides tiered storage which can manage SSDs and HDDs in addition to memory, allowing larger datasets to be stored in Alluxio. Data will automatically be managed between the different tiers, keeping hot data in faster tiers.
With Alluxio, we do not need code or architecture change. Install Alluxio into the nodes where Spark runs, and then mount S3 bucket or Azure Blob Store as its underlying file system. After that, we configure KAP to go through Alluxio file system to read the KyStorage files on S3 or blob store. The first load might be a little slow as Alluxio needs read the data into memory. But the subsequent accessing is much faster than before, because Alluxio can smartly return the data blocks from the local worker where the Spark executor runs.
Here is the architecture after adding Alluxio:
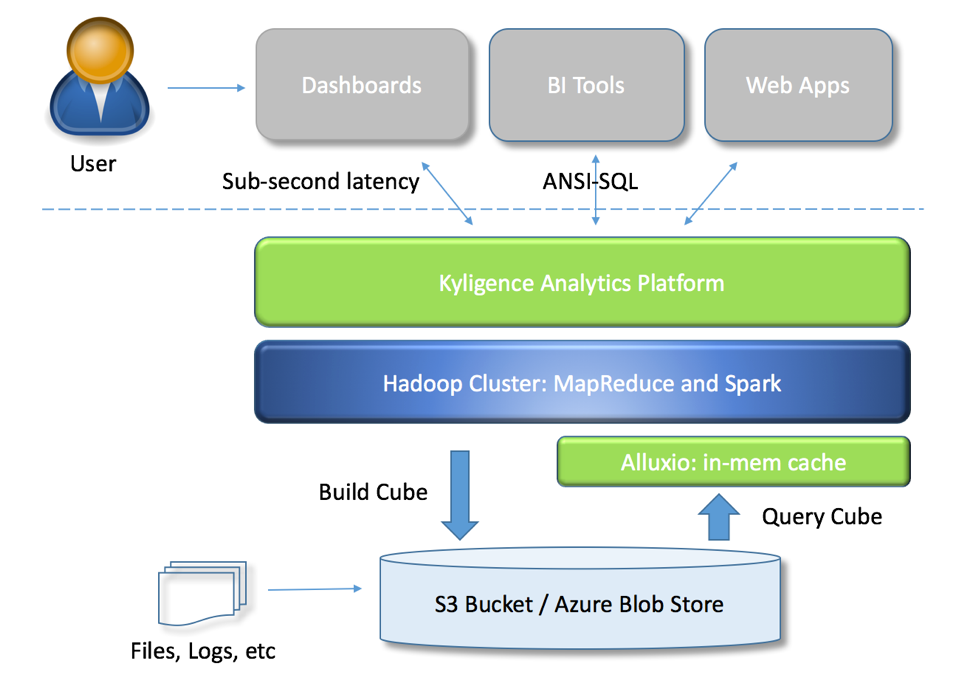
With hot data being cached in Alluxio, the performance of reading KyStorage can be boosted, thus improving the query performance and throughput significantly. We did benchmarks on AWS and Azure separately, the result verified this assertion.
Benchmarks on AWS S3
Test information:
| Test data set | Star Schema Benchmark [4] |
| Rows | 91 millions |
| Cube size (KyStorage) | 20 GB |
| Hadoop | AWS EMR 5.7 Master: 1, m4.xlargeCore: 1, m4.2xlargeTask: 2, m3.xlargeEdge: 1, m4.xlarge |
| KAP | KAP Plus 2.5.1, disabled query cache |
| Alluxio | 1.6.0, with 5GB memory on each worker |
| Benchmark tool | JMeter 3.3 with KAP JDBC driver; Run 13 queries repeatedly in 10 threads for 10 minutes |
Apache JMeter runs the SSB queries against KAP, with query cache disabled, so each time it needs read the KyStorage from storage. We collected the query performance on S3 and on Alluxio (with S3 as underlying FS) separately. Below are the statistics of running SSB on S3 and Alluxio.
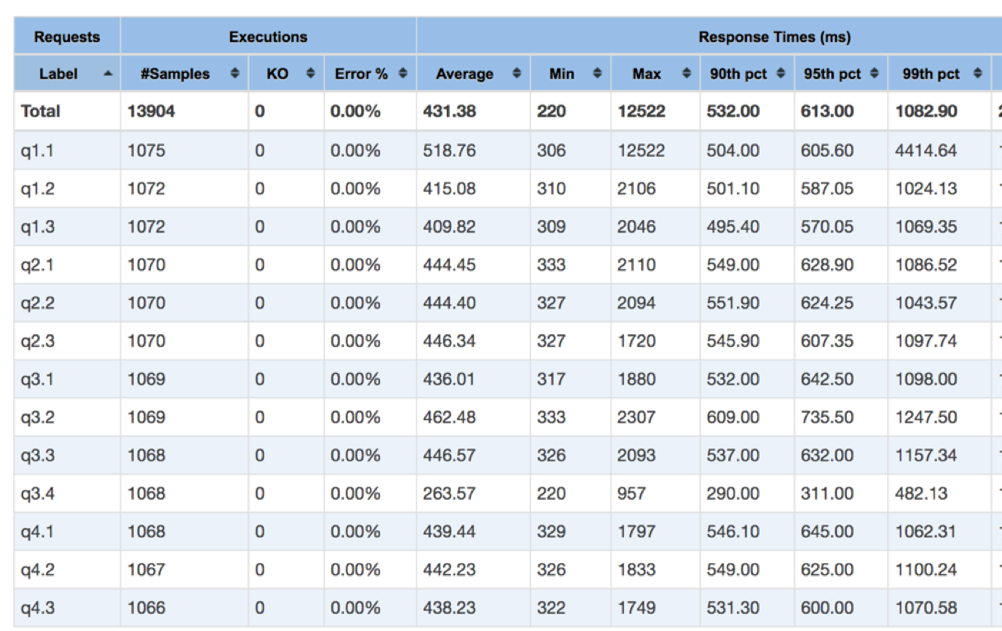
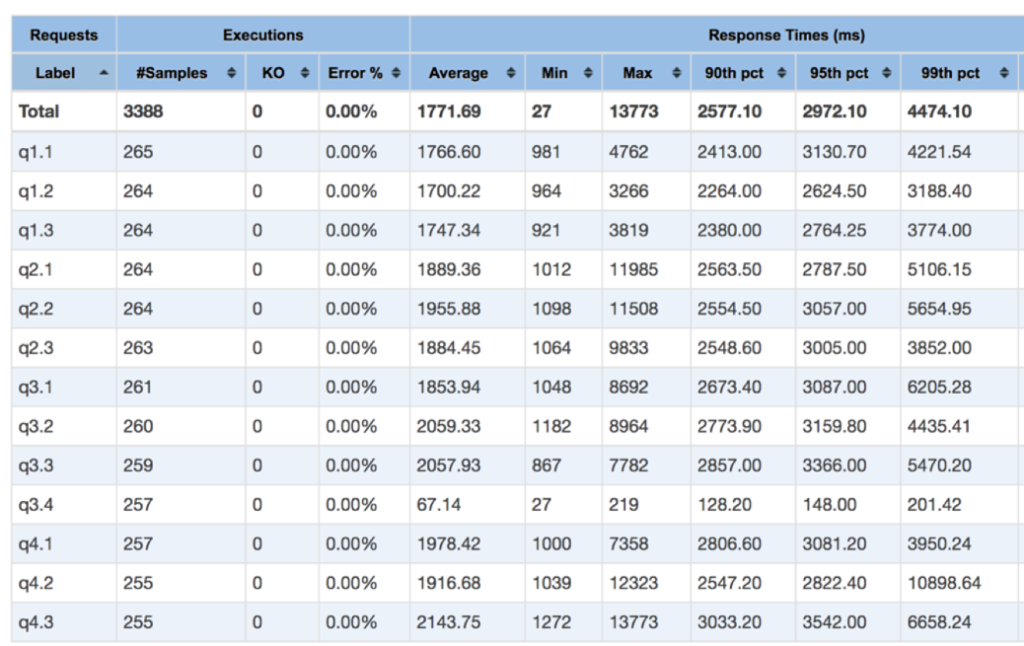
After comparing the average query latency for all queries, we get the following chart:
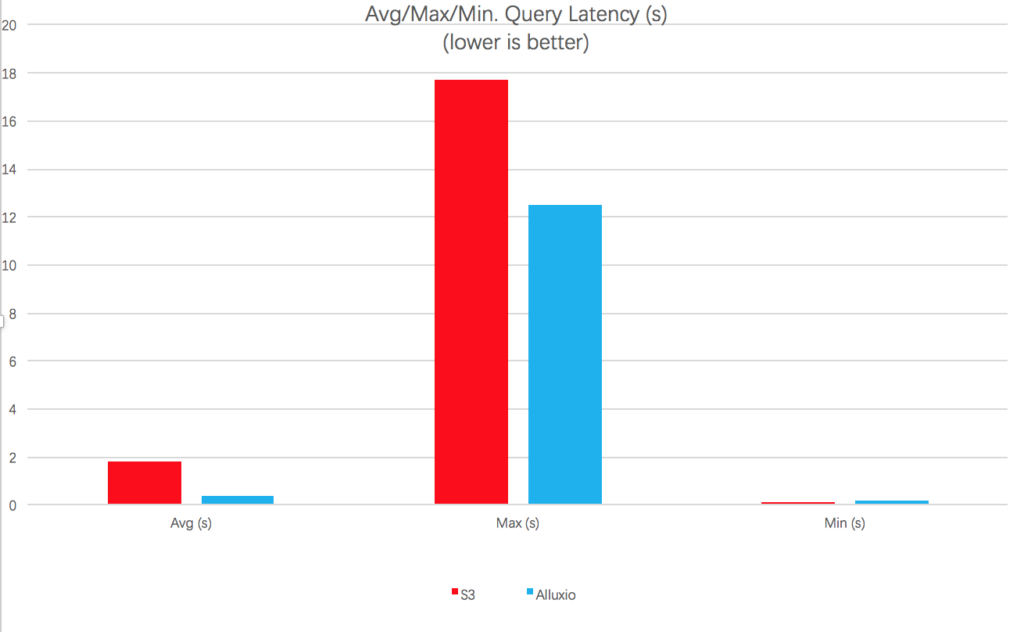
It can be seen from the above figure that the average query latency is 0.4 seconds on Alluxio, and 1.8 seconds on S3. KAP on Alluxio shows 4x faster performance than directly on S3. Even the slowest query is still a little bit faster than on S3.
Benchmarks on Azure blob store
In oder to understand the performance of Alluxio on Windows Azure Storage Blobs (WASB), we made another test. This time we selected a real scenario (user profile), and added HDFS in the comparison. The sample queries were collected from a web application. We ran the query multiple times to get an average time.
Test information:
| Test data set | Kyligence user profile data |
| Rows | 200 millions |
| Cube size (KyStorage) | 15 GB |
| Hadoop | Azure HDInsight 3.5 Master: 2, D3Worker: 4, D3Edge: 1, D4 |
| KAP | KAP Plus 2.5.1, disabled query cache |
| Alluxio | 1.6.1, with 2GB memory on each worker |
The sample queries are:
| Q1 (massin query, return the id of the result collection) | select device_id from user_domain_new where domain_id in (1011007,1081088,1091093) group by device_id |
| Q2 | select count() as uv from usr where massin(device_id, ‘lFCgcArPtcPSVdqiVnEh’) |
| Q3 | select sum(time_all)/24055/60/60 as total_time, sum(count_all)/24055 as uv from user_app where massin(device_id, ‘lFCgcArPtcPSVdqiVnEh’) |
| Q4 | select count() as uv from usr where sex_id = 110102 and massin(device_id, ‘lFCgcArPtcPSVdqiVnEh’) |
| Q5 | select sum(time_all)/15046/60/60 as total_time, sum(count_all)/15046 as uv from user_app where sex_id = 110102 and massin(device_id, ‘lFCgcArPtcPSVdqiVnEh’) |
Here is the average time of the queries on three storage systems.
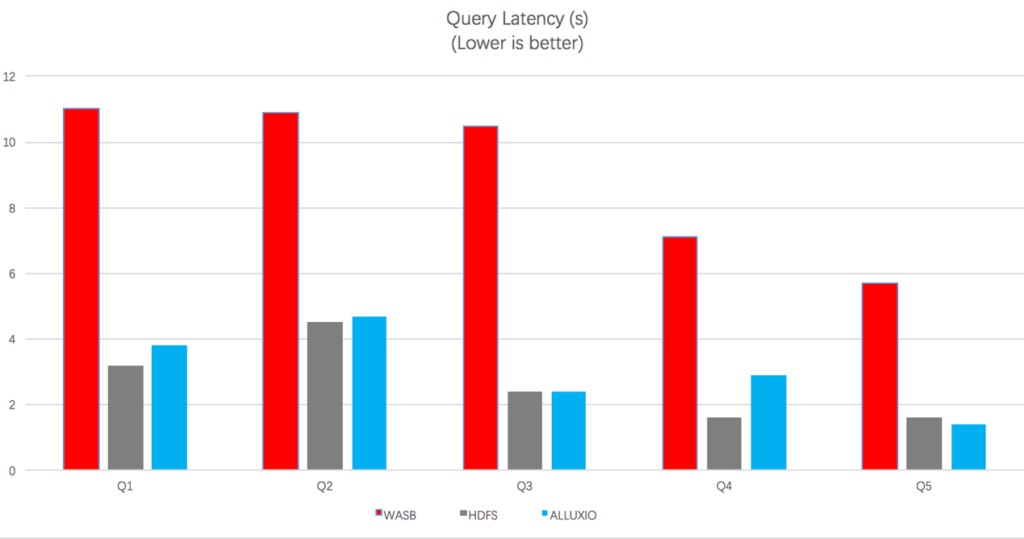
It can be seen from the above figure that local HDFS has the best performance in 4 out of 5 scenarios, and Azure blob store takes the longest time in all cases. Alluxio’s performance is between HDFS and blob store, but very close to HDFS. On average, Alluxio can help KAP getting 3x to 4x performance improvement than directly reading Azure blob store.
Summary
Alluxio enables effective data management across different storage systems through its use of transparent naming and mounting API. With Alluxio, KAP can gain a good balance between performance, cost and management effort in the Cloud.
References
[1] Kyligence: http://kyligence.io/
[2] Apache Kylin: https://kylin.apache.org/
[3] Alluxio: https://www.alluxio.org/
[4] SSB-Kylin: https://github.com/Kyligence/ssb-kylin