In the previous tutorial ”Getting Started with Spark Caching using Alluxio in 5 Minutes”, we demonstrated how to get started with Spark and Alluxio. To share more thoughts and experiments on how Alluxio enhances Spark workloads, this article focuses on how Alluxio helps to optimize the memory utilization of Spark applications.
For users who are new to Spark, it may not be immediately obvious the difference between storing data in-memory but off-heap as opposed to directly caching data in the Spark JVM. To illustrate the overhead of the latter approach, here is a fairly simple experiment:
- Start a local Spark shell with a certain amount of memory
- Check the memory usage of the Spark process before carrying out further steps
- Load a large file into Spark Cache.
- Check the memory usage of this Spark process to see the impact
Note that,
- We start with a single machine running spark-shell interactively. With distributed systems, sometimes it is better to start off small on a single machine as opposed to trying to figure out what is happening in a larger cluster.
- We are going to use the Resident Set Size or RSS memory size to measure the main-memory usage of the Spark application before and after
Prerequisites
- Install Alluxio 2.1.0
- Install Spark 2.4.4
- Download and untar sample data files to /tmp
Spark Caching
Let us start a Spark shell with a max heap size for the driver of 12GB. Check the amount of memory used before and after we load the file into Spark.
# Launch Spark shell with certain memory size$ bin/spark-shell --driver-memory 12g
Check memory size with uid, rss and pid. The following command example works on Mac OS X but the corresponding command on Linux may vary.
$ ps -fo uid,rss,pid
If you are not sure which entry corresponds to your Spark process, run “jps | grep SparkSubmit” to find it out.
After launching the shell, run the following command to load the file into Spark.
scala> val sampleRdd = sc.textFile("file:///tmp/sample-100m")
scala> sampleRdd.cache()
scala> sampleRdd.count()
Note that,
- Spark uses lazy execution, so
sampleRdd.cache()method tells Spark to cache this data in the JVM, but nothing is done until an action is called. In this case, we can use thesampleRdd.count()operation to initiate action and cache the data in Spark. .cache()method is a shortcut for.persist(memory_only)but data can be persisted to disk as well as memory by.persist(MEMORY_AND_DISK).
Once RDD is cached into Spark JVM, check its RSS memory size again
$ ps -fo uid,rss,pid
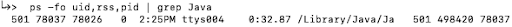
In the example above, Spark has a process ID of 78037 and is using 498mb of memory.
Repeat the above process but varying sample data size with 100MB, 1GB, 2GB, and 3GB respectively. the table below summarizes the measured RSS memory size differences. One can observe a large overhead on the JVMs memory usage for caching data inside Spark, proportional to the input data size.
| Input Size | 100MB | 1GB | 2GB | 3GB |
| Spark RSS Initially | 670mb | 705mb | 712mb | 709mb |
| Spark RSS After cache() | 907mb | 5.3gb | 8.08gb | 11.2gb |
| RSS used for RDD caching | 237mb | 4.6gb | 7.36gb | 10.5gb |
Using Alluxio as In-Memory Off-heap Storage
Start Alluxio on the local server. By default, it will use Ramdisk and ⅓ of the available memory on your server.
$ bin/alluxio-start.sh local -f
Use Spark shell using 12GB memory and specify –driver-class-path to put Alluxio client jar on classpath:
$ bin/spark-shell --driver-memory 12g \
--driver-class-path ${ALLUXIO_HOME}/client/alluxio-2.1.0-client.jar
Now load the input into Spark but save the RDD into Alluxio.
scala> val sampleRdd = sc.textFile("file:///tmp/sample-100m")
scala> sampleRdd.saveAsTextFile("alluxio://localhost:19998/cache")
You can double-check the results on Alluxio by listing the output files of this RDD as well as its total size
$ bin/alluxio fs ls /cache
-rw-r--r-- binfan staff 0
PERSISTED 10-29-2019 00:12:54:438 100% /cache/_SUCCESS
-rw-r--r-- binfan staff 33554451
PERSISTED 10-29-2019 00:12:42:218 0% /cache/part-00000
-rw-r--r-- binfan staff 33554481
PERSISTED 10-29-2019 00:12:42:162 0% /cache/part-00001
-rw-r--r-- binfan staff 33554372
PERSISTED 10-29-2019 00:12:42:103 0% /cache/part-00002
$ bin/alluxio fs du -h -s /cache
File Size In Alluxio Path
100.79MB 100.79MB (100%) /cache
As shown in the table below, one can see that when data is cached into Alluxio space as the off-heap storage, the memory usage is much lower compared to the on-heap approach.
| Input Size | 100MB | 1GB | 2GB | 3GB |
| Spark RSS Initially | 804mb | 773mb | 776mb | 788mb |
| Spark RSS After saveAsTextFile() | 1.0gb | 1.8gb | 2.1gb | 2.2gb |
| RSS used | 245mb | 1.0gb | 1.4gb | 1.5gb |
| Size of RDD cache on Alluxio | 100mb | 1.0gb | 2.0gb | 3.0gb |
Summary
There are a few items to consider when deciding how to best leverage memory with Spark.
- Production applications will have hundreds if not thousands of RDDs and Data Frames at any given point in time.
- You can increase the max heap size for the Spark JVM but only up to a point. We recommend keeping the max executor heap size around 40gb to mitigate the impact of Garbage Collection.
- Caching data in Spark heap should be done strategically.
- Unlike HDFS where data is stored with replica=3, Spark data is generated by computation and can be recomputed if lost. If it will be extremely expensive to recompute, it may make sense to persist this data in cache or Alluxio.
- Trying to cache data that is too large will cause evictions for other data.
Keeping these points in mind, Alluxio can be used as a storage optimized way to compliment Spark Cache with off-heap memory storage. If you are not sure about your use case, feel free to raise your hands at our Alluxio community slack channel.