This blog is authored by Bin Fan and Amelia Wong originally posted on medium.
Over the years of working in the big data and machine learning space, we frequently hear from data engineers that the biggest obstacle to extracting value from data is being able to access the data efficiently. Data silos, isolated islands of data, are often viewed by data engineers as the key culprit or public enemy №1. There have been many attempts to do away with data silos, but those attempts themselves have resulted in yet another data silo, with data lakes being one such example. Rather than attempting to eliminate data silos, we believe the right approach is to embrace them.
Why Data Silos Exist
There are three main reasons why data silos exist. Firstly, within any organization there is data with varying characteristics (IOT data, behavioral data, transactional data etc.) that are intended for different uses, and some data will be more business critical than others. The above drives the need for disparate storage systems.
Additionally, history has shown that every five to ten years there will be a new wave in storage technologies churning out storage systems that are faster, cheaper or better designed for certain types of data. Organizations also have a desire to avoid vendor lock-ins, and as a result they will diversify their data storage. Finally, there are regulations that mandate the siloing of data.
For all the above reasons, each new storage system inevitably becomes yet another data silo in the data environment.
Attempts To Eliminate Silos
For years, there have been many attempts to resolve the challenges caused by data silos, but these attempts have resulted in even more data silos. For example, data engineers often build pipelines using Apache Spark or Apache Hive to process and export data from one Hadoop cluster to another (possibly remote or owned by a different department) in order to aggregate data sets needed by downstream data processing applications. However, this type of data migration pipelines (often ETL pipelines) are complicated to build and maintain, and also create duplication across different clusters.
Embracing Data Silos
We believe data silos in themselves are not the challenge; the fundamental challenge is how to make data accessible to data engineers without creating more complexity or duplication. Instead of eliminating the silos, we propose leveraging a data orchestration system, which sits between compute frameworks and storage systems, to resolve data access challenges. We define a data orchestration system as a layer that abstracts data access across storage systems, virtualizes all the data, and presents the data via standardized APIs with global namespace to data-driven applications.
With a data orchestration system, data engineers can easily access data stored across various storage systems. For example, a data engineer may need to join two tables originally stored in two different regions — a local Hadoop cluster and a remote Hadoop cluster. In this case, this engineer can deploy Alluxio as the data orchestration layer and change the table location in Hive metastore to Alluxio URLs rather than each individual physical Hadoop cluster.
As a result, caching the remote table in Alluxio provides much better performance than repeatedly reading the table directly. Furthermore, storage teams can make the best storage purchasing decisions without being shackled by the impact of their decisions on application teams.
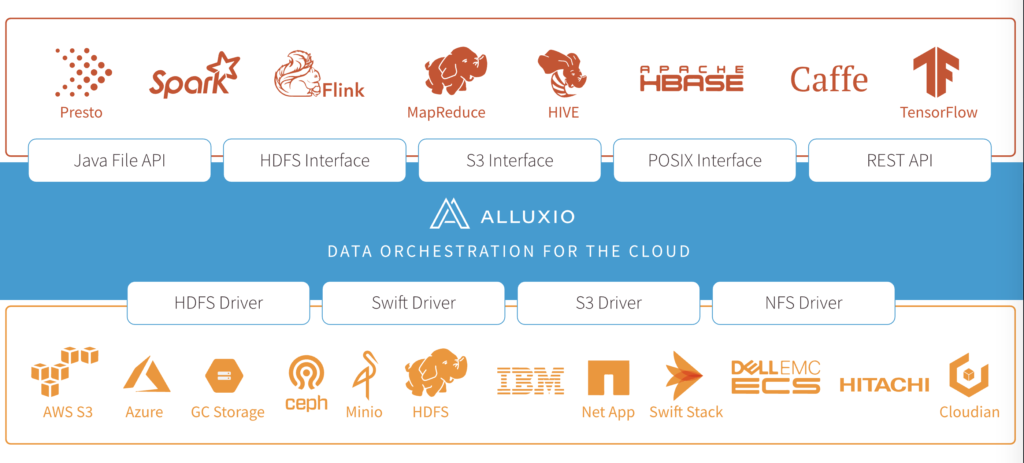
Hope folks who are on a quest to improve data access have found this blog to be helpful. For the past several years, we have been working on Alluxio, an open source implementation of a data orchestration layer. Alluxio has over 1000 contributors globally and we welcome all to join the Alluxio open source community!