This blog is authored by Dipti Borkar originally posted on medium.
Cloud has changed the dynamics of data engineering as well as the behavior of data engineers in many ways. This is primarily because a data engineer on premise only dealt with databases and some parts of the hadoop stack.
In the cloud, things are a bit different. Data engineers suddenly need to think different and broader. Instead of being purely focused on data infrastructure, you are now almost a full stack engineer (leaving out the final end application perhaps). Compute, containers, storage, data movement, performance, network — skills are increasing needed across the broader stack. Here are some design concept and data stack elements to keep in mind.
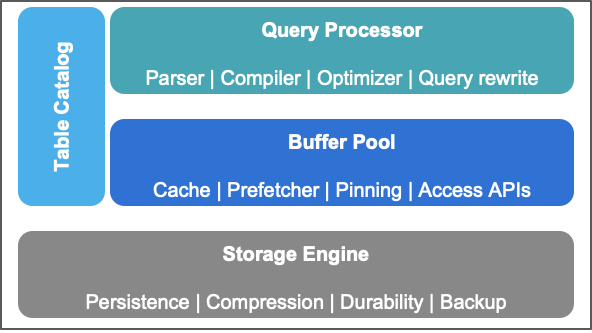
1. The disaggregated data stack — pick a compute, a catalog, a buffer pool, a storage.
Historically databases were tightly integrated with all core components built together. Hadoop changed that with co-located compute and storage in a distributed system instead of being in a single or a few boxes. Cloud changed that. Today, it is a fully disaggregated stack with each core element of the database management system being its own layer. Pick each component wisely.
2. Orchestrate, orchestrate, orchestrate
Cloud has created a need for and enabled mass orchestration — whether is Kubernetes for containers, Alluxio for data, Istio for APIs, Kafka for events, Terraform for scripting.
Efficiency dramatically increasing by abstracting and orchestration. Since now a data engineer for the cloud has full stack concerns, orchestration can be a data engineers best kept secret.
3. Copying data creates more problems than it solves
Fundamentally, once data lands into the enterprise, it should not be copied around unless of course for backup, recovery, disaster recovery scenarios. Making this data accessible to as many business units, data scientists & analysts with as few new copies created is THE data engineering puzzle to solve.
This is where in the legacy DBMS world, a buffer pool helped, making sure the compute (query engine) always had access to data stored in a consistent, performant way in a format that was suitable for the query engine to process versus a format optimized for storage. Technologies like Alluxio can dramatically simplify life bringing data closer to compute making it more performant and accessible.

4. S3-compatible in the cloud, S3-compatible on premise
Because of the popularity of AWS S3, object stores in general will be the next dominant storage system — at least for a few years (5–8 year cycle typically). Think forward see pick a storage tier that will last for sometime and S3-compatible object stores should be your primary choice. While they are not great at all data-driven workloads many technologies help remove their deficiencies.
5. SQL and structured data is still in!
While SQL has existed since the 1970s, it still is the easiest way for analysts to understand and do something with data. AI models will continue to evolve, but SQL has lasted close to 50 years. Pick 2, at most 3 frameworks to bet on and invest in. But build a platform that will over time support as many as needed. Currently presto sql is turning into a popular query engine pick for the disaggregated stack.