Data caching is essential to the modern data stack, allowing organizations to access data quickly and efficiently for analytics and AI. On June 28, 2023, we presented Data Caching Strategies for Data Analytics and AI at Data+AI Summit 2023. We are excited to bring you a recap of that presentation through this blog post. We will walk you through various approaches to data caching for AI and analytics workloads and explore how they can be used as a key component in your data infrastructure.

1. Background
The increasing popularity of data analytics and artificial intelligence (AI) has led to a dramatic increase in the volume of data used in these fields, creating a growing need for enhanced computational and storage capability.
Regardless of which workloads you are running, data analytics for gaining insights, or AI for training machine learning models, data caching plays a crucial role in accelerating computations. However, it is important to note that data analytics and AI have different traffic patterns, requiring distinct caching strategies.
Over the years, we have learned best practices of caching strategies from large tech companies worldwide, including Uber, Meta, ByteDance, Shopee, AliPay, etc. This blog will discuss cache strategies to accommodate analytics and AI workloads.
2. Traffic Pattern for AI Training and Cache Strategy Recommendation
2.1 Data Access Patterns
We have identified two scenarios for data access patterns in AI training workloads based on our observations on multiple production datasets from tech companies.
- Scenario A: Data is stored in some large structured files. Position or random reads are more frequent than sequential reads, and block access is almost evenly distributed. This is because model training often involves sampling and randomly selecting blocks of data. Each read from these large structured files is usually small.
- Scenario B: Data is stored in many small semi-structured/unstructured files. This is common in computer vision jobs. The number of files can be extremely large, with access to each file almost evenly distributed. Each read may involve a batch of files.
To cater to the above scenarios, we recommend the following cache strategies:
- Use hierarchical caching to improve performance: Improve performance using local caching on training nodes and remote caching for larger volumes of data. Optimize random reads, such as chunk-based caching, in fixed sizes rather than random sizes requested by clients. Note that this approach comes with a trade-off known as read amplification, where the returned data may exceed the client’s actual needs. Balancing these trade-offs is crucial in practice.
- The cache should be scalable/elastic: The cache should be able to grow/shrink to handle varying workloads and allocate resources accordingly. Two commonly used design principles are the masterless and master-worker patterns, each serving different needs. By implementing the appropriate design, we can effectively serve diverse requirements.
Using Alluxio as the data cache, we evaluated both scenarios.
- Scenario A (large structured files): We evaluated a production machine learning dataset and observed that the position reads outperformed the streaming reads. This means that using a position read is more effective when dealing with large machine learning datasets.
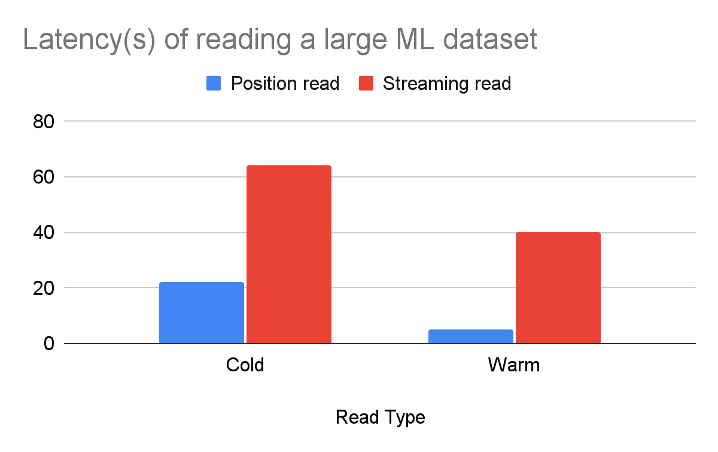
- Scenario B (small unstructured files): We trained a computer vision model using >10k structured image files, each of which is ~100 KB. We ran both position and streaming reads on a subset of the dataset. Interestingly, the streaming read performed slightly better in this case. This suggests that for scenarios with a large number of small and structured files, the traditional streaming read is still the preferred method.

2.2 Hybrid/Multi-Cloud for ML Infrastructure
There has been a growing trend to move machine learning infrastructure from on-premises environments to cloud environments in recent years. This results in a hybrid or multi-cloud infrastructure.
In a hybrid or multi-cloud infrastructure for machine learning, we have a training platform, storage, and online machine learning serving platform. To expedite the training process, a unified cache layer plays a crucial role in loading the dataset from the remote storage to the training clusters. Similarly, when the training is complete, the cache layer assists in loading the models for serving purposes. Below is a diagram showing how it works.
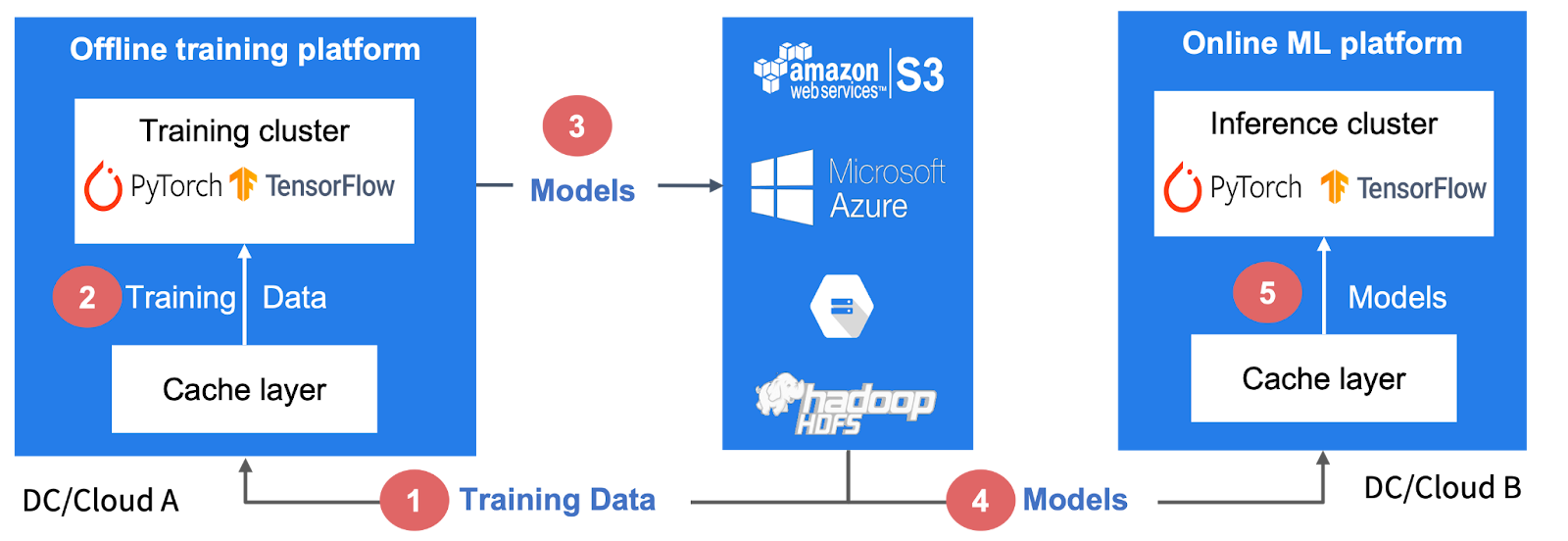
In these scenarios, we need such caching design:
- A cloud-friendly cache that can adapt to hybrid or multi-cloud environments. Furthermore, configurable cache admission and eviction policies are essential to fine-tuning cache behavior for optimized performance.
- Availability is another critical aspect. We must ensure that cache integration avoids single points of failure and supports fallbacks to end storage in case of any cache issues or offline scenarios.
Below is an example of how the cache can be integrated with an AI training platform. Let’s envision a setup where a training node runs the training jobs. This training node communicates with a cache client deployed on the same node. In the middle is a remote cache cluster with multiple cache workers. When the training node requests a specific data set, it first checks the local cache. If the data is present, it is returned. If not, the training node communicates with the remote cache workers and, if necessary, the under storage to load the data into the cache. This integration speeds up AI training jobs by optimizing data retrieval and utilization.

By optimizing cache usage in data access and AI training scenarios, we can significantly enhance overall system performance, scalability, and flexibility.
Looking ahead, we believe that integrating a unified data cache layer, like Alluxio, into different components of the machine learning life cycle, including data pre-processing, feature engineering, model training, and model serving, holds promising potential. This could involve storing processed data, features, and models in the cache and even utilizing the cache to write the inference results to the under storage systems.
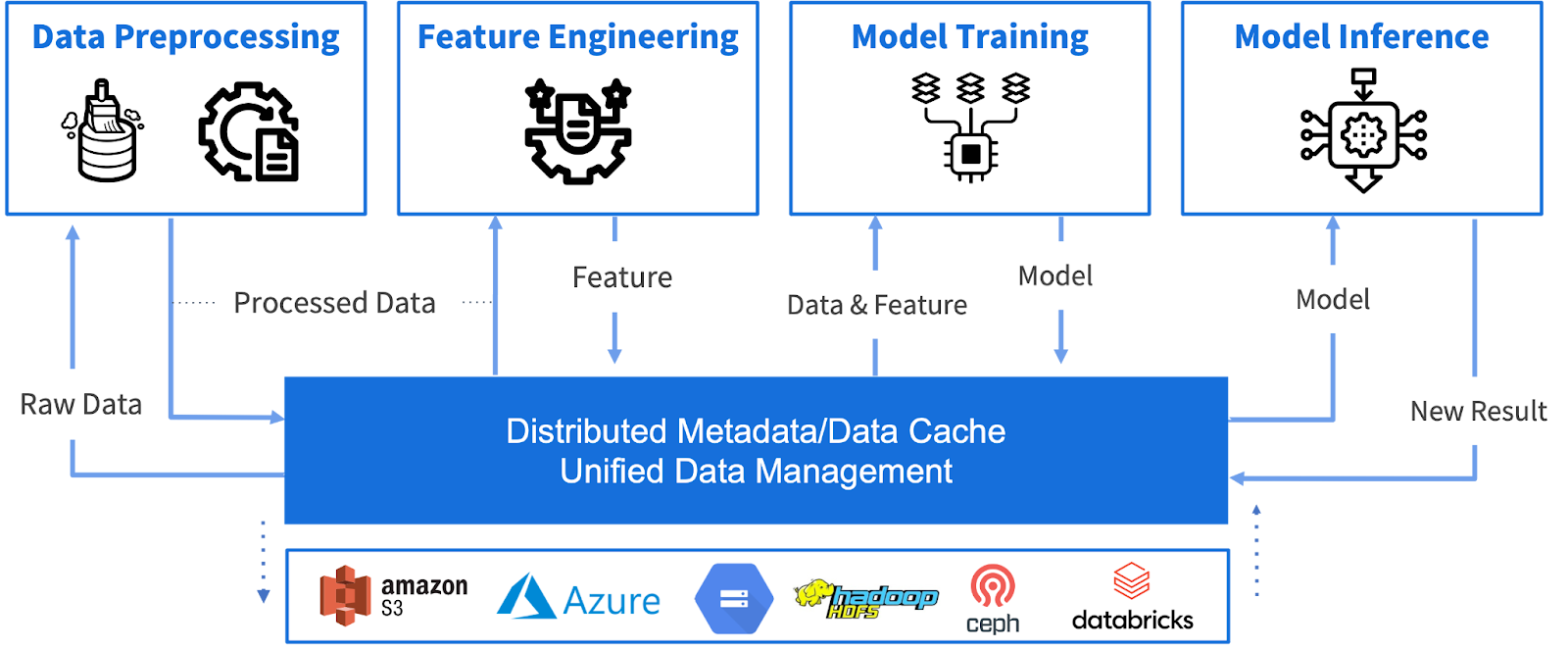
3. Traffic Pattern for Analytical SQL and Cache Strategy Recommendation
3.1 Data Access Patterns
Analyzing the traffic pattern of the analytics workload, we have noticed some interesting trends. Based on our early research at Twitter, we have observed that the majority of activity involves reading data, with no data being written. The amount of data being read is also significant. Additionally, we have observed that a significant portion of the data is read from remote locations, such as other data centers or cloud storage. There is also a tendency for temporary files to be written during the job or query, but most are eventually deleted. Below is a distribution of SQL statements from a typical Twitter’s OLAP workload in a three-month session.

(Source: Serving Hybrid-Cloud SQL Interactive Queries at Twitter)
Based on this traffic pattern, let’s look at each query’s details. For many queries, the amount of data read is small, as selective queries only read a fraction of the data source. This results in the read size being around 1KB. However, there is a long tail of reading latency, and the read performance can vary due to the use of structured and columnar data.

Considering this traffic pattern, we highly recommend the following.
- Hierarchical caching: This can include a memory file buffer, a compressed write profile, and a page cache with 1M pages. By utilizing these caches, you can achieve better performance, although there may be limitations in terms of cache capacity. To address this, a separate cluster for remote cache deployment is suggested.
- Seekable streaming read: As most of the data is structured, there is a need to optimize for SQL input streams and consider pre-loading data. However, it is also important to minimize read amplifications to reduce costs.
Our evaluation of Presto with Alluxio showed up to 2x performance improvements after deploying Presto with 10 worker nodes.

3.2 Hybrid/Multi-Cloud for Data Infrastructure
Another notable pattern is that regardless of the platform (e.g., Presto, Trino), data is read from remote storage because of the separation of compute and storage. This introduces potential issues related to I/O bandwidth and network latency.
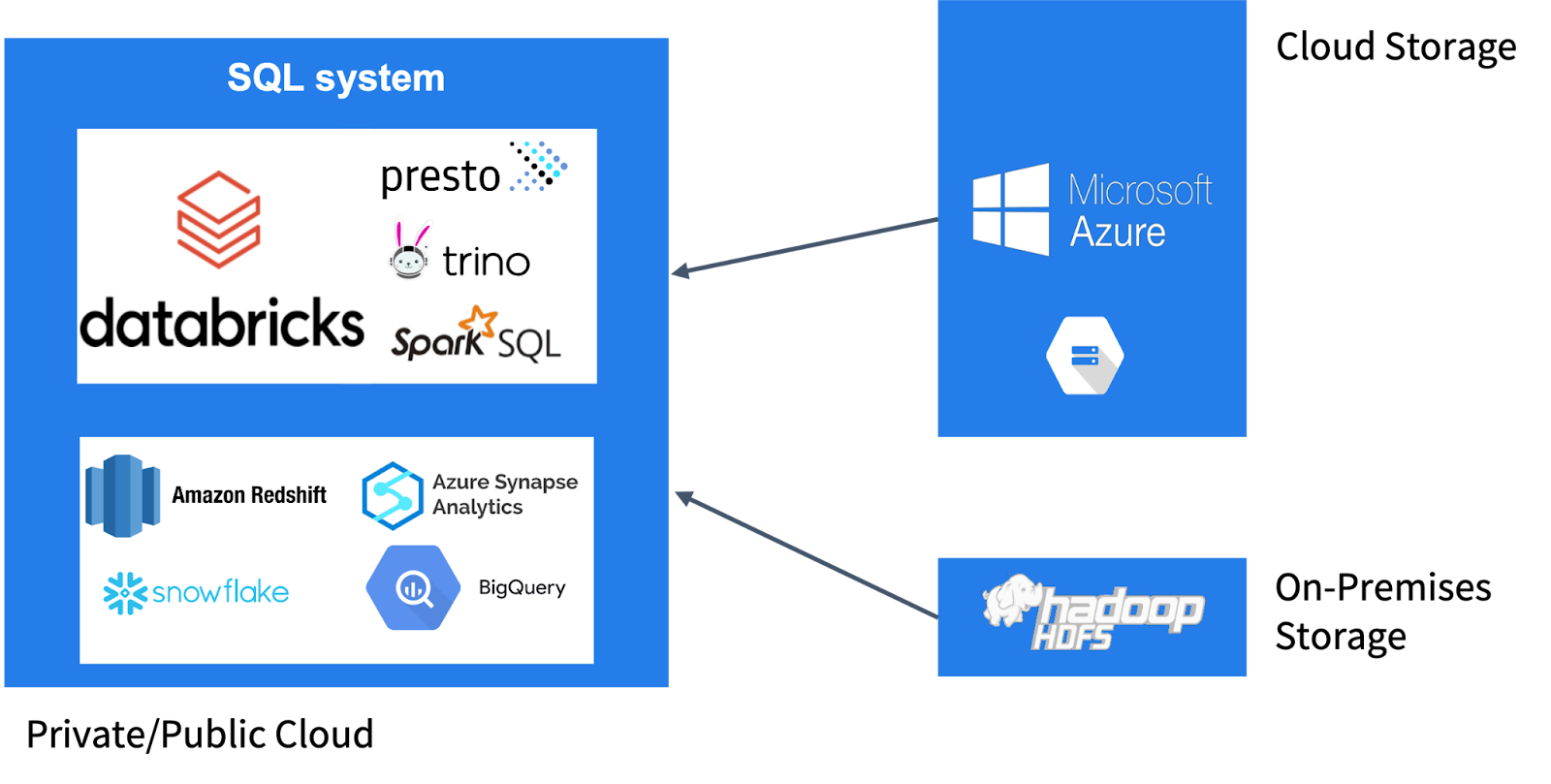
For this scenario, we recommend the caching design:
- Cloud-friendliness: Cache needs to support hybrid and multi-cloud environments, with configurable cache admission and eviction rules.
- High availability: There should be no single point of failure, and caching should support fallbacks to under storage.
- Cost-effectiveness: The I/O and data load from remote storage can be substantial. Therefore, reduce API calls, lower data transfer costs (egress costs), minimize read amplification and do not persist temporary files.
It is easy to integrate data cache (Alluxio) with query engines, such as Presto. There is no need to set up a separate cache cluster; leverage your local disk as a cache. Plus, we have made performance enhancements this year, resulting in significant performance gains for structured data queries.

4. Advanced Caching Strategy
4.1 Cache Capacity Planning Based on Real-time Metrics of the Working Set
Cache space can be expensive, so it is important to plan cache capacity by carefully evaluating your needs. In a multi-tenant SQL system, sizing the cache for each tenant is a complex task. To estimate future cache demand, we need to tell the administrator how many non-duplicate bytes the cache has received in the past 24 hours. We also need to tell them how many requests hit the cache and if the cache can keep all the requests over the last 24 hours. This information will help the administrator determine the optimal cache size for each tenant.
We propose Shadow Cache, a sophisticated solution for efficient cache planning. Bloom filter and cuckoo filter are key design blocks to track working sets for cache capacity planning. We can accurately track and optimize cache usage by leveraging bloom filter and cuckoo filter. This ensures you make informed decisions about your cache size and its impact on query performance.
4.2 Adaptive Cache Admission and Eviction for Uncertain Traffic Patterns
Adaptive cache filters are a type of data structure that can be used to track a large number of items using minimal memory efficiently. They are based on other data structures, such as the bloom filter and cuckoo filter. Adaptive cache filters can estimate the popularity of each data block to improve cache eviction algorithms. However, the memory consumption of adaptive cache filters can be high for extremely large working sets.

AI-based cache filters can distinguish between tables with low values and tables with high values. They can also provide granularity at the partition or even file level. AI-based cache filters use machine learning algorithms to learn which tables are most valuable to cache. This information is then used to cache the most valuable tables, which can improve performance and reduce the number of cache misses.
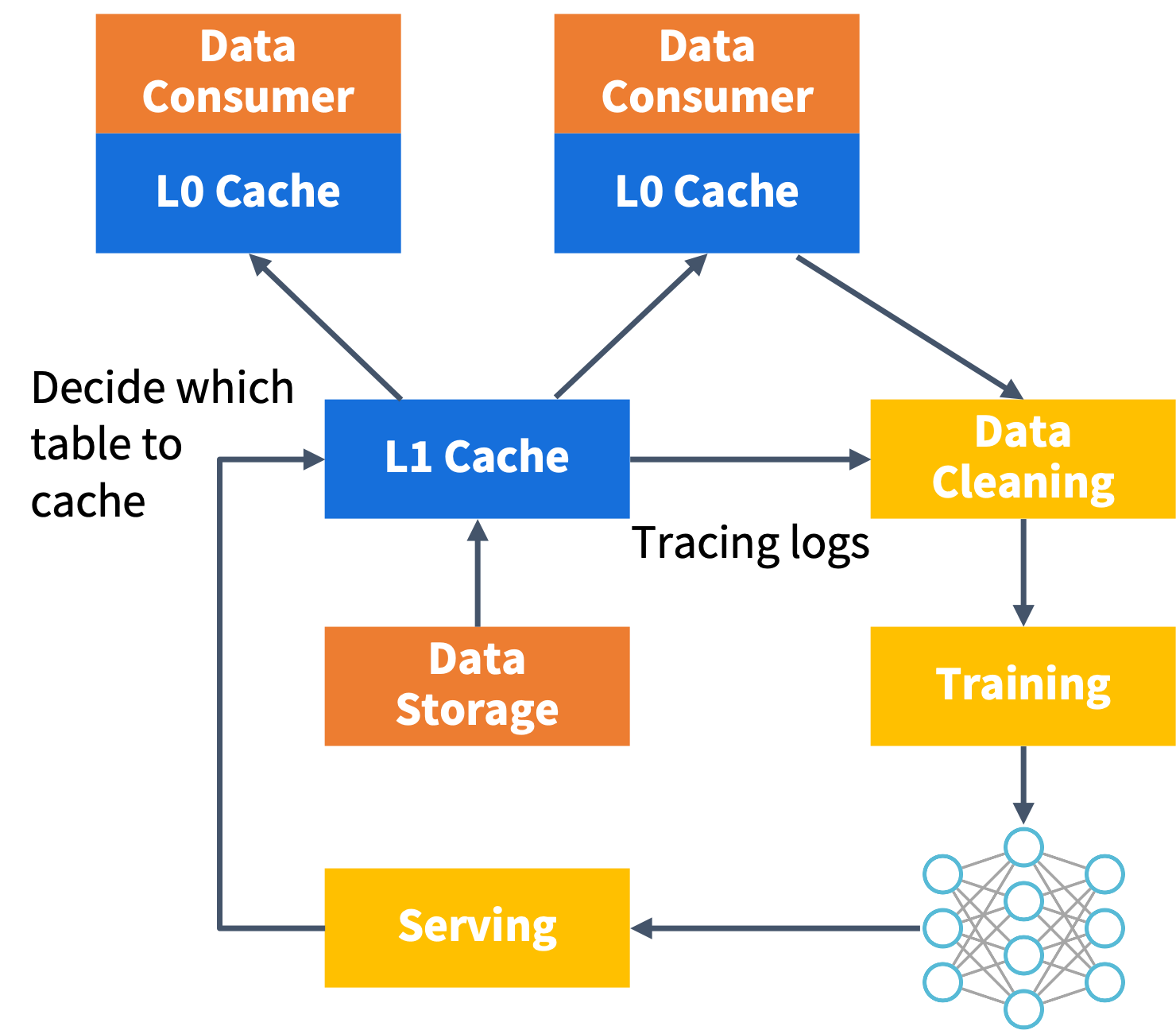
5. Summary
In this blog, we have shared our observations on data access patterns in the analytical SQL and AI training domains based on our practical experience with large-scale systems. We have also discussed the evaluation results of various caching strategies for analytical and AI and provided caching recommendations for different use cases.
In conclusion, data caching plays a crucial role in both data analytics and AI workloads. The strategies for caching need to be tailored to the specific workload and traffic patterns.
To recap:
- Positioned read plays a crucial role in cache performance optimization for loading large AI-purposed structured files.
- Cache in worker nodes can notably accelerate the computation for data analytics (SQL).
- Bloom filter and cuckoo filter are key design blocks to track working sets for cache capacity planning.
- More advanced cache strategies, such as the adaptive cache strategy, are a potential research direction.
Watch the presentation session recording below:
To learn more about Alluxio, join 11k+ members in the Alluxio community slack channel to ask any questions and provide feedback.
References
[1] C. Tang, B. Wang et al., “Serving hybrid-cloud SQL interactive queries at Twitter” in European Conference on Software Architecture. Springer, 2022.
[2] C. Tang, B. Wang et al., “Hybrid-cloud SQL federation system at Twitter” in ECSA (Companion). Springer, 2021.
[3] “Improving Presto Architectural Decisions with Alluxio Shadow Cache at Meta (Facebook)”, https://www.alluxio.io/blog/improving-presto-architectural-decisions-with-alluxio-shadow-cache-at-meta-facebook/, 2022.
[4] R. Gu, S. Li, et al., “Adaptive Online Cache Capacity Optimization via Lightweight Working Set Size Estimation at Scale” in USENIX ATC, 2023.