Shopee is the leading e-commerce platform in Southeast Asia. In this blog, Tianbao Ding and Haoning Sun from Shopee’s data infrastructure team share their project on query acceleration and “Data Access as a Service.” They describe how Shopee leverages Alluxio to improve Trino query performance by ~55% and how Alluxio enhances developer experience by providing flexible data access through Alluxio-Fuse and Alluxio-S3 APIs.
1. About Shopee and Data Platform
1.1 About Shopee
Shopee is the leading e-commerce platform in Southeast Asia and Taiwan. It is a platform tailored for the region, providing customers with an easy, secure and fast online shopping experience through strong payment and logistical support.
1.2 Data Infrastructure Team
The Data Infrastructure team at Shopee is responsible for designing, building and maintaining the underlying systems that support data-centric operations across the company. We work to improve the speed, cost-effectiveness and accuracy of data flow by utilizing open-source technologies such as Kafka, Hadoop, Trino, HBase, Spark, Hive, Alluxio and Druid. Our goal is to provide a robust data platform that supports a variety of big data applications for all teams within the company.
1.3 Data Platform Architecture
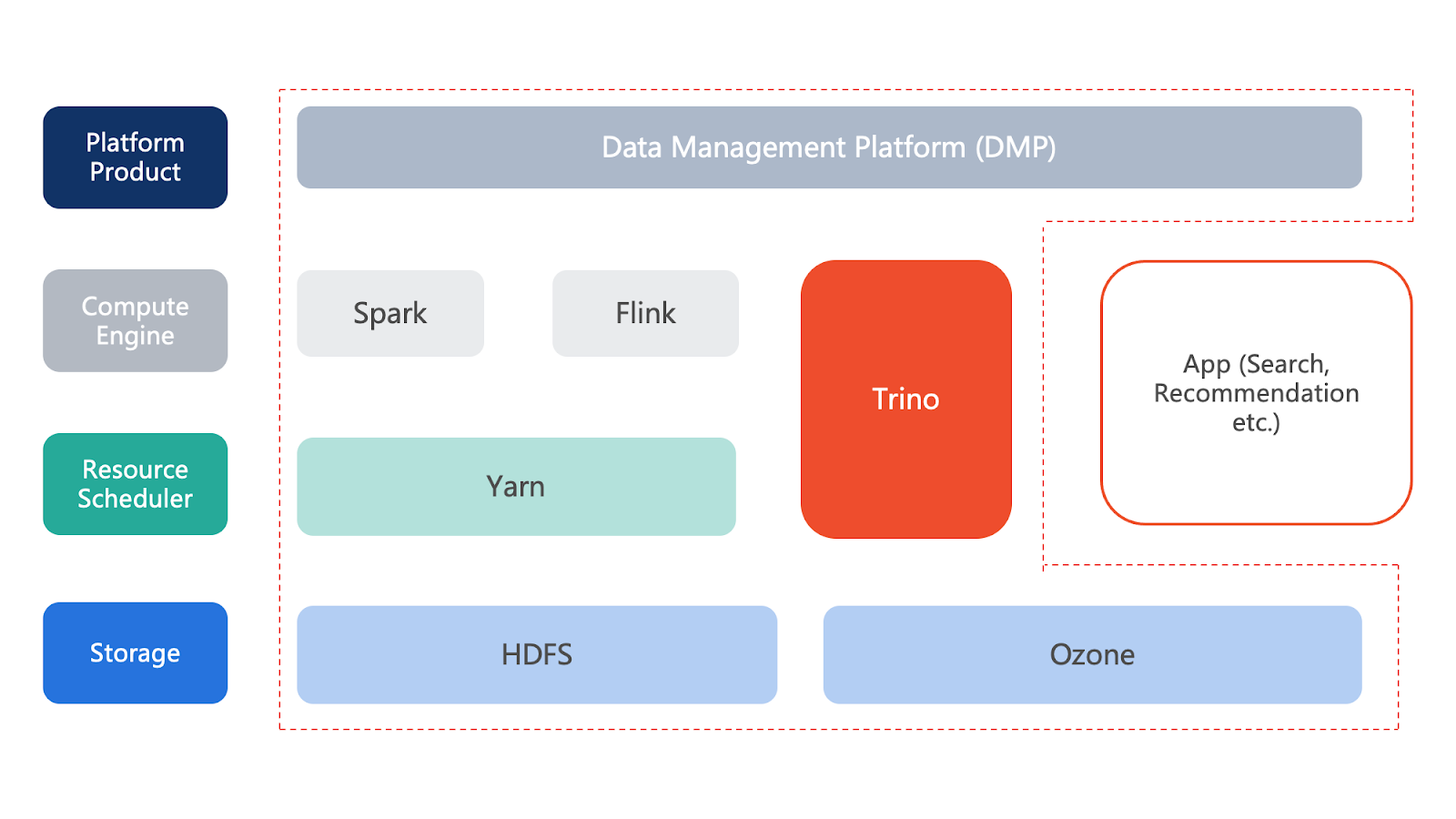
Our data platform is designed to have four layers, storage, resource scheduling, compute engine, and platform product. In our current architecture, we are using HDFS and Ozone as our storage, and Yarn as the resource scheduler. On top of that, Spark and Flink are our compute engines; and it is managed by our data management platform (DMP). The data platform supports applications such as search, recommendation, etc.
The scale of our HDFS cluster and Trino cluster are as follows:
HDFS:
| Number of Nodes | Thousands |
| Storage Capacity | Hundreds of PBs |
| Number of Files | Billions |
| Max QPS | Hundreds of thousands of queries per second |
Trino:
| Number of Nodes | Thousands of instances |
| TP90 | ~2 minutes |
| Input | Dozens of PB per day |
| Number of Queries | Hundreds of thousands per day |
2. Data Access Acceleration for Trino
2.1 Performance Challenges
There was a huge challenge to run Trino on top of a large-scale HDFS cluster with consistent performance.

Performance of HDFS was unstable
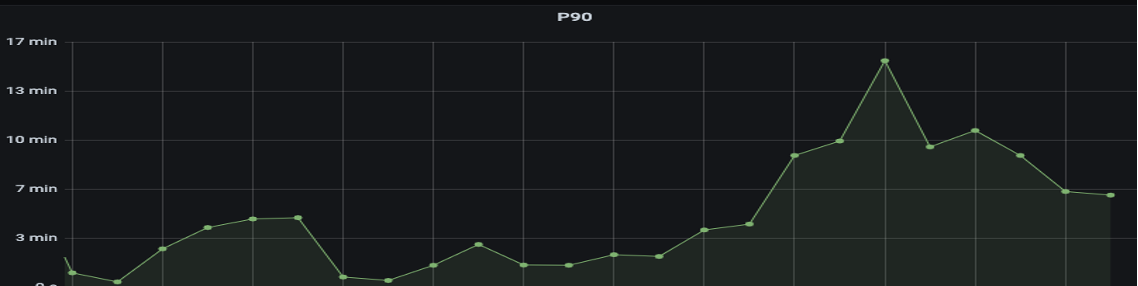
Latency of Trino queries was unstable
We have to come up with a better way to serve the user with a consistent user experience, including performance and usability. After investigation, we found Alluxio caching solution is a preferred way to overcome the above challenges.
2.2 Solution with Alluxio
2.3.1 Co-located Architecture of Trino+Alluxio
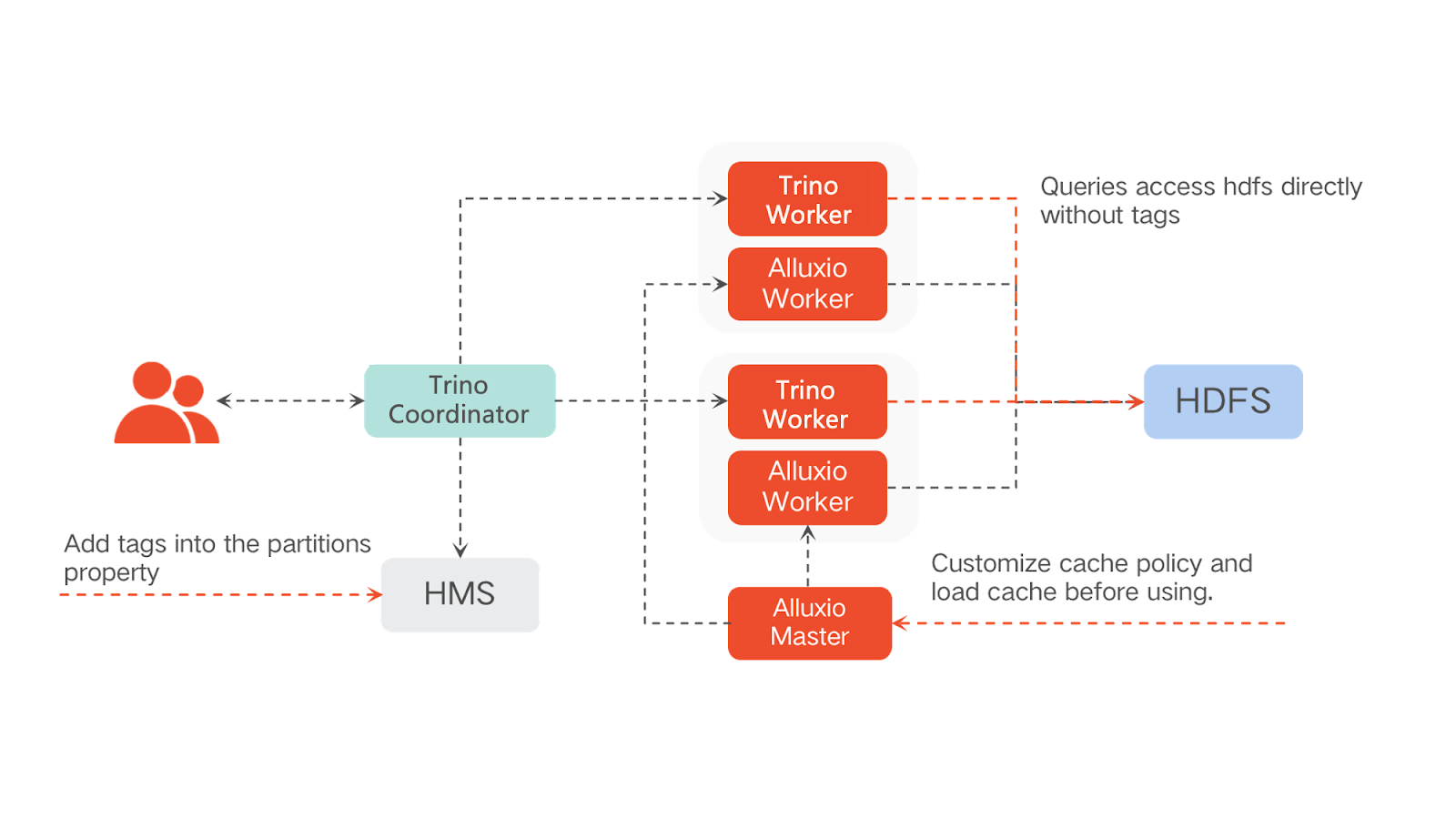
The typical architecture is co-locating Trino worker and Alluxio worker on the same machine and mounting HDFS in Alluxio. Data in HDFS is cached into Alluxio after first-time access. Then Trino will access data from Alluxio instead of the HDFS cluster.

However, this typical architecture has its limitations, such as having fixed caching policies, and slow read while retrieving data for the first time.
2.3.2 Optimization with CacheManager
In addition to the typical architecture, we made three optimizations: we added tags into the partitions property stored in HMS (Hive Metastore), which tells Trino where the data is cached; we customized the cache policy to filter the cache; and we let the queries from Trino access HDFS directly according to tags. We also implemented a CacheManager to manage these changes better.
The CacheManager can load, unload, and mount Alluxio, generate hot tables and update the cache policy based on Hot Tables, subscribe to Kafka to apply changes to existing caches, and modify the HMS. The CacheManager also provides upper-layer interfaces for I/O with Operator. With the CacheManager, the HMS can be properly set and modified and the computing application can get tags from HMS.
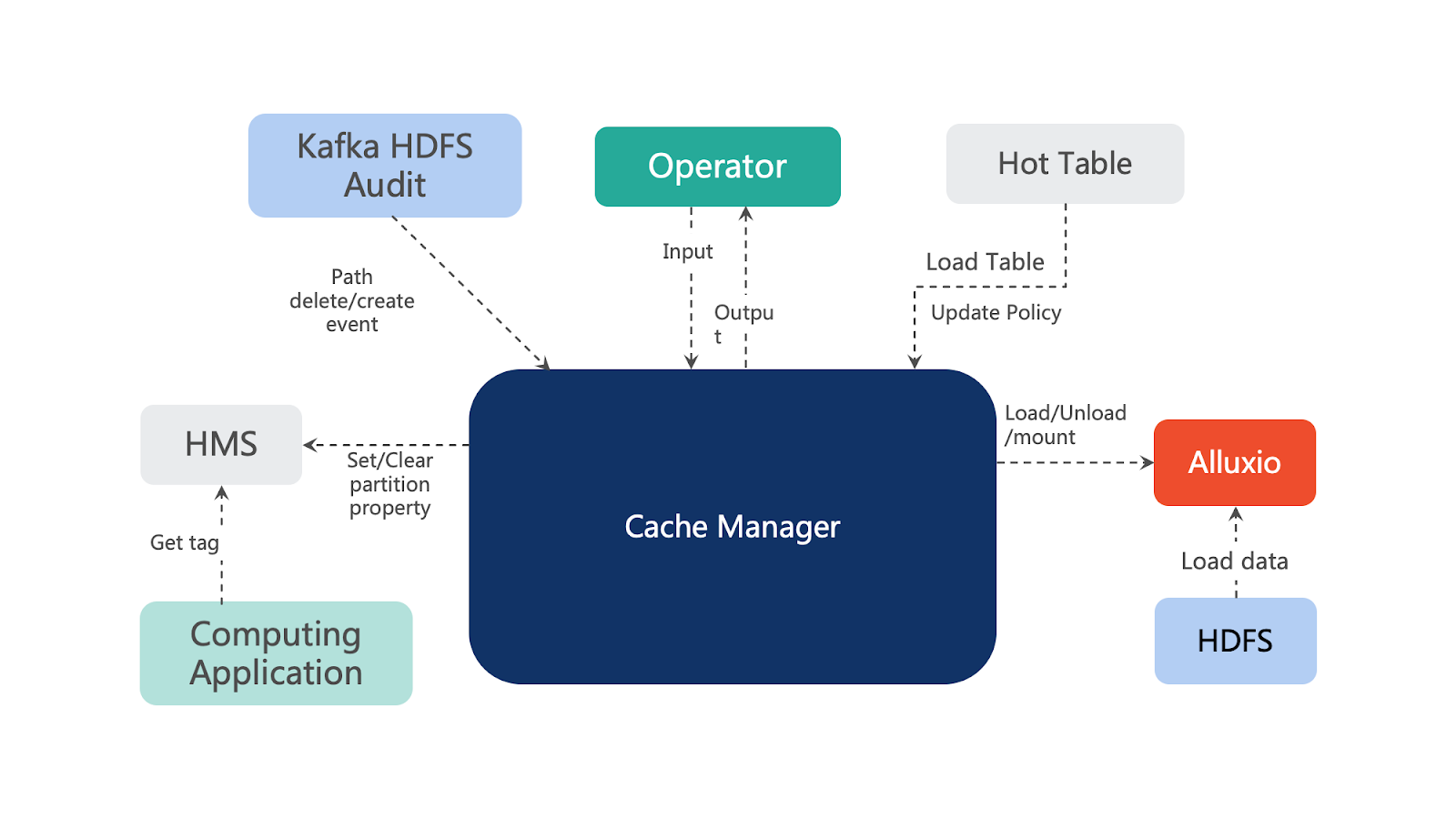
The Hot Table is a Hive table that partitions data by date and calculates the number of daily visits using samples from the Presto Query Log. HMS tagging in Trino involves checking if the target key has a tag in HMS. If the tag exists, indicating that the key-value pair is cached in Alluxio, the value is retrieved from Alluxio. If the tag does not exist, the key is retrieved from HDFS and a tag is set.
Additionally, we provide caching management with REST APIs integration on top of the cache manager operations, including mount, unmount, load, and query.
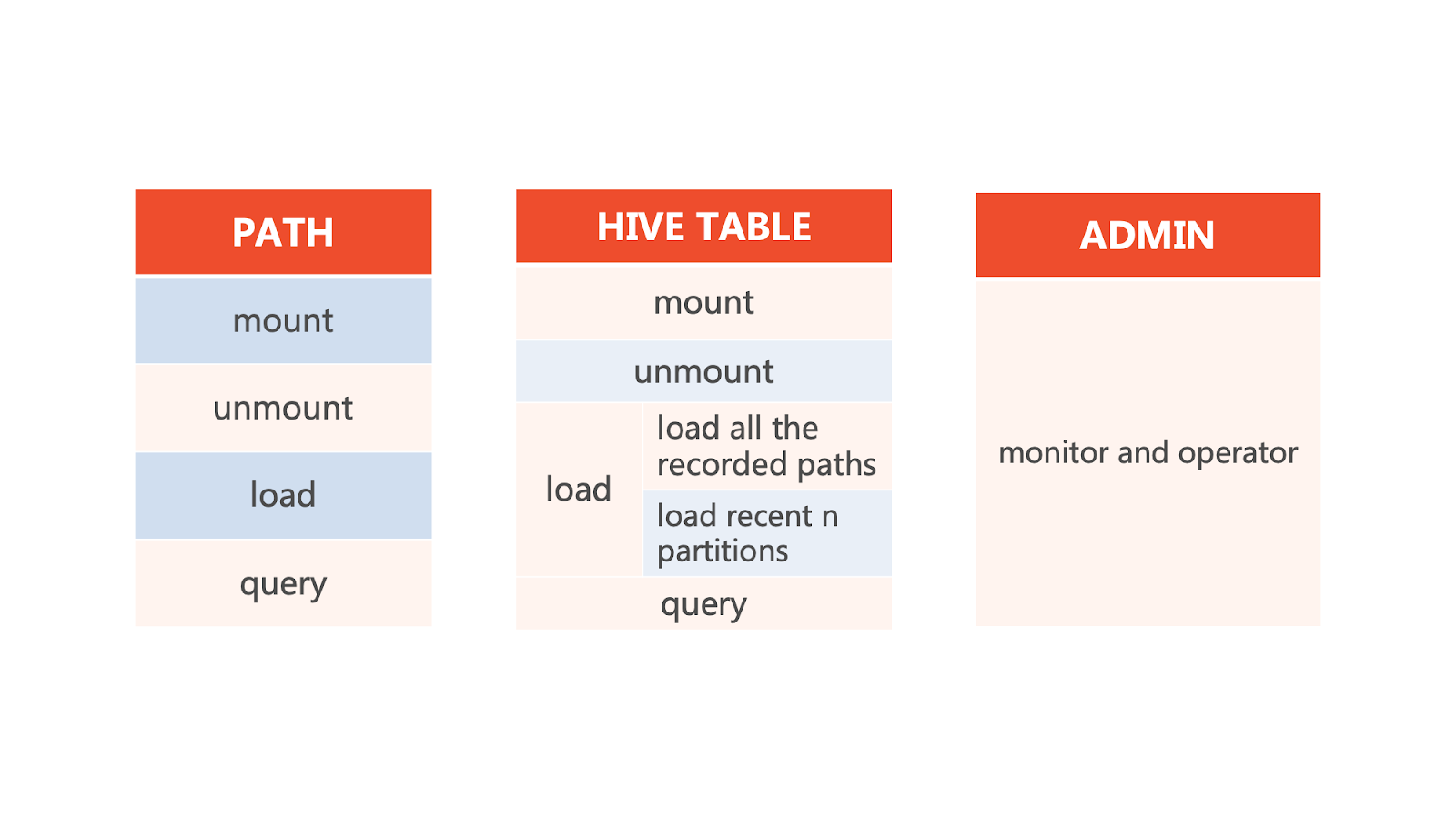
2.3.3 Results
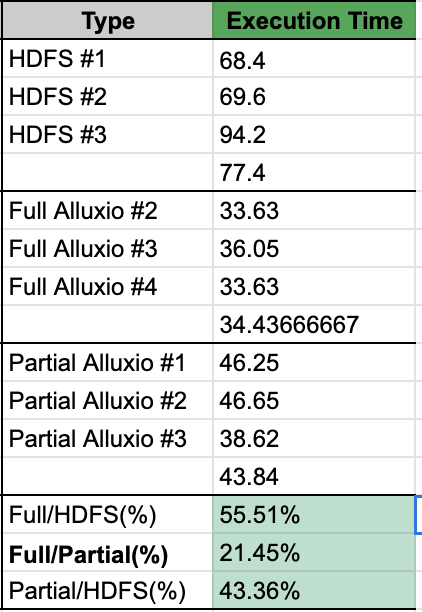
Through performance tests, we found that Trino querying from Alluxio can shorten execution time by 55% compared to querying data directly from HDFS.
3. Data Access as a Service – Storage “Servitization”
3.1 Challenges and Needs
Most of our data is stored in HDFS and our applications depend on various development interfaces, like S3 and POSIX. However, HDFS has limited support for these interfaces. This means that developers working in the above interface other than Java may have difficulty interacting with data stored in HDFS. They need to use S3 or Fuse API to access the data stored in HDFS.

The flexibility of the Alluxio interface is one of the reasons for choosing Alluxio as a data virtualization layer in our architecture. We call this storage “servitization,” which means “Data Access as a Service.” Having this service will improve the data access experience for our developers. By utilizing these multiple APIs through Alluxio, we are able to enable a wider range of use cases within our data platforms, allowing non-Java applications to access data in HDFS.
3.2 Using Alluxio Fuse API for Accessing HDFS
The first solution for accessing data stored in HDFS is using Fuse, which allows data to be accessed as if it were a local filesystem. There are two ways to deploy this solution: by deploying Alluxio Fuse on physical machines or by deploying Alluxio Fuse on a Kubernetes cluster.
Fuse, or “FileSystem in Userspace,” consists of a kernel and a user-level daemon. Developers can implement the standard POSIX API to create a custom filesystem. Alluxio Fuse, which requires libfuse to be installed, has two implementations: JNR-Fuse and JNI-Fuse. The default implementation is JNI-Fuse and it is deployed in standalone mode.

Alluxio Fuse mainly focuses on read services, with limited support for random writes. For deployment on a Kubernetes cluster, Alluxio Fuse uses the Container Storage Interface (CSI) standard to expose storage systems to containerized workloads.
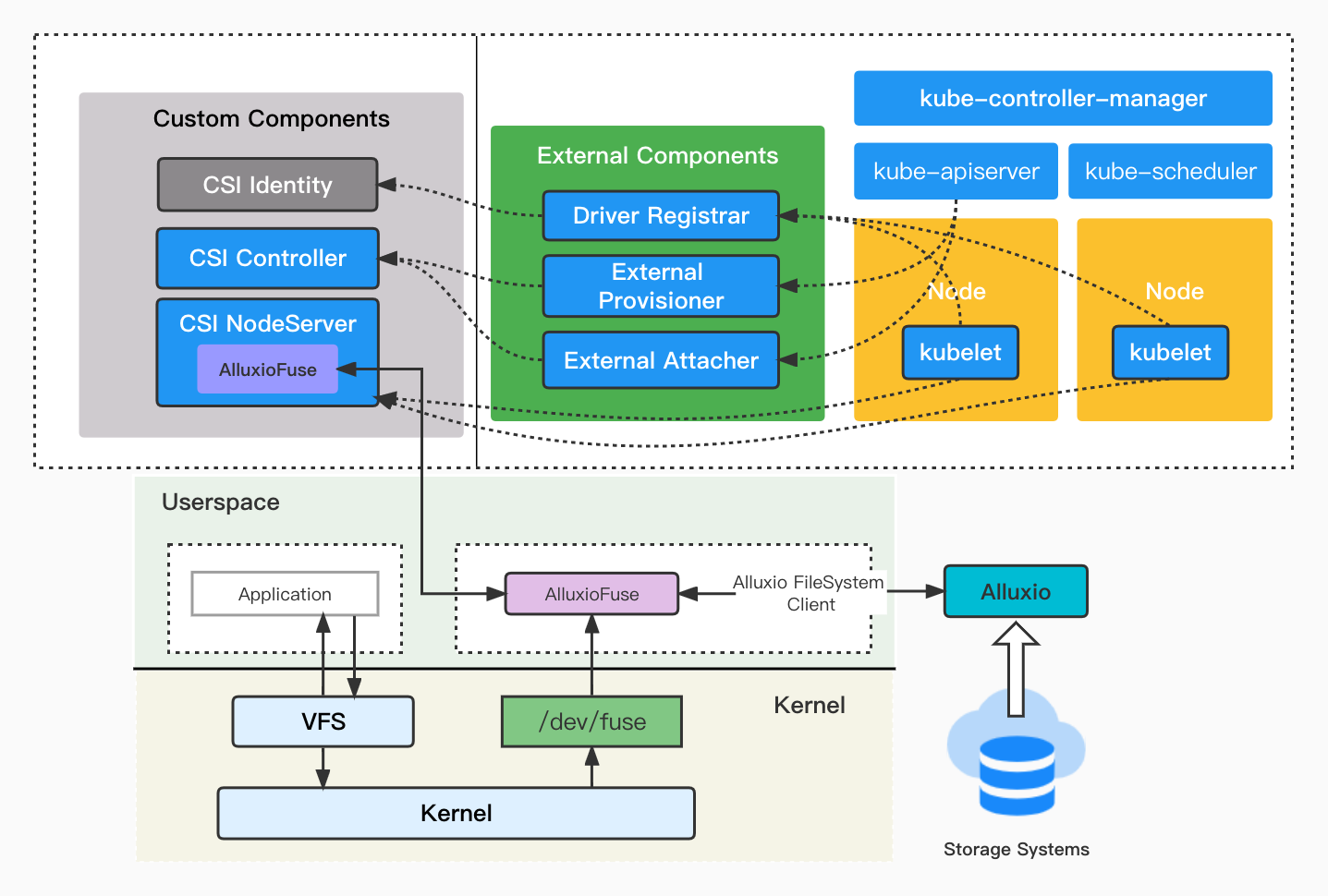
To avoid the data service unavailability caused by the failure of a NodeServer, an Alluxio Fuse sidecar is introduced. This allows the application pods and Alluxio Fuse sidecar to share storage volumes and networks, giving the runtime environment flexibility as each container can have its own configurations.
3.3 Using Alluxio S3 API for Accessing HDFS
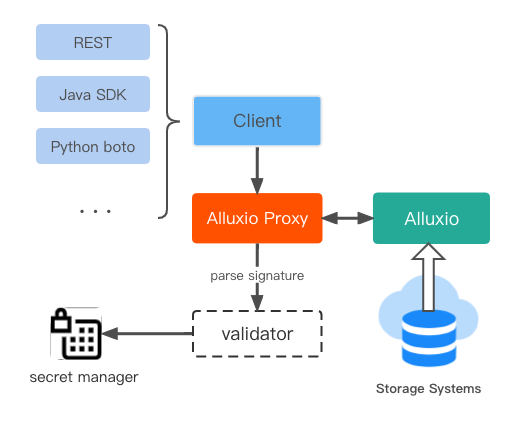
The second solution is using the S3 API to access the Alluxio proxy service. Since S3 API is compatible with Alluxio, it is convenient to access HDFS through the S3 API.
Since Alluxio can mount data in HDFS and provide a proxy service compatible with the S3 API, clients can send requests in S3 format to the Alluxio proxy service, which Alluxio can correctly handle.
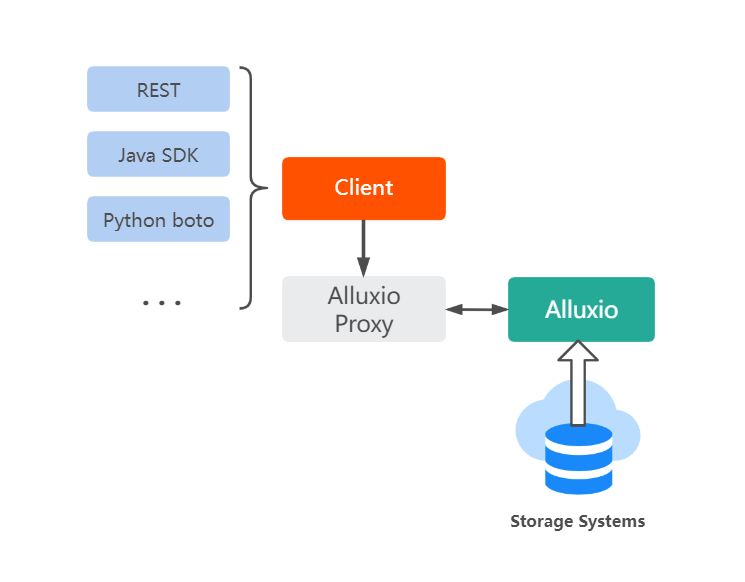
For example, when we execute a single Alluxio fs mount command, mounting hdfs://host:9000/projects in HDFS to /projects in the Alluxio namespace, the 1-level directory, projects, is the bucket, and the other descendants are keys. It is easy to use the corresponding S3 SDK to access the bucket and keys underneath.

To ensure only valid requests are handled by the Alluxio proxy, proxy authentication is used to filter requests. When the S3 SDK sends requests, it will first convert the request path to REST format and append the user’s ID and secret key. A signature will be generated from these fields and be included in the request body. When the server side receives the request, it will generate the signature using the same fields, checking if the server-side signature and the client-side signature are equal.
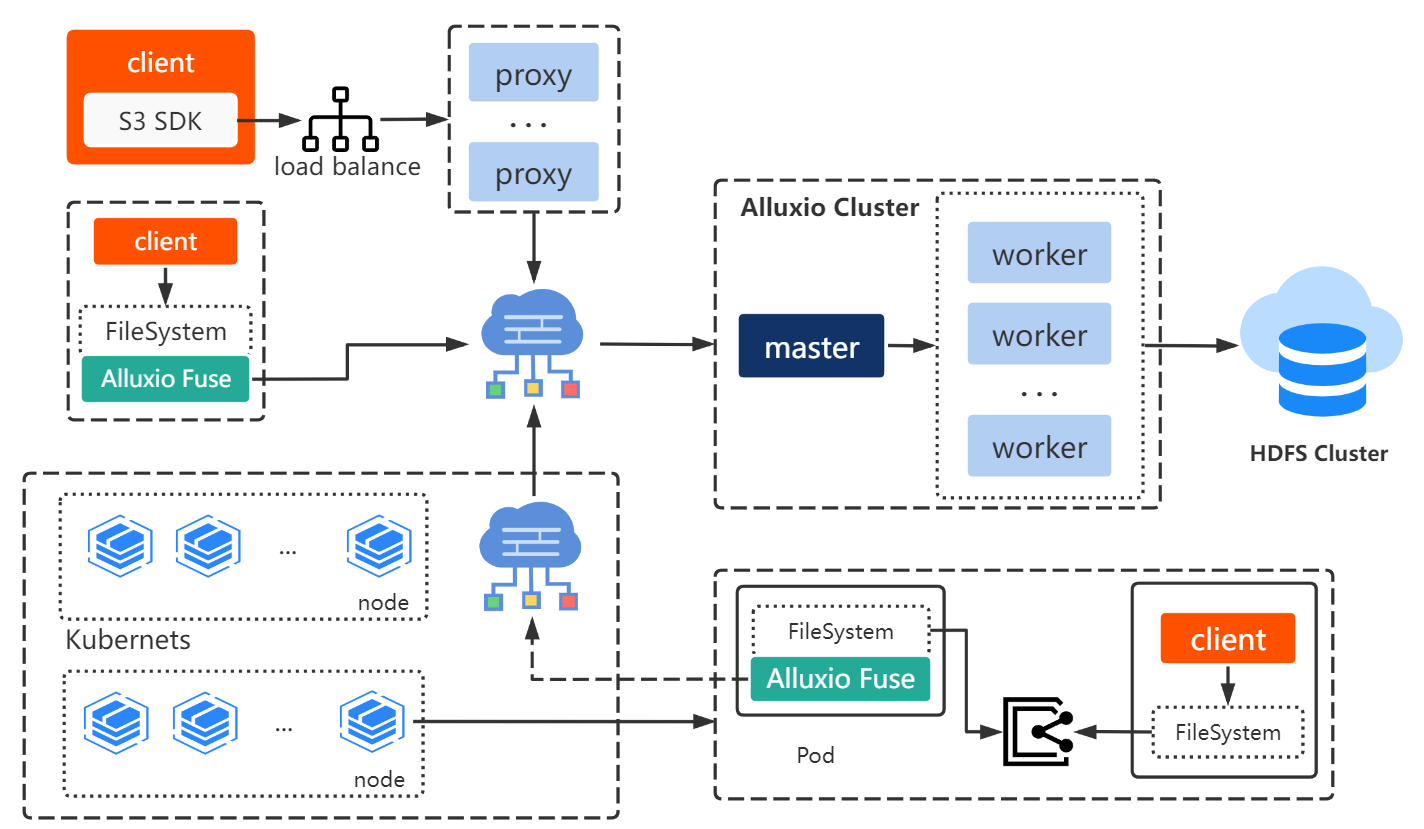
3.4 The Overall “Data Access as a Service” Architecture
By combining the previously mentioned APIs for accessing Alluxio, we have the overall architecture illustrated here. We use HDFS as the underlying file system (UFS) for Alluxio, and we have two main types of top-level interfaces: S3 API and Fuse API, to access Alluxio. These interfaces allow convenient and efficient access to the data stored in HDFS through Alluxio.
4. Future Work
To accelerate data access, we will integrate Alluxio with Spark and Hive and implement an adaptive cache policy using the CacheManager to optimize caching.
To enhance “Data Access as a Service,” we plan to support more POSIX APIs to handle cases that involve both reads and writes. Additionally, we will optimize the CSI by separating the Fuse from the NodeServer to improve the overall performance.
5. Summary
To summarize, we have enhanced query performance and developer experience by using Alluxio. By making Alluxio a data access service for multiple APIs, we are able to support various important use cases in production.
About the Authors
Tianbao Ding, Data Engineer of the Data Infra team at Shopee. Tianbao has worked on storage, engine, scheduling, and data engineering. He is also experienced in backend development.
Haoning Sun, Data Engineer of the Data Infra team at Shopee. Haoning’s works on distributed storage systems and mainly focuses on Alluxio at Shopee. He is interested in the distributed system. He is also experienced in data warehouse platform and HBase development.