Consistent hashing is a special technique that allows hash rings to be expanded or shrunk dynamically with minimal disruption. Alluxio’s DORA (Decentralized Object Repository Architecture) uses consistent hashing for load balancing when scaling nodes. To reach the goal of fast performance, strict consistency, and load balancing, we analyze, evaluate, and select the most suitable consistent hash algorithm for Alluxio. In this blog, we introduce different consistent hash algorithms and analyze their difference and whether they suit Alluxio with experiment results.
Overview
When an Alluxio cluster is scaled, using consistent hashing permits only a small number of resources to be remapped. If we see workers to be buckets and files to be keys, consistent hashing means when we add or remove a bucket, keys either stay in the original bucket or are transferred to a new bucket.
Besides consistency, uniformity also should be considered in our hash algorithm. If files aren’t distributed among the workers uniformly, we call this system a considerable degree of data skew, causing the storage space of some workers to be much larger than that of other workers.
In Alluxio’s DORA, there are some unique features compared to other distributed systems:
- All files are stored in workers, and only one file is stored in one worker.
- Different backups of a file should be stored in different workers.
- All operations to Alluxio are only through Alluxio’s client.
Under the characteristics of this structure, some popular hash algorithms may not be suitable for Alluxio. And some algorithms may be less efficient.
Original Hash Algorithms
Introduction
The hash algorithm Alluxio uses, usually known as Consistent Hashing, is from Ring Hashing, which was proposed by D.Karger in 1997. Ring Hashing will use nodes to build a hash ring, and we calculate every node’s hash value. When we need to determine a key’s corresponding bucket, we calculate the key’s hash value and find the first value greater than it on the hash ring. To make it more uniform, Consistent Hashing introduces virtual nodes. Every virtual node belongs to only one real node. Therefore, the complexity of this algorithm if O(log Vn). Vn is the number of virtual nodes. The larger the number of virtual nodes, the better the uniformity of the hash algorithm.
Drawbacks
With the improvement of Alluxio, DORA supports more and more functions. Some serious drawbacks emerged:
- Too much time cost: To make it uniform, it will use too many virtual nodes. For example, in our experiment, when the number of virtual nodes is up to 1000 times of real nodes, it will barely achieve satisfactory uniformity. But it will make the whole query process much slower.
- Not enough uniform: The file distributed on the hash ring is not uniformly enough, which means this system can not achieve better load balancing.
- Not strictly consistent: When the workers change, the hash ring will be rebuilt. It may harm the consistency of this algorithm, which makes too many files to be redistributed. On the other hand, completely rebuilding the hash ring will make the process of adding or removing nodes slow.
Algorithm Assessment
As the drawbacks described above, we need to improve our hash algorithm to make it more strictly consistent, more uniform, and more efficient. We need to design some standards to assess different hash algorithms. We intend to evaluate them in three aspects.
Time Cost Assessment
Given x files and n workers, the worker corresponding to each file can be obtained by the algorithm. It takes t ms for each file to get the corresponding worker, and we expect t to be as small as possible. Instead of evaluating t, we can evaluate the total time cost T of getting x workers given x files.
Uniformity Assessment
Given x files and n workers, the worker corresponding to each file can be obtained by the algorithm. We can get a histogram to describe the distribution of files to different workers. Let the final number of files assigned to each worker be x1, x2,…,xn, we expect the variance σ2 of {x1, x2,…,xn} to be as small as possible.
Consistency Assessment
Given x files and n workers, the worker corresponding to each file can be obtained by the algorithm. When the number of workers changes, the files need to be redistributed. If some file changes the worker it stores, we increment the counter by 1. We check all files in this method. The larger the value of the counter, the worse the consistency will be.
Improvement of Consistent Hashing Algorithms (Ketama Hashing)
Ketama Hashing is a little different from the original consistent hashing algorithm. Specifically:
- We optimize the setting method of virtual nodes. Consistent Hashing just divides the hash ring more uniformly with virtual nodes. For our method, every virtual node uniquely corresponds to a worker. It can build the hash ring more efficiently.
- When the number of workers changes, we just need to update the hash ring instead of rebuilding the hash ring. The file to be distributed is less than the other two hash algorithms.
Our experiment result below shows that it consumes less time when building the hash ring and querying which worker to store a given file. The variance we have calculated shows that Ketama Hashing has better uniformity.
Alternative Hash Algorithms
Maglev hashing (2016) (Best)
Introduction
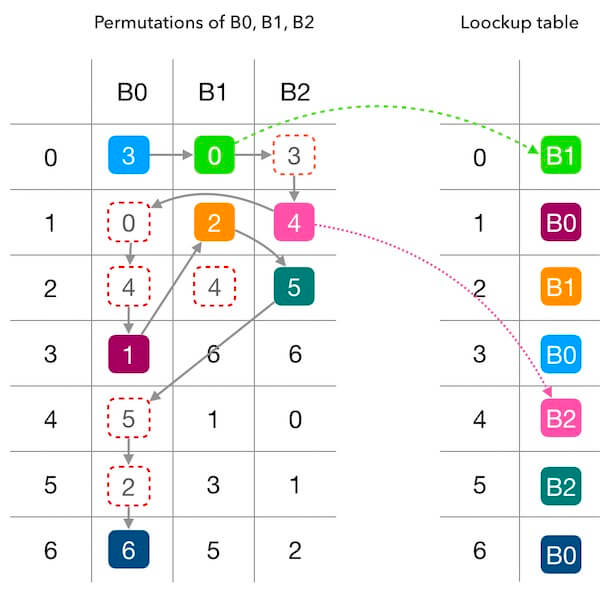
It generates a lookup table for workers, every worker will be mapped on the lookup table. Suppose that there are n nodes, and the size of lookup table is M.
- Firstly, we should determine the value of M. M must be a prime number and much bigger than the number of nodes n.
- Secondly, for every node, we generate a permutation list of length M, which consists of random value in [0, M – 1].
- Thirdly, we fill the lookup table with these permutation lists. We use the element of permutation list as the index of lookup table. If the target position is already occupied, it will use the next element of the permutation list.
- For a given file, we calculate its hash and take the value modulo M as the index lookup table. Then we will know the corresponding worker to store the file.
- Another important question is, how can we generate permutation list? We use two different hash algorithms, h1 and h2. Firstly, we calculate the offset and skip.
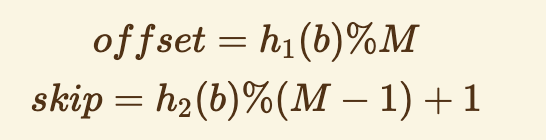
- And then, for every j, we calculate all values of the permutation list in this way.
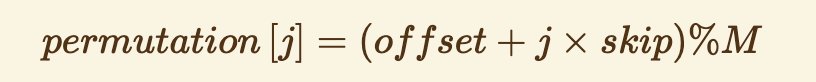
Limitation
- Consume more memory: The size of lookup table should be much bigger than the number of workers, and must be a prime number. We often use 65537 or 655373 as the size of lookup table. If the number of workers is near M, the query process will be too slow.
- Every time the workers change, the lookup table should be rebuilt completely.
Jump Consistent Hashing (2014) (Good)
Introduction
We record ch(key, num_buckets) as the hash algorithm when the number of buckets is num_buckets:
- When num_buckets = 1, all keys will be distributed to one bucket. That is, ch(key, 1) == 0.
- When num_buckets = 2, to make keys distribute uniformly, half the keys will be distributed to the bucket numbered 0, and half the keys will be distributed to the bucket numbered 1.
- Therefore, when the number of bucket is changing from n to n + 1, there should be n/n+1 results of ch(key, n+1) remain unchanged. Only 1/n+1 results changes.
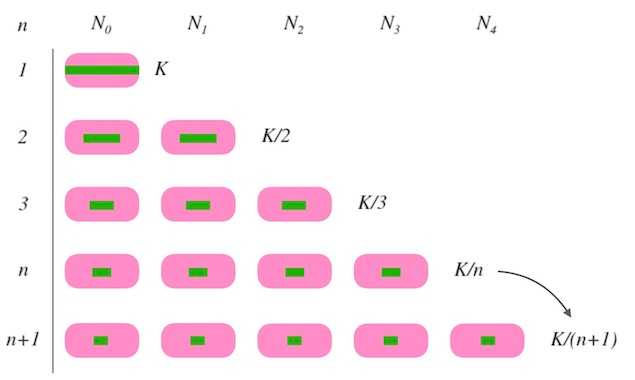
- To determine when the keys in a bucket move to a new bucket, we generate a pseudo-random sequence for every bucket. When the number of buckets increases from n to n + 1, we compare the pseudo-random number of a bucket, recording as k, and 1/(n+1). If k < 1/(n+1), then the bucket’s keys move to the new bucket. Otherwise, these keys will stay in their original bucket.
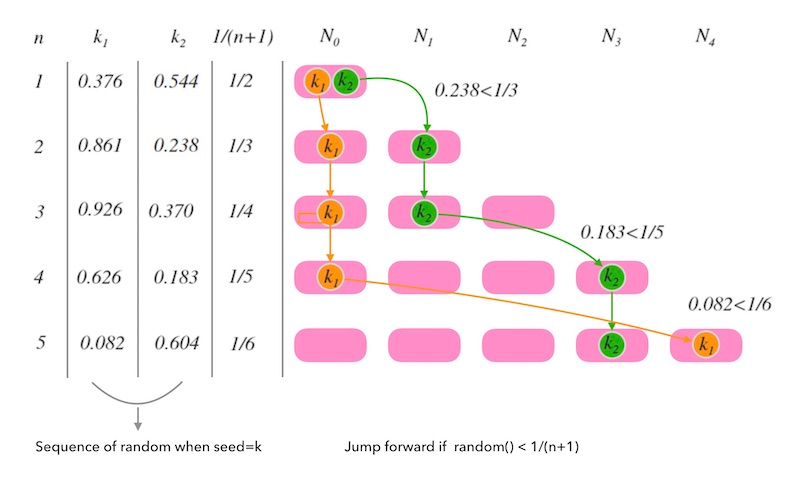
Drawbacks
The backward of this algorithm is we can only delete or add the bucket at the end of the bucket list.
Solution
Every time the worker list changes, we compare the difference between the old list and the new one. We find which worker changes. There are two cases that need to be dealt with.
(1) k workers to be added.
We just add the k workers at the end of the worker list.
(2) k workers to be removed.
Firstly, we remove these k workers from the worker list. Then, we fill the k workers at the end of the list to the vacant positions.
However, the status of the worker list should be stored by Alluxio Master. Alluxio Worker or Alluxio Client cannot complete this process.
Experiments
Experimental Data:
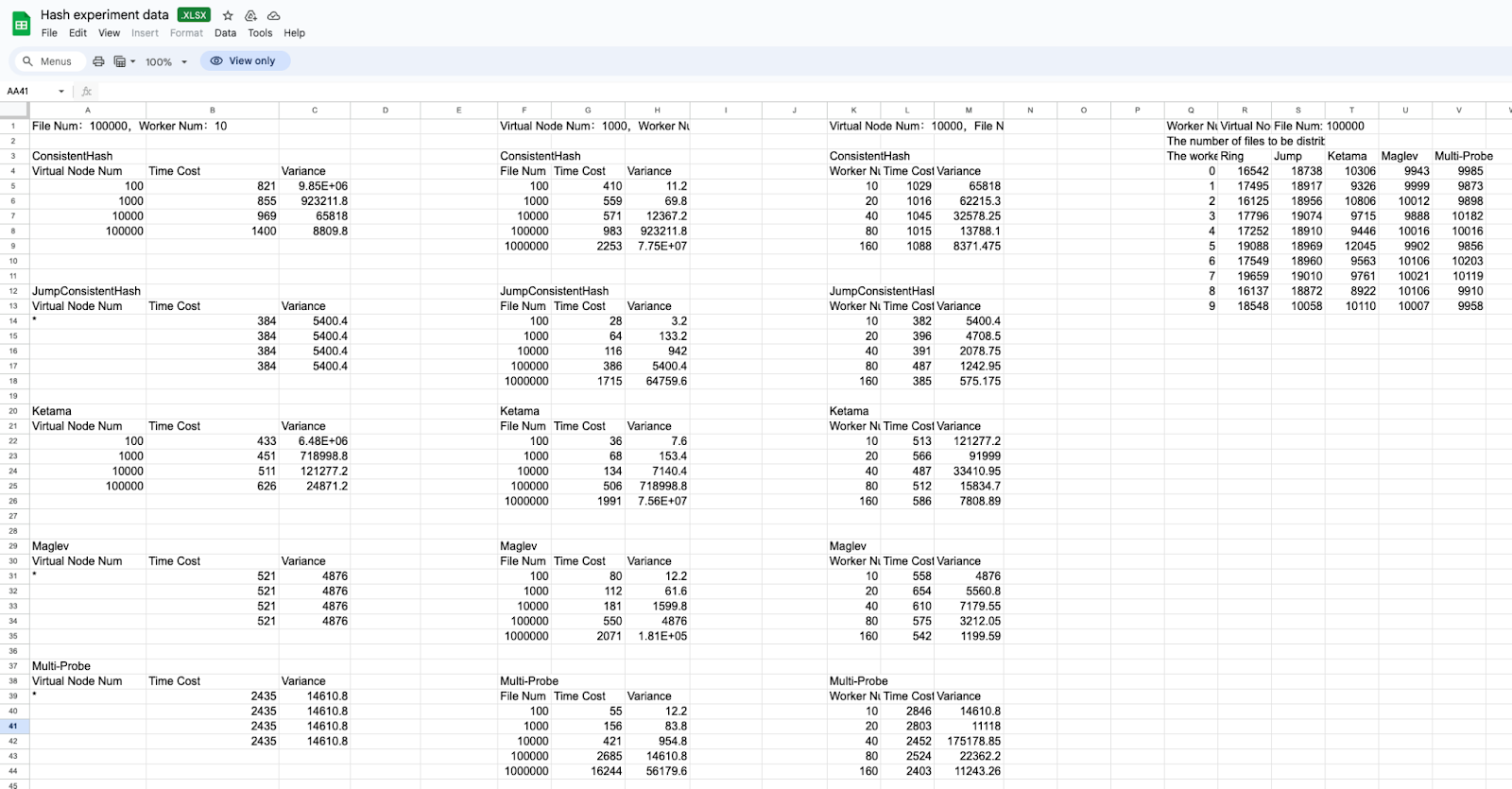
Due to the bad performance of Multi-probe Hashing, we removed Multi-probe’s results in PPT and displayed all data in this Doc and the Excel above.
(1) Different number of virtual nodes:
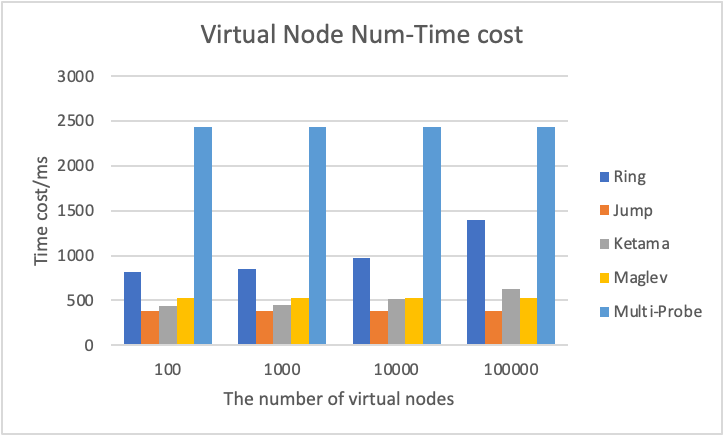
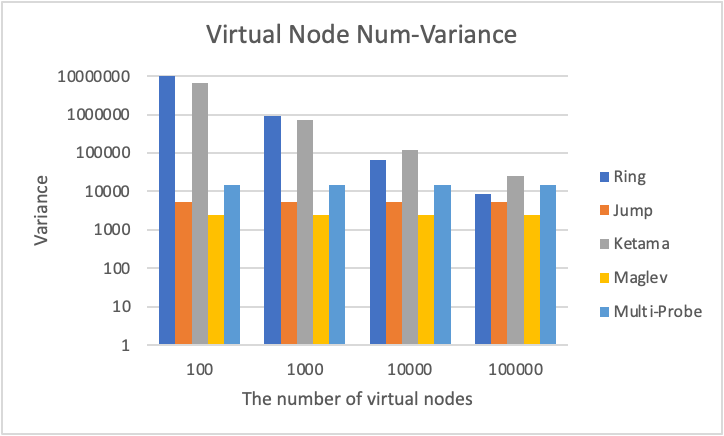
(2) Different number of files:
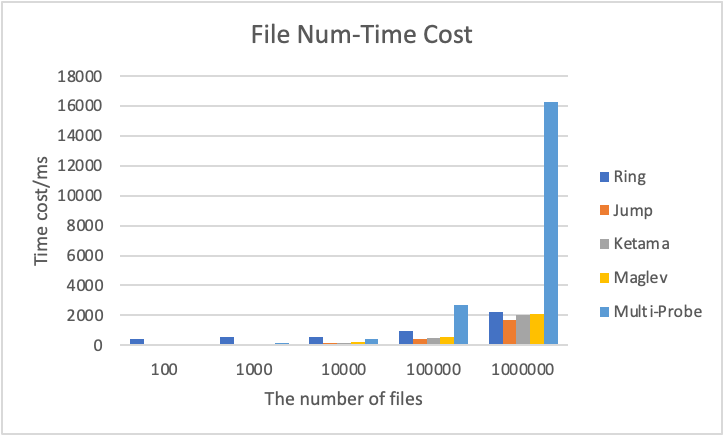
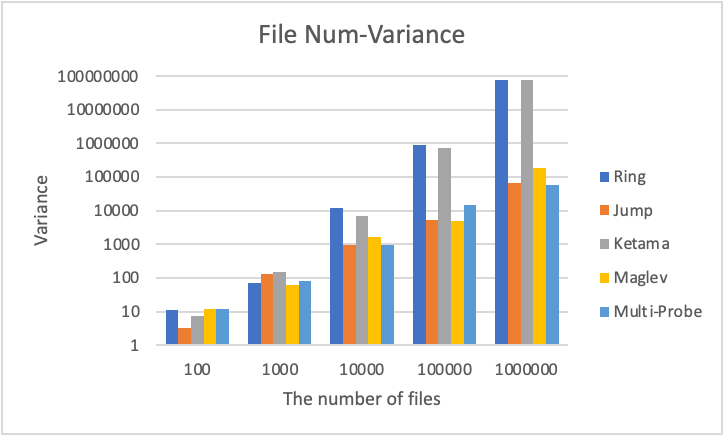
(3) Different number of workers:
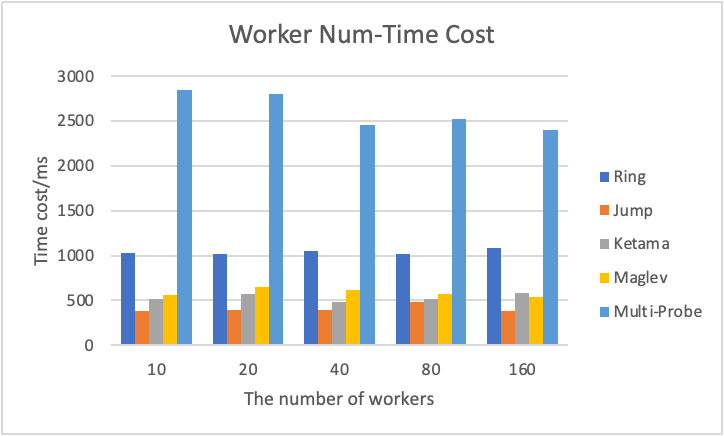
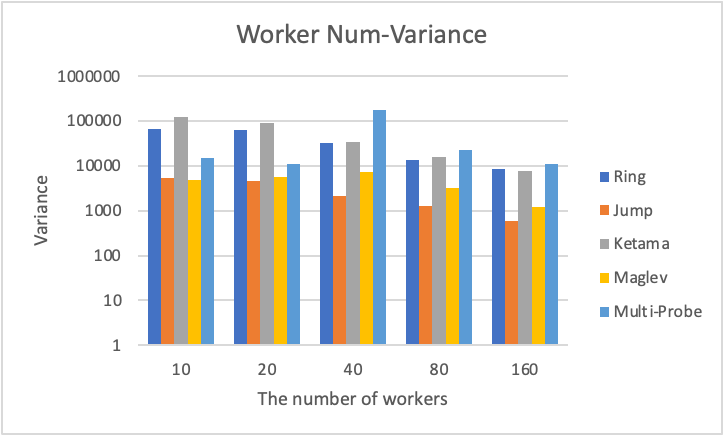
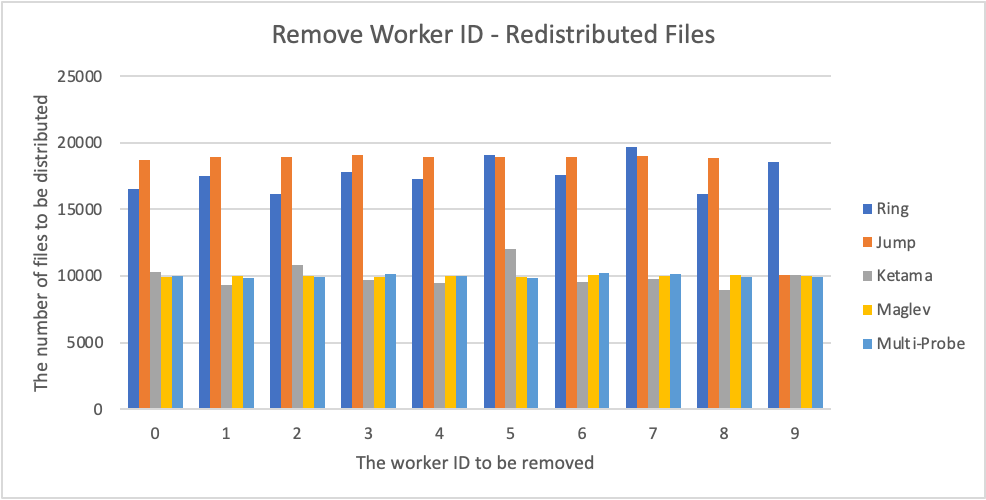
(4) The number of files to be distributed when a worker is removed:
Other Hash Algorithms
Rendezvous Hashing (1998)
Not build a hash ring or do complex calculations. For every given key, it calculates hash value for every worker node with a hash function h(key, worker), and chooses the maximum value of these hash results.
However, the complexity of Rendezvous Hash is O(n), where n is the number of workers. Because it will calculate the hash value for every worker. It is too slow for Alluxio.
Multi-probe Hashing (2015)
For a given key, we calculate the value of max{ hash(key, worker_1), hash(key, worker_2), …, hash(key worker_n) }. The maximum hash value of a worker will be selected to store this file. As experiment results show above, this algorithm is too slow.
Anchor Hashing (2019)
It keeps track of too many status, such as the last position of each node, the replacement of each node, the maximum number of nodes in the cluster (the size of the anchor), and the removed nodes in reverse order.
Dx Hashing (2021)
Maintain two sets: the working set and the failed set. It calculates the hash of the file’s key to be the pseudo-random sequence’s seed, and the pseudo-random function’s result determines which worker to choose to store this file.
The working set can be obtained easily, but how can we get the failed workers? This method needs to save information of failed workers. It is not a good idea. If we can maintain some status of workers, we absolutely use Jump Consistent Hash.
Memento hashing (2023)
This algorithm also needs to save info on the previously moved workers, and it also should save info on replacing workers. The problem is similar to Dx Hash.
Hash Algorithm in Other Distributed Systems
We have conducted a survey about mainstream surveys.
AWS S3 Dynamo
For the classic ring hashing algorithm, AWS has proposed some improvements for it:
- Every real node should correspond to some virtual node.
- The hash ring is divided into Q parts, and the Q should be much larger than node_num * virtual_num.
- When a node is removed, its virtual node should be transferred to other nodes, or all virtual nodes should be redistributed.
It is similar to ring hashing with virtual nodes, which is used by Alluxio now.
Memcached and Nginx
This one uses the Ketama hashing algorithm. It is also a hashing ring with virtual nodes. Not much different from AWS S3 Dynamo.
Ceph CRUSH
When a pg will be stored in Ceph, it will determine which osd to store this pg. Inside the CRUSH algorithm, it is a lottery algorithm called straw2. The process of drawing lots is a pseudo-random process.
It is similar to Rendezvous hashing or multi-probe hashing, which is slower and worse than another hash algorithm in Alluxio.
Hadoop
It manages metadata through a consistent hash algorithm. They use hash ring with virtual nodes.
Google Network Load Balancer
It uses maglev hashing to balance network load.
Conclusion
In summary, we evaluated several popular consistent hashing algorithms used in Alluxio’s distributed file system. The original consistent hashing method used in Alluxio has drawbacks like slow performance and poor load balancing.
After analysis and experimentation, we found the Ketama hashing algorithm provides better efficiency and load balancing compared to the original algorithm. However, it still lacks strict consistency when nodes change.
The Maglev consistent hashing algorithm seems to be the best choice for Alluxio. It provides fast query performance, good load balancing, and strict consistency. The trade-off is higher memory usage for the lookup table.
Overall, Maglev consistent hashing appears optimal for Alluxio’s distributed architecture. It meets the goals of efficiency, load balancing, and strict consistency when scaling the worker nodes. Our testing validates Maglev can significantly improve on Alluxio’s original consistent hashing approach.
References
- Consistent hashing:
- Distributed hash table: https://en.wikipedia.org/wiki/Distributed_hash_table
- Ring hashing: https://www.cs.princeton.edu/courses/archive/fall09/cos518/papers/chash.pdf
- Rendezvous hashing: https://en.wikipedia.org/wiki/Rendezvous_hashing
- Multi-probe hashing: https://arxiv.org/pdf/1505.00062.pdf
- Jump Consistent Hashing: https://arxiv.org/pdf/1406.2294.pdf
- Maglev hashing:
- Anchor hashing: https://arxiv.org/pdf/1812.09674.pdf
- Dx hashing: https://arxiv.org/pdf/2107.07930.pdf
- MementoHash: https://arxiv.org/pdf/2306.09783.pdf
- AWS S3 Dynamo hashing: https://en.wikipedia.org/wiki/Dynamo_(storage_system)
- HDFS distributed metadata management: https://www.ijsrp.org/research-paper-0513/ijsrp-p1770.pdf
- Ceph CRUSH: https://zhuanlan.zhihu.com/p/556129088?utm_id=0