Abstract
China Unicom is one of the five largest telecom operators in the world. China Unicom’s booming business in 4G and 5G networks has to serve an exploding base of hundreds of millions of smartphone users. This unprecedented growth brought enormous challenges and new requirements to the data processing infrastructure. The previous generation of its data processing system was based on IBM midrange computers, Oracle databases, and EMC storage devices.
This architecture could not scale to process the amounts of data generated by the rapidly expanding number of mobile users. Even after deploying Hadoop and Greenplum database, it was still difficult to cover critical business scenarios with their varying massive data processing requirements. The complicated the architecture of its incumbent computing platform created a lot of new challenges to effectively use resources. Fortunately there is a new generation of distributed computation frameworks that can help China Unicom meet the enormous data challenges for a variety of business scenarios.
To solve these problems, the company built a new software stack of Apache Spark, Alluxio, HDFS, Hive and Apache Kafka. They used Alluxio as the core component for a unified, memory-centric distributed data processing platform with consolidated resources, and improved computation efficiency.
System Architecture
The new system architecture based on Alluxio is shown in Figure 1.
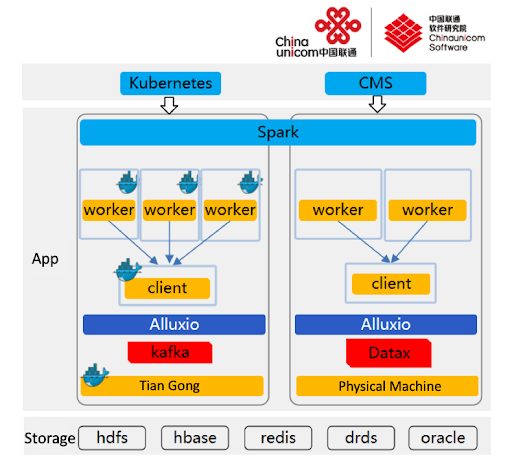
Here is how the architecture works. Based on the workloads and performance requirements of the service, the platform provides batch processing services using independent physical machine clusters, and provides stream processing services using Unicom’s containerized platform “Tian Gong” – a highly customized version of Mesosphere DC/OS.
The raw data of the services carried by the batch service is primarily stored in Oracle and DRDS (Distributed Relational Database System). After the data is extracted to the batch cluster through the data exchange center, ETL is used for HTL (HTML Template Language) and finally stored in Alluxio. The general processing flow of the batch business operation includes: reading the parquet file in Alluxio to register as a Spark temporary table, then running the SQL statement, and writing the intermediate result and the final result back to Alluxio. After the task is completed, the resulting data is backed up to Hive, and finally the result is sent to the downstream processing system.
The raw data of the services carried by the stream processing service is stored in Kafka. After the data is consumed by the stream processing task, it uses Alluxio to store checkpoints, which are then written into Redis and HBase. Due to differences in the Kafka version used by the service side, the task uses two stream computing processing engines: Spark Streaming (DStream) and Structured Streaming.
The Role of Alluxio
Alluxio is an open source distributed file system with a memory-centric architecture from UC Berkeley AMPLab. A key role that Alluxio plays in Unicom’s new platform is the unification of data provided by the unified namespace feature. Most of the raw data used by batch tasks comes from the Oracle and DRDS databases on the business side. Some special services have independent storage clusters — the raw data of these services is stored in HDFS in an independent cluster. Users need a uniform access point to avoid sharing data in the cluster using time-consuming and expensive data extraction and replication.
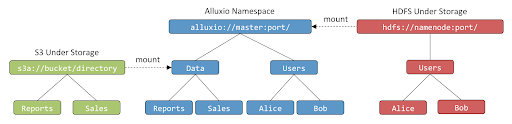
Alluxio has a unified namespace feature that supports mounting HDFS paths of different clusters. Users can directly read and write data stored in the local cluster through Alluxio. The transparent naming mechanism of the Alluxio unified namespace eliminates potential barriers for users to use this feature.
A schematic diagram of the Alluxio unified namespace is shown in Figure 3-1:
Improve data read and write speed
Spark usually takes a lot of time to read and write data from Hive. After the ETL, there are many small files in the Hive table, and the distribution is uneven. In this scenario, Spark directly reads data from Hive for correlation calculation, which tends to cause data skew, reduce computation speed, and increase failure rates. In our experiments, we exported data files of 100 gigabytes or more from Spark to Hive, but it was very slow. It took an average of 30 minutes for a service side to export the calculation result of a terabyte of data to Hive.
After taking advantage of Alluxio, it took an average of 4 minutes to export the resulting data to Alluxio, which is 7.5 times faster, greatly improving the performance of the resulting data.
The following table shows the data read performance improvement brought by Alluxio by taking the average performance of 40G data read and write HDFS as an example:
Table 3-1 Alluxio data read performance improvement display table
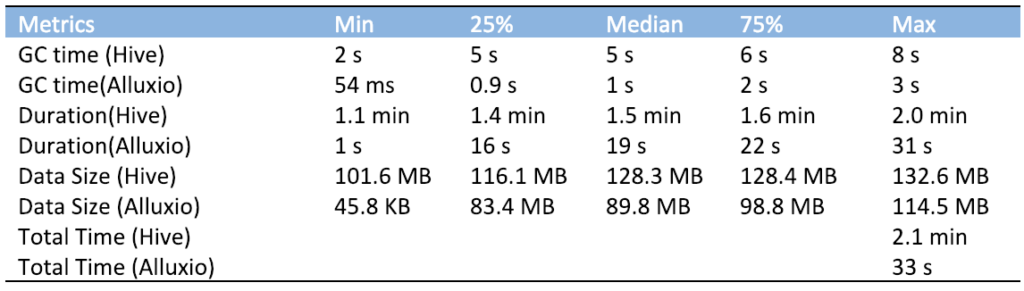
As shown in the above table, Alluxio improves data read speed, reduces calculation time, and greatly improves the data read performance of the system.
Accelerate queries
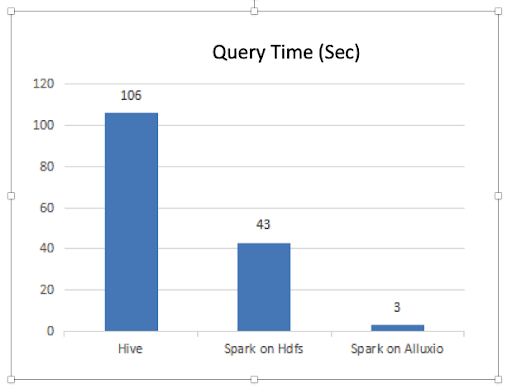
The services carried by the platform include report type services. This business is characterized by multiple queries at a time. The number of copies of data in Alluxio increases with the frequency of data access and is as close as possible to the physical location of the compute nodes, improving data read performance. As shown in the following figure, Alluxio can effectively improve the performance of frequently queried report-type services.
Improve system stability
Alluxio storage can significantly improve Spark’s task of handling small files with more stability when reading and writing large amounts of data, greatly reducing the possibility of read failure. Since the data skew caused by the associated calculations cannot be avoided, intermediate results often produce large numbers of small files of around 1000 kilobytes. These small files are mixed in a large file of about 100 megabytes, reading the data directly from HDFS to participate in subsequent association calculations that can often cause the Spark task to fail.
Storing these intermediate results in Alluxio greatly reduces the probability of failure of Spark tasks. In our application scenario, the average number of failed Spark tasks in each service cycle can be reduced to less than 1 by using Alluxio storage, thus ensuring the stability of task execution.
Business Operations
This new data analytics platform currently supports seven critical lines of business services related to Unicom’s billing and reporting. The cluster size reaches 112 nodes, and the average daily use of Alluxio memory is stable at around 3 terabytes, running more than 200,000 Spark Jobs and serving hundreds of millions of users. Unicom plans to further expand the use cases and deployments on this new platform.
Recommendations for Future Work
- Alluxio unified namespaces can cover Oracle and DRDS Simplifying raw data pull is one of the important ways to improve efficiency. Alluxio’s significant improvement in computing performance, corresponding to the pre-computation data preparation work, has become a major part of increasing overall performance and efficiency of our new platform.
- Spark Table support based on Alluxio Spark platform users include a large number of business engineers. Mapping the Alluxio-stored parquet files to database tables will provide direct support for SQL operations with Alluxio data files, reducing the technical burden on business engineers freeing more of their time to focus on the business itself.
About the author: Zhang Ce joined the Spark project team of China Unicom Software Research Institute in May 2017. He works as a Spark R&D engineer, responsible for the operation and optimization of Spark, Alluxio and other related systems as well as research and development of self-developed systems.